
Che cos'è Swappiness su Linux? (e come cambiarlo)
Pubblicato: 2022-01-29
Il valore di swappiness di Linux non ha nulla a che fare con la quantità di RAM utilizzata prima dell'inizio dello scambio. Questo è un errore ampiamente riportato e ampiamente creduto. Spieghiamo cos'è veramente.
Sfatare i miti sulla Swapiness
Lo scambio è una tecnica in cui i dati nella memoria ad accesso casuale (RAM) vengono scritti in una posizione speciale sul disco rigido, una partizione di scambio o un file di scambio, per liberare RAM.
Linux ha un'impostazione chiamata valore swappiness. C'è molta confusione su cosa controlla questa impostazione. La descrizione errata più comune di swappiness è che imposta una soglia per l'utilizzo della RAM e quando la quantità di RAM utilizzata raggiunge tale soglia, lo scambio inizia.
Questo è un malinteso che è stato ripetuto così spesso che ora è diventato saggezza. Se (quasi) tutti gli altri ti dicono che è esattamente come funziona lo swappiness, perché dovresti crederci quando diciamo che non lo è?
Semplice. Lo dimostreremo.
La tua RAM è divisa in zone
Linux non pensa alla tua RAM come a un grande pool omogeneo di memoria. La ritiene suddivisa in un certo numero di diverse regioni denominate zone. Quali zone sono presenti sul tuo computer dipende dal fatto che sia a 32 o 64 bit. Ecco una descrizione semplificata delle possibili zone su un computer con architettura x86.
- Accesso diretto alla memoria (DMA) : questo è il basso 16 MB di memoria. La zona prende il nome perché, molto tempo fa, c'erano computer che potevano solo accedere direttamente alla memoria in quest'area della memoria fisica.
- Direct Memory Access 32 : Nonostante il nome, Direct Memory Access 32 (DMA32) è una zona che si trova solo in Linux a 64 bit. Sono i 4 GB di memoria bassi. Linux in esecuzione su computer a 32 bit può eseguire DMA solo su questa quantità di RAM (a meno che non utilizzino il kernel PAE (Physical Address Extension), ed è così che la zona ha preso il nome. Anche se, sui computer a 32 bit, si chiama HighMem.
- Normale : sui computer a 64 bit, la memoria normale è tutta la RAM superiore a 4 GB (circa). Su macchine a 32 bit, è RAM tra 16 MB e 896 MB.
- HighMem : esiste solo su computer Linux a 32 bit. È tutta RAM superiore a 896 MB, inclusa la RAM superiore a 4 GB su macchine sufficientemente grandi.
Il valore PAGESIZE
La RAM è allocata in pagine di dimensione fissa. Tale dimensione è determinata dal kernel al momento dell'avvio rilevando l'architettura del computer. In genere la dimensione della pagina su un computer Linux è di 4 Kbyte.
Puoi vedere le dimensioni della tua pagina usando il comando getconf :
getconf DIMENSIONE PAGINA

Le zone sono collegate ai nodi
Le zone sono collegate ai nodi. I nodi sono associati a una Central Processing Unit (CPU). Il kernel proverà ad allocare memoria per un processo in esecuzione su una CPU dal nodo associato a quella CPU.
Il concetto di nodi legati alle CPU consente l'installazione di tipi di memoria misti in computer specializzati multi-CPU, utilizzando l'architettura di accesso alla memoria non uniforme.
È tutto molto di fascia alta. Il computer Linux medio avrà un singolo nodo, chiamato nodo zero. Tutte le zone apparterranno a quel nodo. Per vedere i nodi e le zone nel tuo computer, guarda all'interno del file /proc/buddyinfo . Useremo less per farlo:
meno /proc/buddyinfo

Questo è l'output del computer a 64 bit su cui è stato studiato questo articolo:
Nodo 0, zona DMA 1 1 1 0 2 1 1 0 1 1 3 Nodo 0, zona DMA32 2 67 58 19 8 3 3 1 1 1 17
C'è un solo nodo, il nodo zero. Questo computer ha solo 2 GB di RAM, quindi non esiste una zona "normale". Ci sono solo due zone, DMA e DMA32.
Ogni colonna rappresenta il numero di pagine disponibili di una certa dimensione. Ad esempio, per la zona DMA32, leggendo da sinistra:
- 2 : Ci sono 2 blocchi di memoria su 2^( 0 *PAGESIZE).
- 67 : Ci sono 67 di 2^( 1 *PAGE_SIZE) blocchi di memoria.
- 58 : Sono disponibili 58 blocchi di memoria su 2^( 2 *PAGESIZE).
- E così via, fino a...
- 17 : Ci sono 17 blocchi di 2^( 512 *PAGESIZE).
Ma in realtà, l'unico motivo per cui stiamo guardando queste informazioni è vedere la relazione tra nodi e zone.
Pagine di file e Pagine anonime
La mappatura della memoria utilizza insiemi di voci della tabella delle pagine per registrare quali pagine di memoria vengono utilizzate e per cosa.
Le mappature della memoria possono essere:
- File supportati : i mapping supportati da file contengono dati che sono stati letti da un file. Può essere qualsiasi tipo di file. La cosa importante da notare è che se il sistema ha liberato questa memoria e ha bisogno di ottenere nuovamente quei dati, può essere letto ancora una volta dal file. Tuttavia, se i dati sono stati modificati in memoria, tali modifiche dovranno essere scritte nel file sul disco rigido prima che la memoria possa essere liberata. Se ciò non accadesse, le modifiche andrebbero perse.
- Anonimo : la memoria anonima è una mappatura della memoria senza file o dispositivo che la supporti. Queste pagine possono contenere memoria richiesta al volo dai programmi per contenere i dati o per cose come lo stack e l'heap. Poiché non esiste alcun file dietro questo tipo di dati, è necessario riservare un posto speciale per la memorizzazione di dati anonimi. Quel posto è la partizione di scambio o il file di scambio. I dati anonimi vengono scritti per lo scambio prima che le pagine anonime vengano liberate.
- Dispositivo supportato : i dispositivi vengono indirizzati tramite file di dispositivo a blocchi che possono essere trattati come se fossero file. I dati possono essere letti da loro e scritti su di loro. Una mappatura della memoria supportata da un dispositivo contiene dati da un dispositivo archiviati.
- Condivisa : più voci della tabella di pagina possono essere mappate alla stessa pagina di RAM. L'accesso alle posizioni di memoria tramite una qualsiasi delle mappature mostrerà gli stessi dati. Processi diversi possono comunicare tra loro in modo molto efficiente modificando i dati in queste posizioni di memoria controllate congiuntamente. Le mappature scrivibili condivise sono un mezzo comune per ottenere comunicazioni tra processi ad alte prestazioni.
- Copia in scrittura : la copia in scrittura è una tecnica di allocazione pigra. Se viene richiesta una copia di una risorsa già in memoria, la richiesta viene soddisfatta restituendo una mappatura alla risorsa originale. Se uno dei processi di "condivisione" della risorsa tenta di scrivervi, la risorsa deve essere realmente replicata in memoria per consentire di apportare le modifiche alla nuova copia. Quindi l'allocazione della memoria avviene solo al primo comando di scrittura.
Per swappiness, dobbiamo occuparci solo dei primi due dell'elenco: le pagine dei file e le pagine anonime.
Scambiabilità
Ecco la descrizione di swappiness dalla documentazione di Linux su GitHub:
"This control is used to define how aggressive (sic) the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60."
Sembra che lo swappiness aumenti o diminuisca l'intensità. È interessante notare che afferma che l'impostazione dello swappiness su zero non disattiva lo scambio. Indica al kernel di non scambiare finché non vengono soddisfatte determinate condizioni. Ma lo scambio può ancora verificarsi.
Scaviamo più a fondo. Ecco la definizione e il valore predefinito di vm_swappiness nel file del codice sorgente del kernel vmscan.c:
/*
* From 0 .. 100. Higher means more swappy.
*/
int vm_swappiness = 60;
Il valore di swappiness può variare da 0 a 100. Anche in questo caso, il commento suona sicuramente come se il valore di swappiness influisca sulla quantità di scambio che avviene, con una cifra più alta che porta a più scambi.
Più avanti nel file del codice sorgente, possiamo vedere che a una nuova variabile chiamata swappiness viene assegnato un valore che viene restituito dalla funzione mem_cgroup_swappiness() . Un'altra traccia del codice sorgente mostrerà che il valore restituito da questa funzione è vm_swappiness . Quindi ora, la variabile swappiness è impostata su qualsiasi valore impostato su vm_swappiness .
int swappiness = mem_cgroup_swappiness(memcg);
E un po' più in basso nello stesso file di codice sorgente, vediamo questo:
/*
* With swappiness at 100, anonymous and file have the same priority.
* This scanning priority is essentially the inverse of IO cost.
*/
anon_prio = swappiness;
file_prio = 200 - anon_prio;
Interessante. Due valori distinti sono derivati da swappiness . Le variabili anon_prio e file_prio contengono questi valori. All'aumentare di uno, l'altro diminuisce e viceversa .
Il valore di scambio di Linux in realtà imposta il rapporto tra due valori.
La sezione aurea
Le pagine dei file contengono dati che possono essere facilmente recuperati se quella memoria viene liberata. Linux può semplicemente leggere di nuovo il file. Come abbiamo visto, se i dati del file sono stati modificati nella RAM, tali modifiche devono essere scritte nel file prima che la pagina del file possa essere liberata. Ma, in entrambi i casi, la pagina del file nella RAM può essere ripopolata leggendo i dati dal file. Allora perché preoccuparsi di aggiungere queste pagine alla partizione di scambio o al file di scambio? Se hai bisogno di nuovo di quei dati, potresti anche rileggerli dal file originale invece di una copia ridondante nello spazio di scambio. Quindi le pagine dei file non vengono archiviate in swap. Sono "memorizzati" nel file originale.
Con le pagine anonime, non è presente alcun file sottostante associato ai valori in memoria. I valori in quelle pagine sono stati ottenuti dinamicamente. Non puoi semplicemente rileggerli da un file. L'unico modo in cui è possibile recuperare i valori di memoria di pagina anonimi è archiviare i dati da qualche parte prima di liberare la memoria. Ed è quello che vale lo scambio. Pagine anonime a cui dovrai fare nuovamente riferimento.
Ma nota che sia per le pagine di file che per le pagine anonime, liberare memoria potrebbe richiedere una scrittura su disco rigido. Se i dati della pagina del file oi dati della pagina anonima sono cambiati dall'ultima scrittura nel file o per lo scambio, è necessaria una scrittura del file system. Per recuperare i dati sarà necessaria una lettura del file system. Entrambi i tipi di recupero della pagina sono costosi. Il tentativo di ridurre l'input e l'output del disco rigido riducendo al minimo lo scambio di pagine anonime aumenta solo la quantità di input e output del disco rigido necessaria per gestire le pagine dei file che vengono scritte e lette da file.

Come puoi vedere dall'ultimo frammento di codice, ci sono due variabili. Uno chiamato file_prio per "priorità file" e uno chiamato anon_prio per "priorità anonima".
- La variabile
anon_prioè impostata sul valore di scambio di Linux. - Il valore
file_prioè impostato su 200 meno il valoreanon_prio.
Queste variabili contengono valori che funzionano in tandem. Se sono entrambi impostati su 100, sono uguali. Per qualsiasi altro valore, anon_prio diminuirà da 100 a 0 e file_prio aumenterà da 100 a 200. I due valori alimentano un complicato algoritmo che determina se il kernel Linux viene eseguito con una preferenza per il recupero (liberazione) di pagine di file o anonime pagine.
Puoi pensare a file_prio come alla volontà del sistema di liberare pagine di file e anon_prio come alla volontà del sistema di liberare pagine anonime. Ciò che questi valori non fanno è impostare alcun tipo di trigger o soglia per quando verrà utilizzato lo scambio. Questo è deciso altrove.
Ma, quando è necessario liberare memoria, queste due variabili, e il rapporto tra di esse, vengono prese in considerazione dagli algoritmi di recupero e scambio per determinare quali tipi di pagina sono preferenzialmente considerati per la liberazione. E questo determina se l'attività del disco rigido associata elaborerà i file per le pagine dei file o lo spazio di scambio per le pagine anonime.
Quando interviene effettivamente lo swap?
Abbiamo stabilito che il valore di scambio di Linux imposta una preferenza per il tipo di pagine di memoria che verranno scansionate per un potenziale recupero. Va bene, ma qualcosa deve decidere quando interverrà lo scambio.
Ciascuna zona di memoria ha un limite massimo e un limite minimo. Questi sono valori derivati dal sistema. Sono le percentuali della RAM in ciascuna zona. Sono questi valori che vengono utilizzati come soglie di attivazione dello scambio.
Per verificare quali sono i tuoi limiti massimi e minimi, guarda all'interno del file /proc/zoneinfo con questo comando:
meno /proc/zoneinfo

Ciascuna delle zone avrà una serie di valori di memoria misurati in pagine. Di seguito sono riportati i valori per la zona DMA32 sulla macchina di prova. Il limite minimo è 13966 pagine e il limite massimo è 16759 pagine:
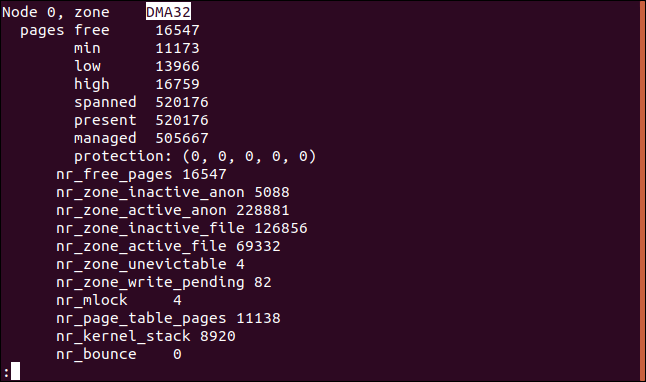
- In condizioni di funzionamento normali, quando la memoria libera in una zona scende al di sotto del limite minimo della zona, l'algoritmo di scambio avvia la scansione delle pagine di memoria alla ricerca di memoria che può recuperare, tenendo conto dei valori relativi di
anon_prioefile_prio. - Se il valore di scambio di Linux è impostato su zero, lo scambio si verifica quando il valore combinato delle pagine dei file e delle pagine libere è inferiore al limite massimo.
Quindi puoi vedere che non puoi usare il valore di swappiness di Linux per influenzare il comportamento di swap rispetto all'utilizzo della RAM. Semplicemente non funziona così.
Su cosa dovrebbe essere impostato Swapiness?
Ciò dipende dall'hardware, dal carico di lavoro, dal tipo di disco rigido e dal fatto che il computer sia un desktop o un server. Ovviamente, questa non sarà una taglia unica per tutti i tipi di impostazioni.
E devi tenere a mente che lo scambio non viene utilizzato solo come meccanismo per liberare RAM quando stai esaurendo lo spazio di memoria. Lo scambio è una parte importante di un sistema ben funzionante e, senza di esso, una sana gestione della memoria diventa molto difficile da ottenere per Linux.
La modifica del valore di scambio di Linux ha un effetto immediato; non è necessario riavviare. Quindi puoi apportare piccole modifiche e monitorare gli effetti. Idealmente, lo faresti per un periodo di giorni, con diversi tipi di attività sul tuo computer, per cercare di trovare il più vicino possibile a un'impostazione ideale.
Questi sono alcuni punti da considerare:
- Il tentativo di "disabilitare lo scambio" impostando il valore di scambio di Linux su zero sposta semplicemente l'attività del disco rigido associata allo scambio sull'attività del disco rigido associata ai file.
- Se si dispone di dischi rigidi meccanici obsoleti, è possibile provare a ridurre il valore di swappiness di Linux per allontanarsi dal ripristino anonimo della pagina e ridurre l'abbandono della partizione di scambio. Naturalmente, quando si abbassa un'impostazione, l'altra impostazione aumenta. È probabile che la riduzione dell'abbandono dello scambio aumenti l'abbandono del file system. Ma il tuo computer potrebbe essere più felice di preferire un metodo all'altro. Davvero, l'unico modo per saperlo con certezza è provare a vedere.
- Per i server monouso, come i server di database, è possibile ottenere indicazioni dai fornitori del software di database. Molto spesso, queste applicazioni hanno la propria cache di file appositamente progettata e routine di gestione della memoria su cui faresti meglio a fare affidamento. I fornitori di software possono suggerire un valore di swappiness Linux in base alle specifiche della macchina e al carico di lavoro.
- Per l'utente desktop medio con hardware ragionevolmente recente? Lascialo così com'è.
Come impostare il valore di scambio di Linux
Prima di modificare il valore di swappiness, devi sapere qual è il suo valore attuale. Se vuoi ridurlo un po', la domanda è un po' meno di cosa? Puoi scoprirlo con questo comando:
cat /proc/sys/vm/swappiness

Per configurare il valore di swappiness, utilizzare il comando sysctl :
sudo sysctl vm.swappiness=45

Il nuovo valore viene utilizzato immediatamente, non è necessario riavviare.
In effetti, se esegui il riavvio, il valore di swappiness tornerà al suo valore predefinito di 60. Quando hai finito di sperimentare e hai deciso il nuovo valore che desideri utilizzare, puoi renderlo persistente tra i riavvii aggiungendolo a /etc/sysctl.conf . Puoi usare l'editor che preferisci. Utilizzare il comando seguente per modificare il file con l'editor nano :
sudo nano /etc/sysctl.conf

Quando nano si apre, scorri fino alla fine del file e aggiungi questa riga. Stiamo usando 35 come valore di swappiness permanente. Dovresti sostituire il valore che desideri utilizzare.
vm.swappiness=35
Per salvare le modifiche e uscire da nano , premi "Ctrl+O", premi "Invio" e premi "Ctrl+Z".
La gestione della memoria è complessa
La gestione della memoria è complicata. Ed è per questo che, per l'utente medio, di solito è meglio lasciare che sia il kernel.
È facile pensare che stai usando più RAM di te. Utilità come top e free possono dare l'impressione sbagliata. Linux utilizzerà la RAM libera per una varietà di scopi, come la memorizzazione nella cache del disco. Ciò eleva artificialmente la figura della memoria "usata" e riduce la figura della memoria "libera". In effetti, la RAM utilizzata come cache del disco è contrassegnata sia come "usata" che come "disponibile" perché può essere recuperata in qualsiasi momento, molto rapidamente.
Per chi non lo sapesse, potrebbe sembrare che lo scambio non funzioni o che il valore di scambio debba essere modificato.
Come sempre, il diavolo è nei dettagli. O, in questo caso, il demone. Il demone di scambio del kernel.
| Comandi Linux | ||
| File | tar · pv · cat · tac · chmod · grep · diff · sed · ar · man · pushd · popd · fsck · testdisk · seq · fd · pandoc · cd · $PATH · awk · join · jq · fold · uniq · journalctl · tail · stat · ls · fstab · echo · less · chgrp · chown · rev · look · strings · type · rename · zip · unzip · mount · umount · install · fdisk · mkfs · rm · rmdir · rsync · df · gpg · vi · nano · mkdir · du · ln · patch · converti · rclone · shred · srm | |
| Processi | alias · screen · top · nice · renice · progress · strace · systemd · tmux · chsh · history · at · batch · free · which · dmesg · chfn · usermod · ps · chroot · xargs · tty · pinky · lsof · vmstat · timeout · wall · yes · kill · sleep · sudo · su · time · groupadd · usermod · groups · lshw · shutdown · reboot · halt · poweroff · passwd · lscpu · crontab · date · bg · fg | |
| Rete | netstat · ping · traceroute · ip · ss · whois · fail2ban · bmon · dig · finger · nmap · ftp · curl · wget · who · whoami · w · iptables · ssh-keygen · ufw |
CORRELATI: I migliori laptop Linux per sviluppatori e appassionati