
テキストを解析する方法
公開: 2022-10-15
いくつかのコンピューター プログラミング言語を学んだことがあれば、テキストの解析という用語を聞いたことがあるかもしれません。 これは、ファイルの複雑なデータ値を単純化するために使用されます。 この記事は、言語を使用してテキストを解析する方法を理解するのに役立ちます。 これに加えて、テキスト x の解析でエラーが発生した場合は、この記事で解析エラーを修正する方法がわかります。
コンテンツ
- テキストを解析する方法
- テキストの解析とは
- NLP または自然言語処理
- テキストの解析とは
- テキストを解析する理由は何ですか?
- 方法 1: DataFrame クラスを介して
- 方法 2: 単語のトークン化による
- 方法 3: DocParser クラスを使用する
- 方法 4: テキスト解析ツールを使用する
- 方法 5: TextFieldParser を使用する (Visual Basic)
- プロのヒント: MS Excel でテキストを解析する方法
- 解析エラーを修正する方法
テキストを解析する方法
この記事では、さまざまな方法でテキストを解析するための完全なガイドを示し、テキストの解析について簡単に紹介しました。
テキストの解析とは
コードを使用してテキストを解析する概念を学ぶ前に。 言語とコーディングの基本について知ることが重要です。
NLP または自然言語処理
テキストを解析するには、人工知能ドメインのサブフィールドである自然言語処理または NLP が利用されます。 カテゴリに属する言語の 1 つである Python 言語は、テキストの解析に使用されます。
NLP コードにより、コンピューターは人間の言語を理解して処理し、さまざまなアプリケーションに適したものにすることができます。 ML または機械学習の手法を言語に適用するには、非構造化テキスト データを構造化表形式データに変換する必要があります。 解析作業を完了するために、Python 言語を使用してプログラム コードを変更します。
テキストの解析とは
テキストの解析とは、単にデータをある形式から別の形式に変換することを意味します。 ファイルが保存される形式は、ユーザーがさまざまなアプリケーションで使用できるように、別の形式のファイルに解析または変換されます。
- つまり、このプロセスは、文字列またはテキストを分析し、ファイルの形式を変更して論理コンポーネントに変換することを意味します。
- この一般的なプログラミング タスクを完了するために、Python 言語のいくつかの規則が利用されます。 テキストの解析中に、指定された一連のテキストが小さなコンポーネントに分割されます。
テキストを解析する理由は何ですか?
このセクションでは、テキストを解析する必要がある理由について説明します。これは、テキストを解析する方法を知る前に必要な知識です。
- すべてのコンピュータ化されたデータは同じ形式ではなく、さまざまなアプリケーションによって異なる場合があります。
- データ形式はさまざまなアプリケーションで異なり、互換性のないコードはこのエラーにつながります。
- すべてのデータ形式のデータを選択するための個別のユニバーサル コンピュータ プログラムはありません。
方法 1: DataFrame クラスを介して
Python 言語の DataFrame クラスには、テキストを解析するために必要なすべての関数があります。 この組み込みライブラリには、任意の形式のデータを別の形式に解析するために必要なコードが含まれています。
DataFrame クラスの簡単な紹介
DataFrame クラスは、データ分析ツールとして使用される機能豊富なデータ構造です。 これは、最小限の労力でデータを分析するために使用できる強力なデータ分析ツールです。
- コードは pandas DataFrame に読み込まれ、Python 言語で分析が実行されます。
- クラスには、Python データ アナリストが使用する pandas によって提供される多数のパッケージが付属しています。
- このクラスの特徴は、NumPy ライブラリの抽象化 (関数の内部機能がユーザーから隠されているコード) です。 NumPy ライブラリは、配列を操作するためのコマンドと関数を含む Python ライブラリです。
- DataFrame クラスを使用して、複数の行インデックスと列インデックスを持つ 2 次元配列をレンダリングできます。 これらのインデックスは、多次元データの格納に役立つため、MultiIndex と呼ばれます。 これらは、解析エラーを修正する方法を知るために変更する必要があります。
Python 言語の pandas は、SQL またはデータベース スタイルの操作を完璧に実行して、解析テキスト x のエラーを回避するのに役立ちます。 また、CSV、MS Excel、JSON、HDF5、およびその他のデータ形式のファイルの分析に役立ついくつかの IO ツールも含まれています。
また読む:リクエストをプロキシしようとしているときに発生したエラーを修正する
DataFrame クラスを使用してテキストを解析するプロセス
テキストを解析する方法を知るには、このセクションで説明する DataFrame クラスを使用した標準プロセスを使用できます。
- 入力データのデータ形式を解読します。
- CSVやカンマ区切り値などのデータの出力データを決定します。
- list や dict などのプリミティブ データ型をコードに記述します。
注:空の DataFrame にコードを記述するのは、面倒で複雑な場合があります。 パンダでは、これらのデータ型から DataFrame クラスでデータを作成できます。 したがって、プリミティブ データ型のデータは、必要なデータ形式に簡単に解析できます。
- データ分析ツール pandas DataFrame を使用してデータを分析し、結果を出力します。
オプション I: 標準フォーマット
ここでは、CSV などの特定のデータ形式のファイルをフォーマットする標準的な方法について説明します。
- データ値を含むファイルを PC にローカルに保存します。 たとえば、ファイルにdata.txtという名前を付けることができます。
- 特定の名前で pandas にファイルをインポートし、データを別の変数にインポートします。 たとえば、言語のパンダは、指定されたコードでpdという名前にインポートされます。
- インポートには、入力ファイルの名前、関数、および入力ファイル形式の詳細を含む完全なコードが必要です。
注:ここでは、 resという名前の変数を使用して、 pdにインポートされた pandas を使用してファイルdata.txt内のデータの読み取り関数を実行します。 入力テキストのデータ形式はCSV形式で指定します。
- 指定されたファイル タイプを呼び出し、出力結果の解析済みテキストを分析します。 たとえば、コマンド ライン実行後のコマンドresは、解析されたテキストの出力に役立ちます。
上記で説明したプロセスのサンプル コードを以下に示します。これは、テキストの解析方法を理解するのに役立ちます。
パンダを pd としてインポート
res = pd.read_csv('data.txt')
解像度この場合、ファイルdata.txtに[1,2,3]などのデータ値を入力すると、解析されて1 2 3として表示されます。
オプション II: 文字列メソッド
コードに指定されたテキストに文字列または英字のみが含まれている場合、コンマやスペースなどの文字列内の特殊文字を使用して、テキストを分離および解析できます。 このプロセスは、一般的な内部文字列操作に似ています。 解析エラーを修正する方法を見つけるには、このオプションを使用してテキストを解析するプロセスに従う必要があります。以下で説明します。
- 文字列からデータが抽出され、テキストを区切るすべての特殊文字が記録されます。
たとえば、以下のコードでは、文字列my_string内の特殊文字 ' , ' および ' : ' が識別されます。 このプロセスは、解析テキスト x でのエラーを回避するために慎重に行う必要があります。
- 文字列内のテキストは、特殊文字の値と位置に基づいて個別に分割されます。
たとえば、文字列は、split コマンドを使用して識別された特殊文字に基づいてテキスト データ値に分割されます。
- 文字列のデータ値は、解析されたテキストとして単独で出力されます。 ここでは、 printステートメントを使用して、テキストの解析済みデータ値を出力しています。
上記で説明したプロセスのサンプルコードを以下に示します。
my_string = '名前: テクノロジー、コンピューター'
sfinal = [name.strip() for name in my_string.split(':')[1].split(',')]
print(“名前: {}”.format(sfinal))この場合、解析された文字列の結果は次のように表示されます。
名前: ['Tech', 'computer']
文字列テキストの使用中にテキストを解析する方法をより明確にし、理解するために、 forループが使用され、コードは次のように変更されます。
my_string = '名前: テクノロジー、コンピューター'
s1 = my_string.split(':')
s2 = s1[1]
s3 = s2.split(',')
s4 = [s3 の名前の name.strip()]
for idx, enumerate([s1, s2, s3, s4]) の項目:
print(“ステップ {}: {}”.format(idx, item)) 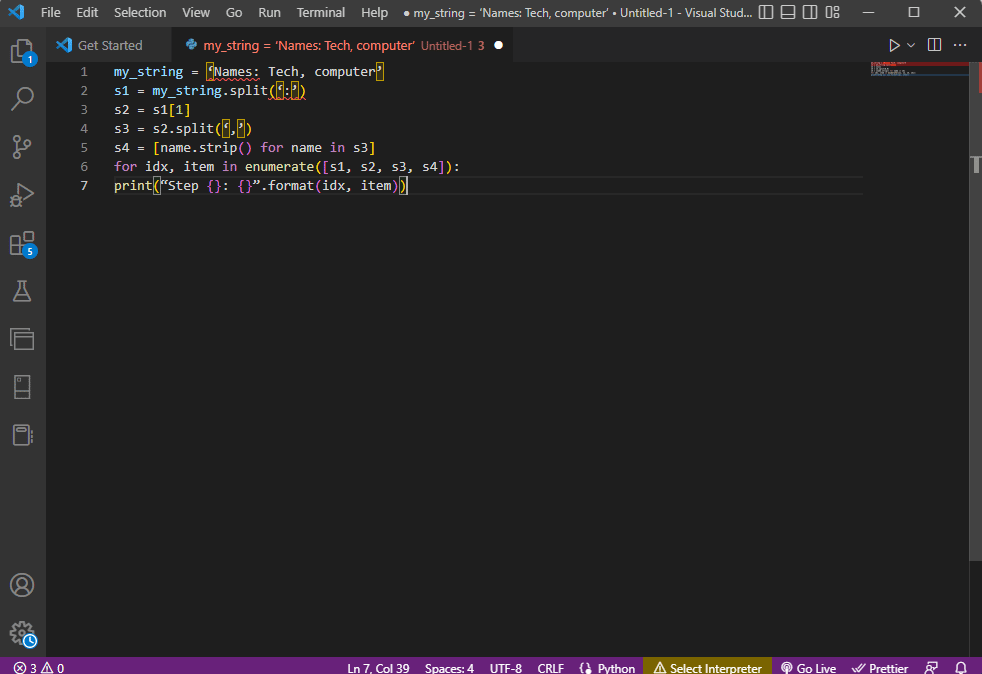
これらの各ステップで解析されたテキストの結果は、以下のように表示されます。 ステップ 0 で、文字列が特殊文字:に基づいて区切られ、テキスト データ値が次のステップで文字に基づいて区切られていることに注意してください。
ステップ 0: ['Names', 'Tech, computer'] ステップ 1: テクノロジー、コンピューター ステップ 2: [' Tech', ' computer'] ステップ 3: ['Tech', 'computer']
オプション III: 複雑なファイルの解析
ほとんどの場合、解析が必要なファイル データには、さまざまなデータ型とデータ値が含まれています。 この場合、前述の方法を使用してファイルを解析するのは難しい場合があります。
ファイル内の複雑なデータを解析する機能は、データ値を表形式で表示することです。
- 値のタイトルまたはメタデータは、ファイルの上部に出力されます。
- 変数とフィールドは、表形式で出力に出力されます。
- データ値は複合キーを形成します。
この方法でテキストを解析する方法を学習する前に、いくつかの基本的な概念を学習する必要があります。 データ値の解析は、正規表現または正規表現に基づいて行われます。
正規表現パターン
解析エラーを修正する方法を知るには、式の正規表現パターンが適切であることを確認する必要があります。 文字列のデータ値を解析するコードには、このセクションの下にリストされている一般的な正規表現パターンが含まれます。
- '\d' : 文字列の 10 進数に一致します。
- '\s' : 空白文字に一致します。
- '\w' : 英数字に一致し、
- '+'または'*' : 文字列内の 1 つ以上の文字に一致する貪欲な一致を実行します。
- 'a-z' : テキスト データ値の小文字グループに一致します。
- 'A-Z'または'a-z' :文字列の大文字と小文字のグループに一致し、
- '0-9' :数値に一致します。
正規表現
正規表現モジュールは、Python 言語の pandas パッケージの主要部分であり、re が間違っていると、テキスト x の解析でエラーが発生する可能性があります。 これは、式の文字列パターンを見つけるために Python に組み込まれた小さな言語です。 正規表現または正規表現は、特別な構文を持つ文字列です。 ユーザーは、文字列の値に基づいて、他の文字列のパターンを照合できます。
正規表現は、データ型と文字列内の式の要件('String = (.*)\nなど) に基づいて作成されます。 正規表現は、すべての式でパターンの前に使用されます。 正規表現で使用される記号は以下にリストされており、テキストの解析方法を知るのに役立ちます。
- . : データから任意の文字を取得するには、
- * : 前の式から 0 個以上のデータを使用します。
- (.*) : 括弧内の正規表現の一部をグループ化するには、
- \n : コードの行末に改行文字を作成し、
- \d : 0 から 9 の範囲で短い整数値を作成します。
- + : 前の式の 1 つ以上のデータを使用し、
- | | : 論理ステートメントを作成します。 または式に使用されます。
正規表現オブジェクト
RegexObject は compile 関数の戻り値であり、式が一致値と一致する場合に MatchObject を返すために使用されます。
1.MatchObject
MatchObject のブール値は常に True であるため、 ifステートメントを使用して、オブジェクト内の正の一致を識別できます。 ifステートメントを使用する場合、インデックスによって参照されるグループは、式内のオブジェクトの一致を見つけるために使用されます。
- group()は、一致する 1 つ以上のサブグループを返します。
- group(0)は一致全体を返します。
- group(1)は、括弧で囲まれた最初のサブグループを返します。
- 複数のグループを参照するときは、python 固有の拡張機能を使用する必要があります。 この拡張子は、一致するグループの名前を指定するために使用されます。 特定の拡張子は、括弧で囲まれたグループ内で提供されます。 たとえば、式(?P<group1>regex1)はgroup1という名前の特定のグループを参照し、正規表現regex1の一致をチェックします。 解析エラーを修正する方法を学ぶには、グループが正しく指されているかどうかを確認する必要があります。
2. MatchObject のメソッド
テキストを解析する方法を見つける際、MatchObject には以下に示す 2 つの基本的なメソッドがあることを知っておくことが重要です。 指定された式で MatchObject が見つかった場合、そのインスタンスが返されます。それ以外の場合は、None が返されます。
- match(string)メソッドは、正規表現の先頭にある文字列の一致を見つけるために使用されます。
- search(string)メソッドを使用して文字列をスキャンし、正規表現で一致する場所を見つけます。
正規表現関数
正規表現関数は、取得したデータ値のセットからユーザーが指定した特定の関数を実行するために使用されるコード行です。
注:関数を記述するには、正規表現に生の文字列を使用して、解析テキスト x のエラーを回避します。 これは、式の各パターンの前に添え字rを追加することによって行われます。
式で使用される一般的な関数を以下に説明します。
1. re.findall()
この関数は、一致が見つかった場合は文字列内のすべてのパターンを返し、一致が見つからなかった場合は空のリストを返します。 たとえば、関数string = re.findall('[aeiou]', regex_filename)を使用して、ファイル名に含まれる母音を見つけます。
2. re.split()
この関数は、スペースなどの指定された文字との一致が見つかった場合に、文字列を分割するために使用されます。 一致するものが見つからない場合は、空の文字列を返します。
3. re.sub()
この関数は、一致したテキストを、指定された置換変数の内容に置き換えます。 他の関数とは異なり、パターンが見つからない場合は元の文字列が返されます。
4.re.search()
テキストの解析方法を学習するのに役立つ基本的な機能の 1 つは、検索機能です。 文字列内のパターンを検索して一致オブジェクトを返すのに役立ちます。 検索で一致の識別に失敗した場合、値は返されません。
5. re.compile(パターン)
この関数は、前述の正規表現パターンを RegexObject にコンパイルするために使用されます。
その他の要件
リストされている要件は、上級プログラマーがデータ分析で使用する追加機能です。
- 正規表現を視覚化するには、 regexperを使用します。
- 正規表現をテストするには、 regex101を使用します。
また読む: Windows 10にNumPyをインストールする方法
テキストの解析プロセス
この複雑なオプションのテキストを解析する方法は、以下のように説明されています。
- 最初のステップは、ファイルの内容を読み取って入力形式を理解することです。 たとえば、 with openおよびread()関数を使用して、 sampleという名前のファイルの内容を開いて読み取ります。 サンプルファイルには、ファイルfile.txtの内容が含まれています。 解析エラーを修正する方法を学ぶには、ファイルを完全に読み取る必要があります。
- ファイルの内容は、データを手動で分析して値のメタデータを見つけるために出力されます。 ここでは、 print()関数を使用して、サンプルファイルの内容を印刷します。
- テキストを解析するために必要なデータ パッケージがコードにインポートされ、さらにコーディングするためにクラスに名前が付けられます。 ここでは、正規表現とパンダがインポートされます。
- コードに必要な正規表現は、正規表現パターンと正規表現関数を含めることによってファイルで定義されます。 これにより、テキスト オブジェクトまたはコーパスがデータ分析用のコードを取得できるようになります。
- テキストを解析する方法については、こちらのサンプル コードを参照してください。 compile()関数は、ファイルfilenameのグループstringname1から文字列をコンパイルするために使用されます。 正規表現の一致をチェックする関数は、コマンドief_parse_line(line)で使用されます。
- コードのライン パーサーは、 def_parse_file(filepath)を使用して記述されます。定義された関数は、指定された関数で一致するすべての正規表現をチェックします。 ここで、regex search()メソッドは、ファイルfilenameでキーrxを検索し、最初に一致した正規表現のキーと一致を返します。 ステップに問題があると、テキスト x の解析でエラーが発生する可能性があります。
- 次のステップは、 def_parse_file(filepath)であるファイル パーサー関数を使用してファイル パーサーを作成することです。 data = []としてコードのデータを収集するために空のリストが作成され、 match = _parse_line(line)によって各行で一致がチェックされ、データ型に基づいて正確な値のデータが返されます。
- テーブルの数値と値を抽出するには、コマンドline.strip().split(',')を使用します。 row{}コマンドは、データの行で辞書を作成するために使用されます。 data.append(row)コマンドは、データを理解し、それを解析して表形式にするために使用されます。
コマンドdata = pd.DataFrame(data)は、dict 値から pandas DataFrame を作成するために使用されます。 または、以下に示すように、それぞれの目的に次のコマンドを使用できます。

- data.set_index(['string', 'integer'], inplace=True)テーブルのインデックスを設定します。
- data = data.groupby(level=data.index.names).first()を統合してナンを削除します。
- data = data.apply(pd.to_numeric, errors='ignore')スコアを浮動小数点から整数値にアップグレードします。
テキストを解析する方法を理解するための最後のステップは、変数データに値を代入し、 print(data)コマンドを使用して出力することにより、 if ステートメントを使用してパーサーをテストすることです。
上記の説明のコード例をここに示します。
サンプルとして open('file.txt') を使用:
sample_contents = sample.read()
印刷(サンプル_内容)
再輸入
パンダを pd としてインポート
rx_filename = {
'string1': re.compile(r 'string = (?<P<stringname1>,*)\n'),
}
ief_parse_line(行):
キーの場合、rx_filename.items() の rx:
一致 = rx.search(行)
一致する場合:
リターンキー、マッチ
return なし、なし
def parse_file(ファイルパス):
データ = []
open(filepath, 'r') を file_object として使用:
行 = file_object.readline()
while 行:
キー、一致 = _parse_line(行)
キー == 'string1' の場合:
文字列 = match.group('string1')
整数 = int(string1)
value_type = match.group('string1')
行 = file_object.readline()
while line.strip():
数値、値 = line.strip().split(',')
値 = 値.strip()
行 = {
'データ 1': 文字列 1、
'Data2': 数値,
value_type: 値
}
data.append(行)
行 = file_object.readline()
行 = file_object.readline()
データ = pd.DataFrame(データ)
データを返す
if _ _name_ _ = = '_ _main_ _':
ファイルパス = 'sample.txt'
データ = パース (ファイルパス)
印刷(データ) 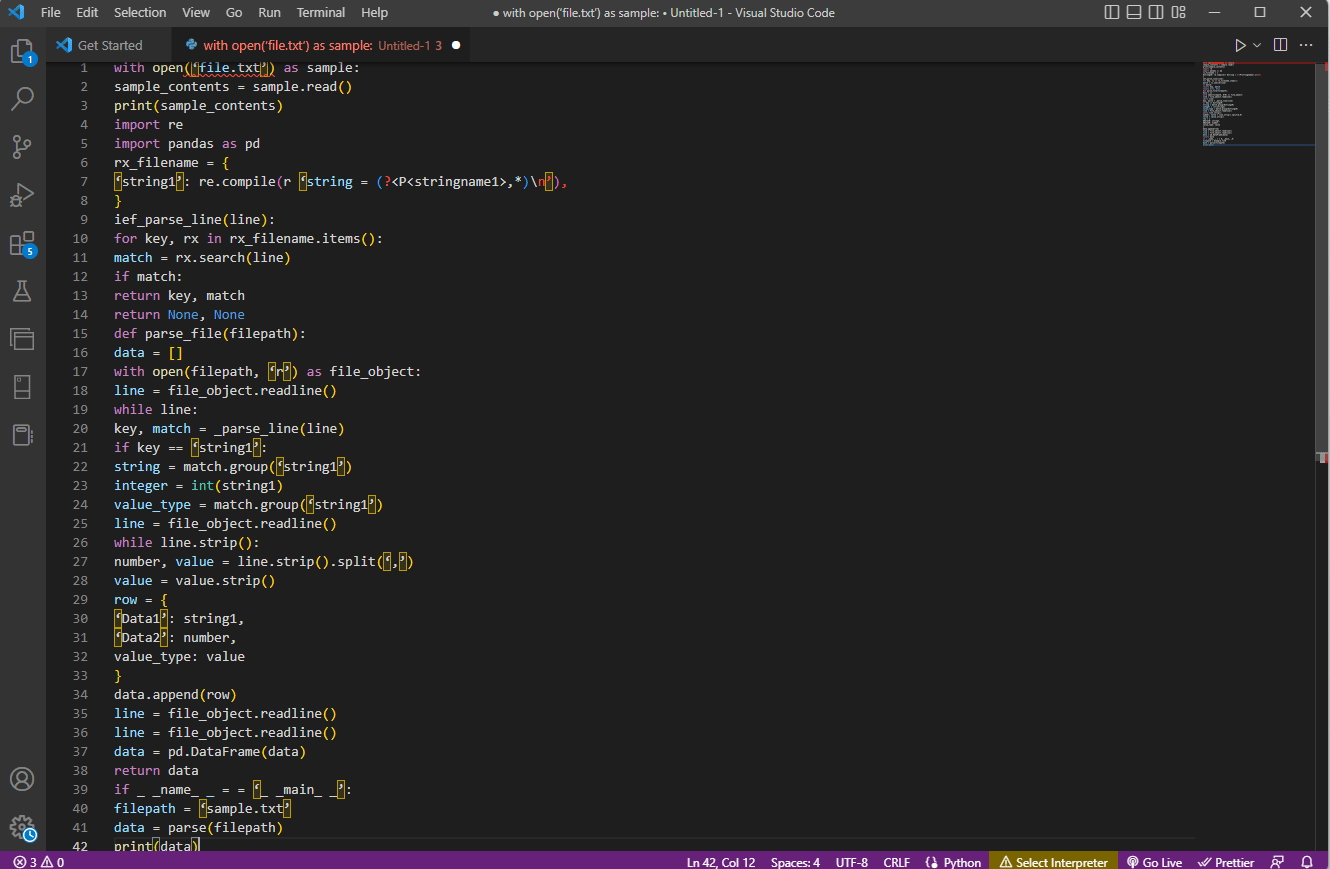
方法 2: 単語のトークン化による
特定のルールに基づいて、テキストまたはコーパスをトークンまたは小さな断片に変換するプロセスは、トークン化と呼ばれます。 解析エラーを修正する方法を学ぶには、コード内の単語トークン化コマンドを分析することが重要です。 正規表現と同様に、このメソッドでは独自のルールを作成でき、品詞のマッピングなどのテキスト前処理タスクに役立ちます。 また、一般的な単語の検索と照合、テキストのクリーニング、センチメント分析などの高度なテキスト分析手法用のデータの準備などのアクティビティも、このメソッドで実行されます。 トークン化が不適切な場合、解析テキスト x でエラーが発生する可能性があります。
Ntlk ライブラリ
このプロセスは、多くの NLP ジョブを実行するための豊富な関数セットを備えた、nltk と呼ばれる一般的な言語ツールキット ライブラリを利用します。 これらは、Pip または Pip Installs Packages からダウンロードできます。 テキストを解析する方法を知るには、デフォルトでライブラリを含む Anaconda ディストリビューションの基本パックを使用できます。
トークン化の形式
この方法の一般的な形式は、単語のトークン化と文のトークン化です。 単語レベルのトークンにより、前者は 1 つの単語を 1 回だけ出力しますが、後者は単語を文レベルで出力します。
テキストの解析プロセス
- ntlk ツールキット ライブラリがインポートされ、ライブラリからトークン化フォームがインポートされます。
- 文字列が与えられ、トークン化を実行するコマンドが与えられます。
- 文字列が出力される間、出力はcomputer is the word になります。
- 単語のトークン化またはword_tokenize()の場合、文の各単語は''内に個別に出力され、カンマで区切られます。 コマンドの出力は、 「computer」、「is」、「the」、「word」、「.」になります。
- 文のトークン化またはsent_tokenize()の場合、個々の文は''内に配置され、単語の繰り返しが許可されます。 コマンドの出力は「computer is the word.」になります。
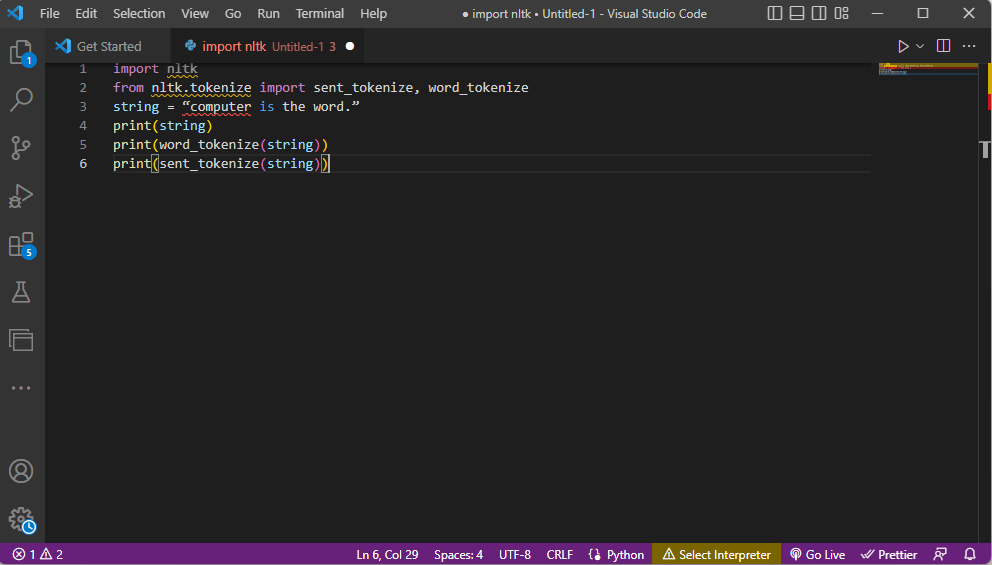
上記のトークン化の手順を説明するコードをここに示します。
輸入nltk from nltk.tokenize import sent_tokenize, word_tokenize string = 「コンピュータは単語です。」 印刷(文字列) print(word_tokenize(文字列)) print(sent_tokenize(文字列))
また読む: javascript:void(0) エラーを修正する方法
方法 3: DocParser クラスを使用する
DataFrame クラスと同様に、クラス DocParser を使用してコード内のテキストを解析できます。 このクラスを使用すると、ファイルパスを使用して解析関数を呼び出すことができます。
テキストの解析プロセス
DocParser クラスを使用してテキストを解析する方法を知るには、以下の手順に従ってください。
- get_format(filename)関数を使用してファイル拡張子を抽出し、それを関数のセット変数に戻し、次の関数に渡します。 たとえば、 p1 = get_format(filename)はfilenameのファイル拡張子を抽出し、それを変数p1に設定して、次の関数に渡します。
- 他の関数を持つ論理構造は、 if-elif-elseステートメントと関数を使用して構築されます。
- ファイル拡張子が有効で、構造が論理的である場合、 get_parser関数を使用してファイル パス内のデータを解析し、文字列オブジェクトをユーザーに返します。
注:解析エラーを修正する方法を知るには、この関数を正しく実装する必要があります。
- データ値の解析は、ファイルのファイル拡張子を使用して行われます。 parse_txtまたはparse_docxであるクラスの具体的な実装は、指定されたファイル タイプの部分から文字列オブジェクトを生成するために使用されます。
- 解析は、 parse_pdf 、 parse_html 、 parse_pptxなど、他の読み取り可能な拡張子のファイルに対して実行できます。
- データ値とインターフェイスは、import ステートメントを使用してアプリケーションにインポートし、DocParser オブジェクトをインスタンス化できます。 これは、 parse_file.pyなどの Python 言語でファイルを解析することで実行できます。 この操作は、解析テキスト x でのエラーを回避するために慎重に行う必要があります。
方法 4: テキスト解析ツールを使用する
テキストの解析ツールは、変数から特定のデータを抽出し、それらを他の変数にマップするために使用されます。 これは、タスクで使用される他のツールから独立しており、BPA プラットフォーム ツールを使用して変数を使用および出力します。 ここにあるリンクを使用してテキスト解析ツールにオンラインでアクセスし、テキストの解析方法に関する前述の回答を使用してください。
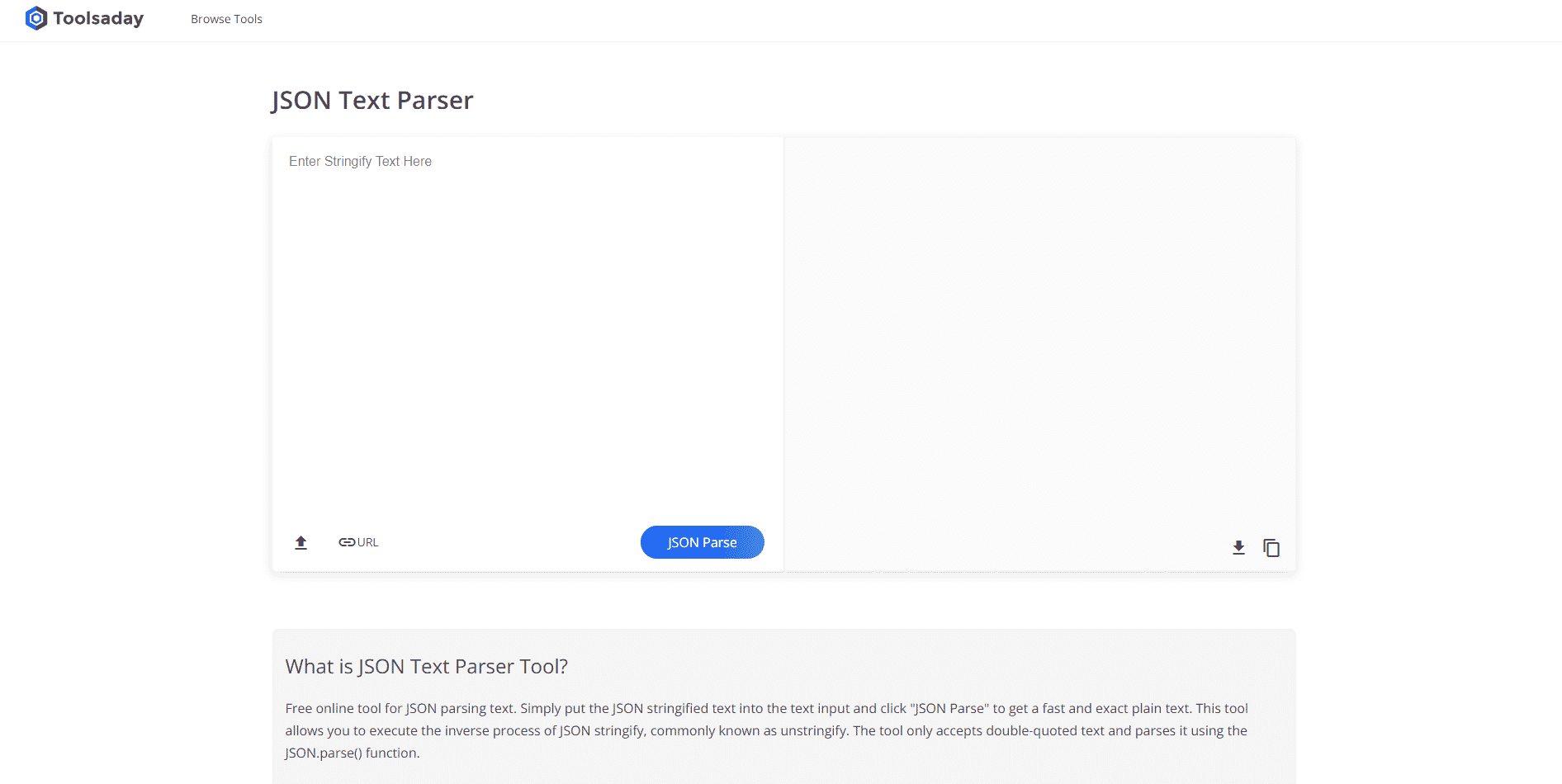
方法 5: TextFieldParser を使用する (Visual Basic)
TextFieldParser はオブジェクトを利用して、構造化され、区切られた非常に大きなファイルを解析および処理しました。 この方法では、ログ ファイルやレガシー データベース情報などのテキストの幅と列を使用できます。 解析方法は、テキスト ファイルに対してコードを反復処理することに似ており、主に、文字列操作方法と同様にテキストのフィールドを抽出するために使用されます。 これは、コンマやタブ スペースなどの定義済みの区切り文字を使用して、さまざまな幅の区切り文字列とフィールドをトークン化するために行われます。
テキストを解析する関数
次の関数を使用して、このメソッドのテキストを解析できます。
- 区切り文字を定義するには、 SetDelimitersを使用します。 たとえば、コマンドtestReader.SetDelimiters (vbTab)は、区切り文字としてタブスペースを設定するために使用されます。
- フィールド幅をテキスト ファイルの固定フィールド幅に正の整数値に設定するには、 testReader.SetFieldWidths (整数)コマンドを使用できます。
- テキストのフィールド タイプをテストするには、次のコマンドtestReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidthを使用できます。
MatchObject を検索するメソッド
コードまたは解析されたテキストで MatchObject を見つけるには、2 つの基本的な方法があります。
- 最初の方法は、形式を定義し、 ReadFieldsメソッドを使用してファイルをループすることです。 このメソッドは、コードの各行を処理するのに役立ちます。
- PeekCharsメソッドは、各フィールドを読み取る前に個別にチェックし、複数の形式を定義して対応するために使用されます。
どちらの場合でも、解析の実行中またはテキストの解析方法の検索中にフィールドが指定された形式と一致しない場合、 MalformedLineException例外が返されます。
プロのヒント: MS Excel でテキストを解析する方法
テキストを解析する最後の簡単な方法として、MS Excel アプリをパーサーとして使用して、タブ区切りおよびカンマ区切りのファイルを作成できます。 これは、解析結果とのクロスチェックに役立ち、解析エラーを修正する方法を見つけるのに役立ちます。
1. ソース ファイルのデータ値を選択し、 Ctrl + C キーを同時に押してファイルをコピーします。
2. Windows 検索バーを使用してExcelアプリを開きます。
3. A1セルをクリックし、 Ctrl + V キーを同時に押して、コピーしたテキストを貼り付けます。
4. A1セルを選択し、[データ] タブに移動して、[データ ツール] セクションの [列へのテキスト] オプションをクリックします。
![[データ] タブに移動し、[列へのテキスト] オプションをクリックします。](/uploads/article/6096/yQEpDtzlGCkaK53N.png)
5A。 コンマまたはタブスペースを区切り文字として使用する場合は、[区切り]オプションを選択し、[次へ] および [完了] ボタンをクリックします。
![コンマまたはタブ スペースを区切り文字として使用する場合は、[区切り] オプションを選択し、[次へ] および [完了] ボタンをクリックします。](/uploads/article/6096/2gpcukR65Kh8u6Zq.png)
5B. [固定幅] オプションを選択し、区切り記号の値を割り当てて、[次へ] および [完了] ボタンをクリックします。
![[固定幅] オプションを選択してセパレータに値を割り当て、[次へ] および [完了] ボタンをクリックします。](/uploads/article/6096/AfR9KGHl3lyCyVm8.png)
また読む: Excel列の移動エラーを修正する方法
解析エラーを修正する方法
Android デバイスでは、解析テキスト x でエラーが発生する可能性があります。解析エラー: パッケージの解析中に問題が発生しました。 これは通常、Google Play ストアからのアプリのインストールに失敗した場合、またはサードパーティ アプリの実行中に発生します。
エラー テキスト x は、文字ベクトルのリストがループされ、他の関数がデータ値を計算するための線形モデルを形成する場合に発生する可能性があります。 エラー メッセージは Error in parse(text = x, keep.source = FALSE):<text>:2.0:unexpected end of input 1:OffenceAgainst ~ ^ です。
Android で解析エラーを修正する方法に関する記事を読んで、エラーの原因と修正方法を確認できます。
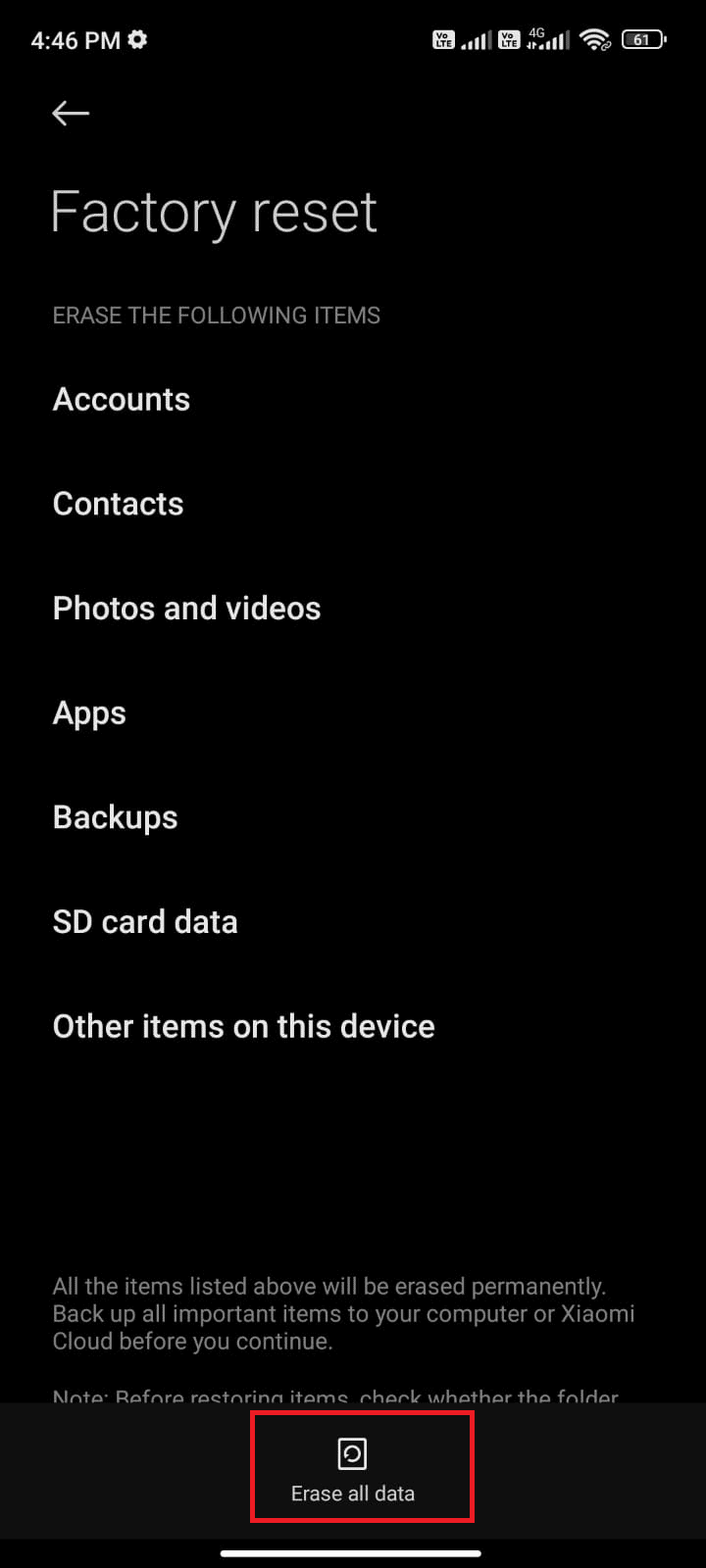
ガイドの解決策とは別に、次の修正を試すことができます。
- .apkファイルを再ダウンロードするか、ファイルの名前を復元します。
- エキスパート レベルのプログラミング スキルがある場合は、 Androidmanifest.xmlファイルの変更を復元します。
おすすめされた:
- 他の人のFacebookアカウントを削除する方法
- 倫理的なハッカーになるために必要な上位 10 のスキル
- コードとテキストを共有するための 21 の最適な Pastebin の代替手段
- 修正コマンドがエラー コード 1 Python Egg Info で失敗しました
この記事は、テキストを解析する方法を教え、解析エラーを修正する方法を学ぶのに役立ちます。 テキスト x の解析でエラーを修正するのにどの方法が役立ち、どの解析方法が優先されるかをお知らせください。 以下のコメントセクションで提案や質問を共有してください。