
Linux でバイナリ ファイルを比較する方法
公開: 2022-08-20
2 つの Linux バイナリが同じかどうかを確認するにはどうすればよいですか? それらが実行可能ファイルである場合、違いは望ましくない、または悪意のある動作を意味する可能性があります。 それらが異なるかどうかを確認する最も簡単な方法は次のとおりです。
バイナリ ファイルの比較
Linux には、テキスト ファイルを比較および分析する方法が豊富に用意されています。 diffコマンドは 2 つのファイルを比較し、相違点を強調表示します。 変更された行の前後にいくつかのコンテキストを提供するために、変更の両側に数行を提供することもできます。 また、 colordiffコマンドは色を追加して、違いを視覚的に解析しやすくします。
開発者と作成者はdiffを使用して、異なるバージョンのプログラム ソース コード ファイルまたはドラフト テキストの違いを強調します。 迅速かつ簡単で、テキストの文字列間の違いを確認するための技術的なスキルは必要ありません。
バイナリ ファイルの世界では、物事はそれほど単純ではありません。 バイナリ ファイルはプレーン テキストで構成されていません。 それらは、数値を含む多くのバイトで構成されています。 TAR アーカイブや ZIP ファイルなどの圧縮ファイルの場合、これらの値は、ファイルの解凍と抽出に必要なシンボルのテーブルと共に、アーカイブ ファイル内に保存されている圧縮ファイルを表します。

バイナリ ファイルが実行可能ファイルの場合、ファイルのバイトの数値は、CPU、メタデータ、ラベル、またはエンコードされたデータのマシン コード命令などとして解釈されます。 バイナリ ファイルまたはライブラリ ファイルへの変更は、バイナリが実行されるとき、または別のアプリケーションによって使用されるときの動作の違いにつながる可能性があります。
ファイルの作成日時や変更日時を偽装するのは簡単です。 つまり、同じ名前、ファイル サイズ (変更によって既存のコンテンツがバイトごとに置き換えられた場合)、および日付スタンプが同じファイルの 2 つのバージョンが存在する可能性があります。 それでも、ファイルの 1 つが変更されている可能性があります。
安全なハッシュ アルゴリズム
安全なハッシュ アルゴリズムは、数学ベースのアルゴリズムです。 ファイル内のすべてのバイトをスキャンし、それらに数学的変換を適用してハッシュ値を生成することにより、64 ビット値を作成します。 いつでも、同じファイルは常に同じハッシュを生成します。 1 バイトの違いでも、根本的に異なるハッシュになります。
ダウンロード ページにファイルのハッシュが表示されることがよくあります。 ファイルをダウンロードしたら、ファイルのハッシュを生成する必要があります。 Web ページに表示されているハッシュと異なる場合は、ファイルが侵害されていることがわかります。 改ざんされて本物のファイルに置き換えられた (汚染されたファイルをダウンロードするように仕向けられた) か、転送中に破損したかのいずれかです。
テスト コンピューターには、同じファイル (共有ライブラリ) の 2 つのコピーがあります。 ファイルは、同じディレクトリに配置できるように名前が変更されています。 理論的には、これらのファイルは同じでなければなりません。 結局のところ、それらは共有ライブラリの同じバージョンであるはずです。
ls -l *.so

ファイルのサイズ、日付スタンプ、タイム スタンプは同じです。 普通の観察者には、それらは同じように見えます。 sha256sumコマンドを使用して、各ファイルのハッシュを生成してみましょう。
sha256sum binary_file1.so
sha256sum binary_file2.so
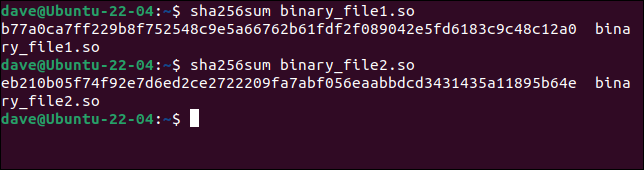
ハッシュは完全に異なり、2 つのファイルに違いがあることを明確に示しています。 Web サイトに本物のファイルのハッシュが表示されている場合は、一致しないファイルを破棄できます。
違いを見つける
変更を確認したい場合は、それを行う方法もあります。 ファイルを逆コンパイルできる必要はなく、変更を確認するためだけにアセンブリやマシン コードを理解する必要もありません。 もちろん、これらの変更が何を意味し、その目的が何であるかを理解するには、より深い技術的知識が必要です。 しかし、変更がどれほど重要であるかを知るだけで、ファイルに何が起こったのかがわかります。
2 つのバイナリ ファイルに対してdiffを使用すると、少し物足りない応答が得られます。
diff binary_file1.so binary_file2.so

ファイルが異なることはすでにわかっていました。 cmpを試してみましょう。
cmp binary_file1.so binary_file2.so

これは、もう少し多くのことを教えてくれます。 2 つのファイル間で異なる最初のバイトは、バイト番号 13451 です。つまり、バイナリ ファイルの先頭から数えて、バイト 13451 が 2 つのバイナリ ファイルで異なります。 したがって、13451 は、ファイルの先頭からの最初の差分のオフセットです。
偶然にも、ファイル全体に 0x10 の 16 進値を含むバイトがあります。 これは、Linux がテキスト ファイルで行末文字として使用する値です。 cmpコマンドは、バイナリ ファイルの先頭から最初の相違点までの間に、この値を持つ 131 バイトを検出しました。 したがって、132 行目にあると考えられます。このコンテキストでは、実際には何の意味もありません。
-l (verbose) オプションを追加すると、有益な情報が得られるようになります。
cmp -l binary_file1.so binary_file2.so
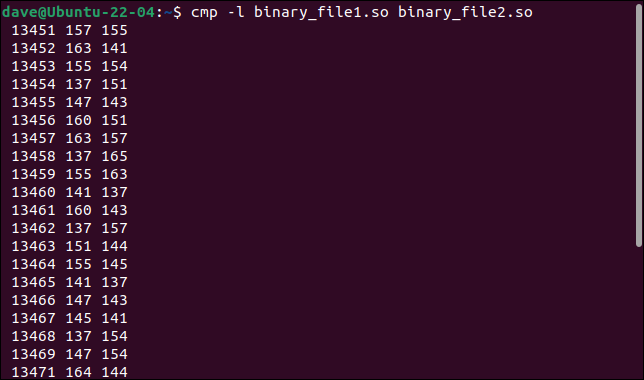
すべての異なるバイトがリストされます。 バイト番号またはオフセット、最初のファイルの値、および 2 番目のファイルの値が、出力の 1 行あたり 1 バイトで表示されます。

バイト値は、バイナリ ファイルで使用される通常の 16 進数形式ではなく、8 進数で表示されます。 それにもかかわらず、私たちは別のことを学びました。 変更されたすべてのバイトは、1 つの連続したシーケンスにあります。 それらのオフセットは、バイトごとに 1 ずつ増加します。
hexdumpツールは、ターミナル ウィンドウにバイナリ ファイルをダンプします。 -C (標準) オプションを使用すると、出力は各行にオフセット、そのオフセットでの 16 バイトの値、およびバイト値の ASCII 表現 (存在する場合) をリストします。
hexdump -C binary_file1.so
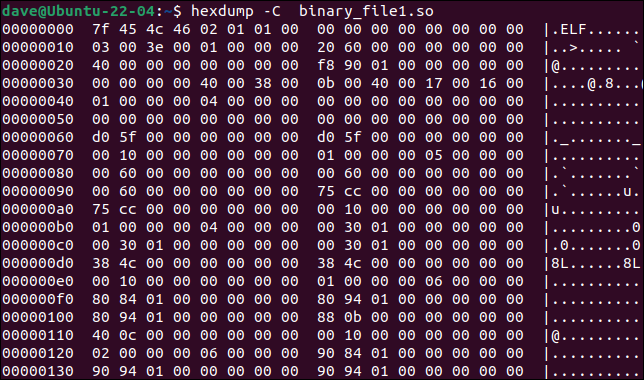
hexdumpからの出力をdiffへの入力として使用して、 diffを 2 つのテキスト ファイルを読み取っているかのように機能させることができます。
diff <(hexdump binary_file1.so) <(hexdump binary_file2.so)
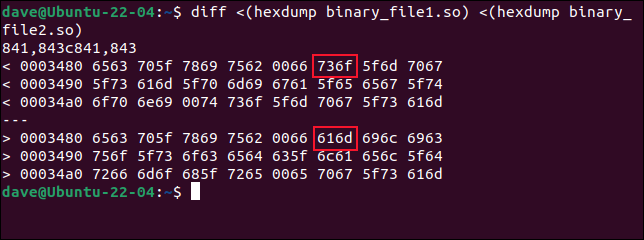
diffは異なる行を見つけ、最初のファイルの 16 進バイト値を 2 番目のファイルの値の上に表示します。 最初の行のオフセットは 0x3480、または 10 進数で 13440 です。 以前、 cmpは、最初の変更がバイト 13451、つまり 0x348B で発生したことを示しました。 それは実際にここで見られるものと一致します。
diffからの出力は 2 バイト ブロックです。 バイトの最初のペアは、オフセット 0x3480 からのバイト 0 と 1 であり、2 番目のブロックは、オフセットからのバイト 2 と 3 を保持します。 ブロック 6 は、バイト 0xA と 0xB、または 10 と 11 を 10 進数で保持します。 それらはバイト 13450 と 13451 です。そして、それらが異なる最初のバイトであることがわかります。 最初の 5 ペアのバイトは、両方のファイルで同じです。
ただし、 diffは基数ゼロから数えているため、 cmpが 13451 を呼び出すのは、バイト 13540 からdiffになります。 さらに混乱を招くのは、各 2 バイト ブロックのバイト順がdiffによって逆になっていることです。 バイトは実際には、1 と 0、3 と 2、5 と 4、7 と 6 などの順序でリストされます。
このコマンドは、特に比較対象のファイルが大きい場合に、2 つのhexdumpsとdiffを同時に実行するため、計算コストも高くなります。
しかし、 hexdump -Cでバイナリ ファイルの ASCII バージョンを端末ウィンドウに送信できる場合、出力をテキスト ファイルにリダイレクトしてから、それら 2 つのテキスト ファイルをdiffで比較してみませんか?
hexdump -C binary_file1.so > binary1.txt
hexdump -C binary_file2.so > binary2.txt
diff binary1.txt binary2.txt
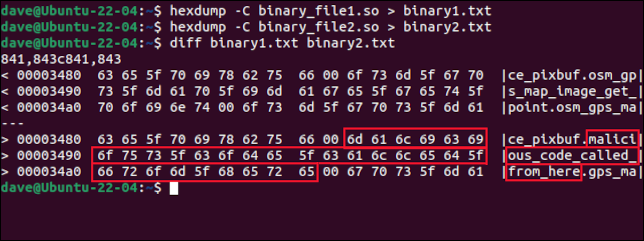
2 つのファイルの違いは、2 つの短い抜粋で表示されます。 それらの横に ASCII 表現があります。 ファイル間の違いごとに抽出のペアがあります。 この例では、違いは 1 つだけです。
それはとてもいいことですが、それをすべてやってくれるものがあれば素晴らしいと思いませんか?
VBinDiff
VBinDiff プログラムは、すべての主要なディストリビューションの通常のリポジトリからインストールできます。 Ubuntu にインストールするには、次のコマンドを使用します。
sudo apt install vbindiff

Fedora では、次のように入力する必要があります。
sudo dnf install vbindiff

Manjaro ユーザーはpacmanを使用する必要があります。
sudo pacman -Sy vbindiff

プログラムを使用するには、コマンド ラインで 2 つのバイナリ ファイルの名前を渡します。
vbindiff binary_file1.so binary_file2.so

端末ベースのアプリケーションが開き、両方のファイルがスクロール ビューに表示されます。
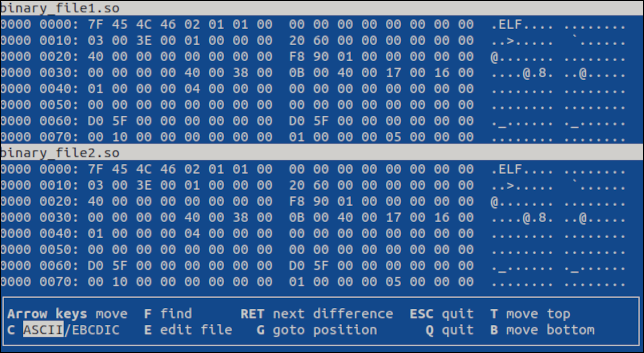
マウスのスクロール ホイールまたは「上矢印」、「下矢印」、「Home」、「End」、「PageUp」、および「PageDown」キーを使用して、ファイル間を移動できます。 両方のファイルがスクロールします。
「Enter」キーを押して、最初の相違点にジャンプします。 両方のファイルで違いが強調表示されます。
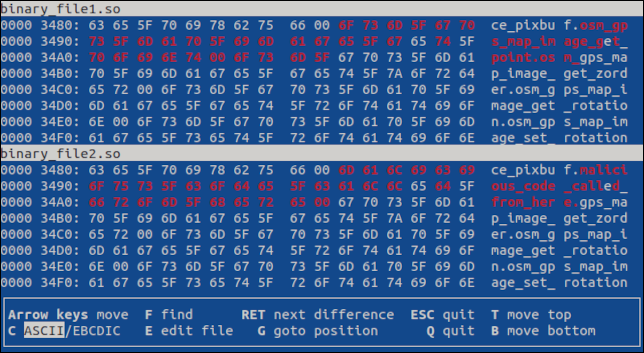
さらに違いがある場合は、「Enter」を押すと次の違いが表示されます。 「q」または「Esc」を押すと、プログラムが終了します。
違いは何ですか?
他人のコンピュータで作業していて、パッケージのインストールが許可されていない場合は、 cmp 、 diff 、およびhexdumpを使用できます。 さらに処理するために出力をキャプチャする必要がある場合は、これらのツールも使用できます。
ただし、パッケージのインストールが許可されている場合は、VBinDiff によってワークフローがより簡単かつ迅速になります。 実際、単一のバイナリ ファイルで VBinDiff を使用すると、バイナリ ファイルを参照するための簡単で便利な方法になります。これはうれしいボーナスです。
関連: Linux コマンド ラインからバイナリ ファイルの内部を覗く方法