
Come utilizzare il comando wc in Linux
Pubblicato: 2022-07-23
Contare il numero di righe, parole e byte in un file è utile, ma la vera flessibilità del comando wc di Linux deriva dal lavorare con altri comandi. Diamo un'occhiata.
Qual è il comando wc?
Il comando wc è una piccola applicazione. È una delle utility principali di Linux, quindi non è necessario installarla. Sarà già sul tuo computer Linux.
Puoi descrivere quello che fa in poche parole. Conta le righe, le parole e i byte in un file o una selezione di file e stampa il risultato in una finestra di terminale. Può anche prendere il suo input dal flusso STDIN, il che significa che il testo che vuoi che elabori può essere reindirizzato al suo interno. È qui che wc inizia davvero ad aggiungere valore.

È un ottimo esempio del mantra Linux di "fai una cosa e falla bene". Poiché accetta input tramite pipe, può essere utilizzato in incantesimi multi-comando. Come vedremo, questa piccola utility autonoma è in realtà un ottimo giocatore di squadra.
Un modo in cui uso wc è come segnaposto in un comando complicato o alias che sto preparando. Se il comando finito ha il potenziale per essere distruttivo ed eliminare i file, uso spesso wc come sostituto del comando reale e pericoloso.
In questo modo, durante lo sviluppo del comando ottengo un feedback visivo che ogni file viene elaborato come previsto. Non c'è possibilità che succeda qualcosa di brutto mentre sto lottando con la sintassi.
Per quanto sia semplice wc , ci sono ancora alcune piccole stranezze che devi conoscere.
Iniziare con il wc
Il modo più semplice per utilizzare wc è passare il nome di un file di testo sulla riga di comando.
wc lorem.txt

Ciò fa sì che wc esegua la scansione del file e conti le righe, le parole e i byte e li scriva nella finestra del terminale.
Le parole sono considerate qualsiasi cosa delimitata da spazi bianchi. Che siano parole di una lingua reale o meno è irrilevante. Se un file non contiene altro che "frd g lkj", conta comunque come tre parole.
Le righe sono sequenze di caratteri terminate da un ritorno a capo o dalla fine del file. Non importa se la riga si avvolge nell'editor o nella finestra del terminale, finché wc non incontra un ritorno a capo o la fine del file, è sempre la stessa riga.
Il nostro primo esempio ha trovato una riga nell'intero file. Ecco il contenuto del file “lorem.txt”.
gatto lorem.txt
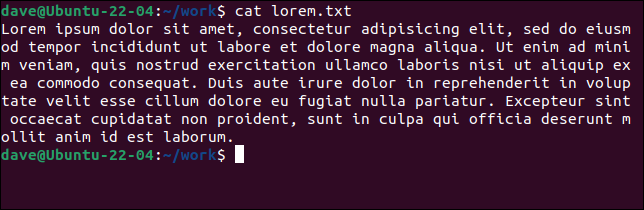
Tutto ciò conta come una singola riga perché non ci sono ritorni a capo. Confronta questo con un altro file, "lorem2.txt", e come lo interpreta wc .
wc lorem2.txt
gatto lorem2.txt
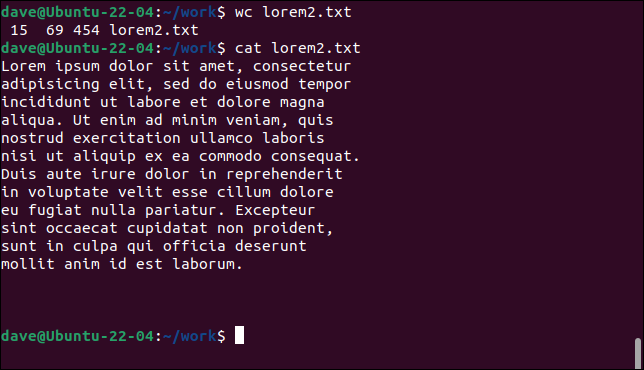
Questa volta, wc conta 15 righe perché i ritorni a capo sono stati inseriti nel testo per iniziare una nuova riga in punti specifici. Tuttavia, se conti le righe con il testo, vedrai che ce ne sono solo 12.
Le altre tre righe sono righe vuote alla fine del file. Questi contengono solo ritorni a capo. Anche se non c'è testo in queste righe, è stata avviata una nuova riga e quindi le wc come tali.
Possiamo passare a wc tutti i file che vogliamo.
wc lorem.txt lorem2.txt
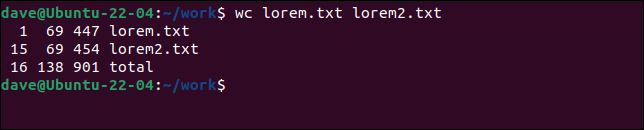
Otteniamo le statistiche per ogni singolo file e un totale per tutti i file.
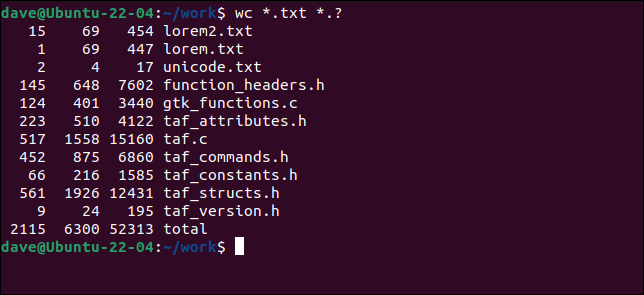
Possiamo anche usare i caratteri jolly in modo da poter selezionare i file corrispondenti invece dei file con nome esplicito.
wc *.txt *.?
Le opzioni della riga di comando
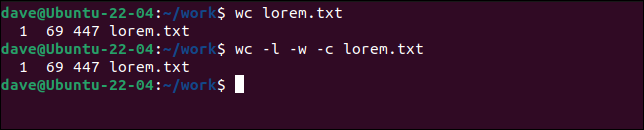
Per impostazione predefinita, wc visualizzerà le righe, le parole e i byte in ogni file. È come usare le opzioni -l (linee) -w (parole) e -c (byte).
wc lorem.txt
wc -l -w -c lorem.txt
Possiamo specificare quale combinazione di figure desideriamo vedere.
wc -l lorem.txt wc -w lorem.txt wc -c lorem.txt wc -l -c lorem.txt
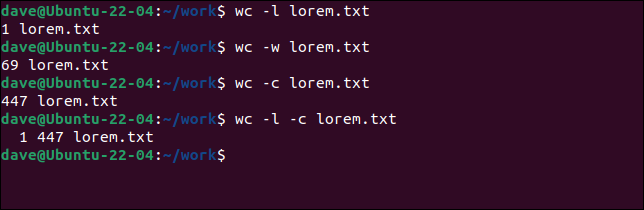
Particolare attenzione dovrebbe essere prestata all'ultima cifra, generata dall'opzione -c (byte). Molte persone lo scambiano per contare i personaggi. In realtà conta i byte . Il numero di caratteri e il numero di byte potrebbero essere gli stessi. Ma non sempre.
Diamo un'occhiata al contenuto di un file chiamato "unicode.txt".
gatto unicode.txt

Ha tre parole e un carattere dell'alfabeto non latino. Lasceremo che wc elabori il file con l'impostazione predefinita di bytes e lo faremo di nuovo ma richiederemo caratteri con l'opzione -m (caratteri).
wc unicode.txt
wc -l -w -m unicode.txt
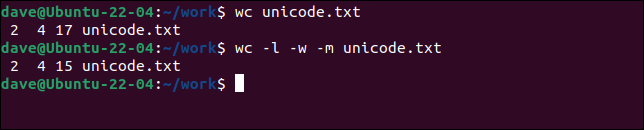
Ci sono più byte che caratteri.
Diamo un'occhiata al dump esadecimale del file e vediamo cosa sta succedendo. L'opzione -C (canonical) del comando hexdump visualizza i byte nel file in righe di 16, con il loro equivalente ASCII semplice (se presente) mostrato alla fine della riga. Se non esiste un carattere ASCII corrispondente, un punto “ . ” viene invece mostrato.

hexdump -C unicode.txt
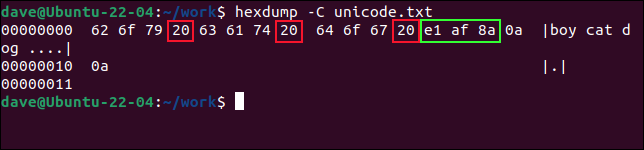
In ASCII, un valore esadecimale di 0x20 rappresenta uno spazio. Se contiamo tre valori da sinistra, vediamo che il valore successivo è uno spazio. Quindi i primi tre valori 0x62 , 0x6f e 0x79 rappresentano le lettere in "boy".
Saltando sopra 0x20 , vediamo un altro set di tre valori esadecimali: 0x63 , 0x61 e 0x74 . Questi enunciano "gatto". Saltando sul carattere spazio successivo vediamo altri tre valori per le lettere in "cane". Questi sono 0x64 , 0x5f e 0x67 .
Proprio dietro la parola "cane" possiamo vedere uno spazio 0x20 e altri cinque valori esadecimali. Gli ultimi due sono ritorni a capo, 0x0a .
Gli altri tre byte rappresentano il carattere non latino, che abbiamo cerchiato in verde. È un carattere Unicode e ci vogliono tre byte per codificarlo. Questi sono 0xe1 , 0xaf e 0x8a .
Quindi assicurati di sapere cosa stai contando e che byte e caratteri non siano necessariamente gli stessi. Di solito, il conteggio dei byte è più utile perché ti dice cosa c'è effettivamente all'interno del file. Il conteggio per caratteri ti dà il numero di cose rappresentate dal contenuto del file.
CORRELATI: Cosa sono le codifiche dei caratteri come ANSI e Unicode e in che cosa differiscono?
Prendere nomi di file da un file
C'è un altro modo per fornire nomi di file a wc . Puoi inserire i nomi dei file in un file e passare il nome di quel file a wc . Apre il file, estrae i nomi dei file e li elabora come se fossero stati passati sulla riga di comando. Ciò consente di memorizzare una raccolta arbitraria di nomi di file per il riutilizzo.
Ma c'è un problema, ed è grande. I nomi dei file devono essere terminati con null , non con il ritorno a capo. Cioè, dopo ogni nome di file deve esserci un byte nullo di 0x00 invece del solito byte di ritorno a 0x0a .
Non puoi aprire un editor e creare un file con questo formato. In genere, file come questo sono generati da altri programmi. Ma, se hai un file del genere, è così che lo useresti.
Ecco il nostro file contenente i nomi dei file. L'apertura in less mostra gli strani caratteri “ ^@ ” che less usa per indicare byte nulli.
meno sorgente-files-list.txt

Per utilizzare il file con wc , dobbiamo usare --files0-from (leggi input da) e passare il nome del file contenente i nomi dei file.
wc ---files0-from=lista-file-sorgente.txt
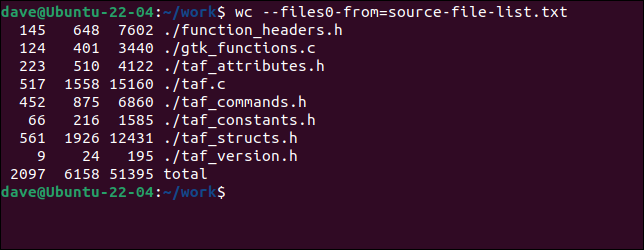
I file vengono elaborati esattamente come se fossero stati forniti sulla riga di comando.
Ingresso tubazioni al wc
Un modo molto più comune, flessibile e produttivo per inviare input a wc consiste nel reindirizzare l'output da altri comandi a wc . Possiamo dimostrarlo con il comando echo .
echo "Conta questo per me" | bagno
echo -e "Conta questo\nper me" | bagno
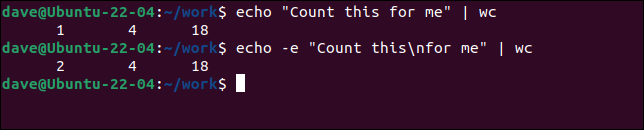
Il secondo comando echo utilizza l'opzione -e (caratteri di escape) per consentire sequenze di escape come il codice di formattazione di nuova riga " \n ". Questo inserisce una nuova riga, facendo in modo che wc veda l'input come due righe.
Ecco una cascata di comandi che alimentano il loro input dall'uno all'altro.
trova ./* -digita f | riv | taglia -d'.' -f1 | riv | ordina | uniq
- find cerca i file (
type -f) in modo ricorsivo, a partire dalla directory corrente.revinverte i nomi dei file. - cut estrae il primo campo (
-f1) definendo il delimitatore di campo come un punto”.” e leggendo dalla “parte anteriore” del nome file invertito fino al primo punto che trova. Ora abbiamo estratto l'estensione del file. - rev inverte il primo campo estratto.
- sort li ordina in ordine alfabetico crescente.
- uniq elenca le voci univoche nella finestra del terminale.
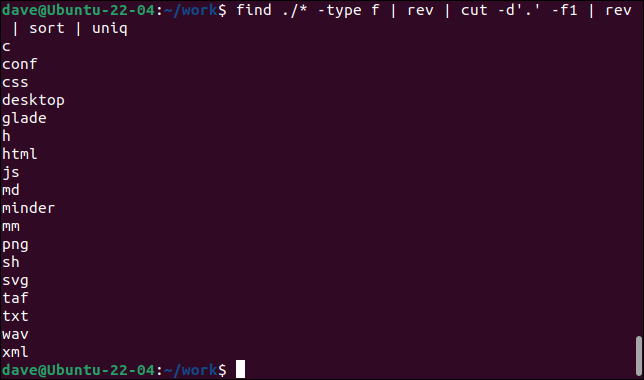
Questo comando elenca tutte le estensioni di file univoche nella directory corrente e tutte le sottodirectory.
Se aggiungessimo l'opzione -c (count) al comando uniq , conterebbe le occorrenze di ogni tipo di estensione. Ma se vogliamo sapere quante estensioni di file diverse e uniche ci sono, possiamo rilasciare wc come ultimo comando sulla riga e utilizzare l'opzione -l (linee).
trova ./* -digita f | riv | taglia -d'.' -f1 | riv | ordina | uniq | wc -l

CORRELATI: Come utilizzare il comando di taglio di Linux
E infine
Ecco un ultimo trucco che wc può fare per te. Ti dirà la lunghezza della riga più lunga in un file. Purtroppo, non ti dice quale linea è. Ti dà solo la lunghezza.
wc -L taf.c

Attenzione però, che le schede vengono contate come otto spazi. Visto nel mio editor, ci sono tre schede a due spazi all'inizio di quella riga. La sua lunghezza reale è di 124 caratteri. Quindi la cifra riportata viene ampliata artificialmente.
Tratterei questa funzione con le pinze. E con questo intendo di non usarlo. Il suo output è fuorviante.
Nonostante le sue stranezze, wc è un ottimo strumento da inserire nei comandi reindirizzati quando è necessario contare tutti i tipi di valori, non solo le parole in un file.
CORRELATI: 37 importanti comandi Linux che dovresti conoscere