
8 errori di battitura che devi davvero evitare su Linux
Pubblicato: 2023-01-15
La riga di comando di Linux offre una grande potenza. Il problema è che l'uso corretto di quel potere dipende dall'accuratezza della tua digitazione. Ecco otto errori di battitura che non vorresti mai fare.
La riga di comando di Linux
1. Non dimenticare la -a
2. Utilizzo dell'identificatore di unità errato con dd
3. Utilizzo dell'identificatore di unità errato con mkfs
4. Non eliminare il tuo file crontab
5. Storia ripetuta
6. La calamità degli spazi
7. Usando > Invece di >>
8. Reindirizzamento nella direzione sbagliata
Come evitare errori di battitura della riga di comando
La riga di comando di Linux
La riga di comando di Linux è un portale di grande potere, ma un errore di battitura è tutto ciò che serve perché quel potere si rivolti contro di te. Abbiamo tutti sentito parlare del comando che non dovresti mai eseguire. Quello di cui stiamo parlando qui sono i comandi che vuoi eseguire, ma dove un errore può significare un disastro.
Quando premi "Invio", tutto ciò che hai digitato viene elaborato dalla shell. Gli alias e le variabili vengono espansi. Vengono identificati comandi, opzioni e parametri. Questo si chiama analisi. Il passaggio successivo passa il tuo input analizzato ai comandi che eseguiranno le tue istruzioni.
Se commetti un errore quando digiti i tuoi comandi, potrebbe essere intrappolato come un errore di sintassi. Ma se il tuo errore crea un'altra riga di comando valida, verrà eseguita.
Un semplice errore di battitura può essere veramente distruttivo. Il livello di distruzione dipende dal comando e dall'errore. Potresti perdere tempo. Potresti perdere un file. Potresti perdere un intero file system.
CORRELATO: Cos'è la Bash Shell e perché è così importante per Linux?
1. Non dimenticare la -a
Potrebbe essere necessario aggiungere qualcuno a un gruppo per consentire loro, ad esempio, di utilizzare un particolare software. Ad esempio, VirtualBox richiede che gli utenti facciano parte del gruppo "vboxusers". Possiamo farlo con usermod .
Il comando groups elenca i gruppi di un utente.
gruppi

Aggiungeremo l'utente dave a un nuovo gruppo. L'opzione -a (aggiungi) aggiunge il nuovo gruppo all'elenco dei gruppi esistenti in cui si trova l'utente. L'opzione -G (gruppi) identifica il gruppo.
sudo usermod -a -G vboxusers dave

Il nuovo gruppo viene visualizzato dopo l'accesso e la disconnessione dell'utente.
gruppi

Ora è nel gruppo "vboxusers". Tuttavia, se si dimentica di utilizzare l'opzione -a (aggiungi), tutti i gruppi esistenti dell'utente vengono rimossi. L'unico gruppo in cui saranno, è il nuovo gruppo.
Questo è il comando errato :
sudo usermod -G vboxusers dave

Quando accedono successivamente, scopriranno di essere solo in un gruppo.
gruppi

Se hai un singolo utente configurato e gli fai questo, avrai seri problemi. Per prima cosa, l'utente non è più un membro del gruppo "sudo", quindi non puoi usare sudo per iniziare a correggere le cose.
CORRELATO: Aggiungi un utente a un gruppo (o secondo gruppo) su Linux
2. Utilizzo dell'identificatore di unità errato con dd
Il comando dd scrive blocchi di dati nei file system. Viene spesso utilizzato per scrivere immagini ISO su memory stick USB.
Lo schema di denominazione di Linux per i dispositivi di archiviazione utilizza una singola lettera per l'identificazione. Il primo disco rigido si chiama "/dev/sda", il secondo è "/dev/sdb", il terzo è "/dev/sdc" e così via. Le partizioni sono identificate da un numero. La prima partizione sul primo disco rigido è "/dev/sda1", la seconda è "/dev/sda2" e così via.
Se si masterizza un'immagine su una memory stick USB, è necessario conoscere l'identificatore dell'unità della memory stick USB. Lo scopriremo lsblk attraverso grep , cercando le voci con "sd" al loro interno.
lsblk | grep sd
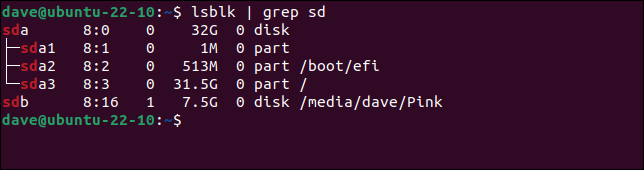
Possiamo vedere che il disco rigido "/dev/sda" è un'unità da 32 GB con tre partizioni. Una delle partizioni è la partizione "/boot" e la partizione "/dev/sda3" è montata su "/", che è la radice del file system.
Il disco rigido "/dev/sdb" viene segnalato come un'unità da 7,5 GB. È montato in "/media/dave/Pink". Chiaramente, l'unità "/dev/sda" è il disco rigido principale di questo computer e "/dev/sdb" è la memory stick USB.
Il comando per scrivere un file ISO che si trova nella directory "~/Downloads" sulla nostra memory stick USB è:
sudo dd bs=4M if=Download/distro-image.iso of=/dev/sdb conv=fdatasync status=progress

Ci viene richiesta la nostra password, quindi dd entra in azione. Non ci sono "Sei sicuro?" avvertimenti o possibilità di ritirarsi. La scrittura parte subito.

Tuttavia, se digiti la lettera sbagliata per l'identificatore dell'unità e corrisponde a un disco rigido esistente, sovrascriverai quell'unità anziché la memory stick.
Questo è il comando errato :
sudo dd bs=4M if=Download/distro-image.iso of=/dev/sda conv=fdatasync status=progress
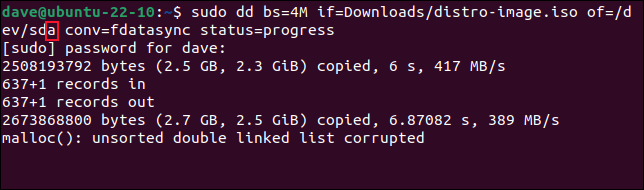
Abbiamo detto a dd di usare "/dev/sd a ", così è stato. L'azione di scrittura è molto più veloce, ma termina con un avviso. Hai appena distrutto la tua installazione di Linux.
Controlla e ricontrolla gli identificatori di unità prima di premere "Invio".
CORRELATO: Come masterizzare un file ISO su un'unità USB in Linux
3. Utilizzo dell'identificatore di unità errato con mkfs
Esistono altri comandi che accettano identificatori di unità come parte della loro riga di comando, come gli strumenti mkfs . Questi formattano le unità creando file system sulle partizioni.
Su questo computer abbiamo un'unità da 25 GB e un'unità da 10 GB.
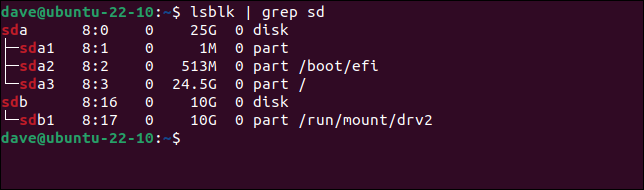
Se vogliamo creare un file system Ext4 sulla prima partizione dell'unità da 10 GB, utilizzeremo questi comandi.
sudo umount /dev/sdb1
sudo mkfs.ext4 /dev/sdb1
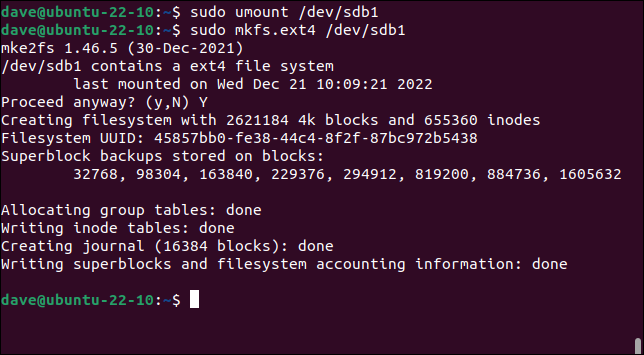
Ma se commettiamo l'errore di utilizzare una "a" invece di una "b" nell'identificatore dell'unità, cancelleremo una delle partizioni sull'unità da 25 GB e renderemo il nostro computer non avviabile.
Questo è il comando errato :
sudo umount /dev/sda1
sudo mkfs.ext4 /dev/sda1
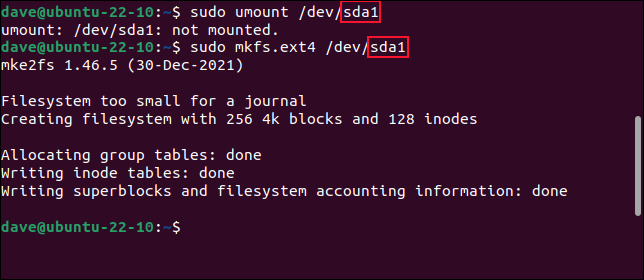
Quella piccola lettera è un pugno, quindi assicurati di colpire l'unità giusta.
CORRELATO: Come utilizzare il comando mkfs su Linux
4. Non eliminare il tuo file crontab
Il demone cron esegue le attività in orari prestabiliti per te. Prende la sua configurazione da un file crontab . Ogni utente, incluso root, può avere un file crontab . Per modificare il tuo crontab , usa questo comando:
crontab -e


Il file crontab viene aperto in un editor. Puoi apportare modifiche e aggiungere nuovi comandi.
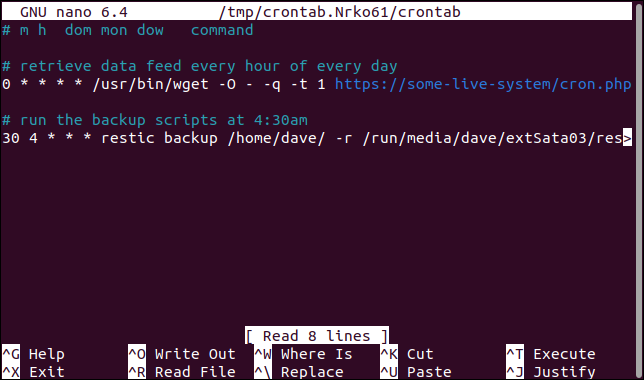
Ma se digiti male il comando e premi "r" invece di "e", rimuoverai, come in delete , il tuo file crontab .
Questo è il comando errato :
crontab -r

La prossima volta che usi il comando crontab -e , vedrai un file vuoto predefinito.
Questo è un errore facile da fare, perché "e" e "r" sono l'una accanto all'altra sulla maggior parte delle tastiere. Ricostruire un complicato file crontab non è divertente.
CORRELATI: Cos'è un Cron Job e come li usi?
5. Storia ripetuta
L'uso del comando history è ottimo quando stai cercando di ridurre le sequenze di tasti e risparmiare tempo. Se riesci a estrarre un comando prolisso dalla storia, guadagni velocità e precisione. Finché selezioni il comando giusto dalla cronologia.
Il comando history elenca i comandi precedenti nella finestra del terminale. Sono numerati. Per riutilizzare un comando, far precedere il suo numero da un punto esclamativo “ ! “, e premi il tasto “Invio”.
storia
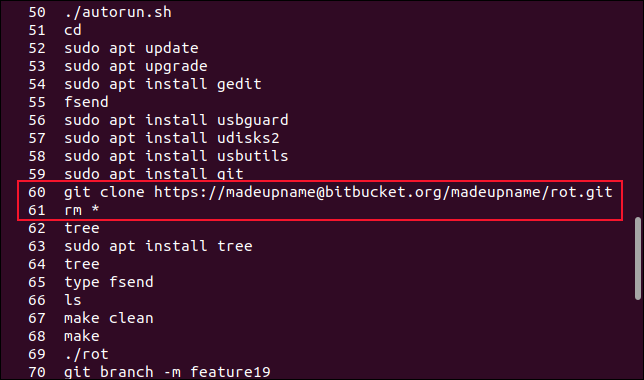
Supponiamo di aver clonato un repository Git, di aver fatto un pasticcio con esso e di averlo eliminato. Dobbiamo clonarlo ancora una volta. Scorrendo nella finestra del terminale, possiamo presto individuare il comando git clone . Possiamo rieseguirlo digitando:
!60
Ma se abbiamo solo dato un'occhiata allo schermo e letto male il numero, potremmo scegliere per errore il numero successivo:
!61
Questo esegue il comando successivo nell'elenco, rm * . Ciò elimina tutti i file nella directory corrente.
Puoi anche usare il " ! ” punto esclamativo con una stringa di testo. Il primo comando corrispondente viene eseguito per te. Non viene visualizzato in modo che tu possa verificare che sia quello a cui stavi pensando, viene eseguito immediatamente.
Immagina lo scenario in cui hai uno script chiamato "restart.sh". Questo script imposta come predefinito un set di file di configurazione per alcuni software che stai scrivendo. Periodicamente, mentre sviluppi e collaudi, devi pulire la lavagna, quindi chiami il tuo script.
Questo comando dovrebbe essere sufficiente per trovare e abbinare il comando nella cronologia e per eseguirlo.
!rif
Ma se hai utilizzato il comando reboot dall'ultima volta che hai utilizzato lo script, è il comando reboot che viene trovato ed eseguito immediatamente.

Sul tuo computer di casa per utente singolo probabilmente è solo un fastidio. Su un server condiviso è un fastidio anche per molte altre persone.
CORRELATO: Come utilizzare il comando history su Linux
6. La calamità degli spazi
Gli spazi nei nomi dei file e nei percorsi delle directory possono causare problemi. Ecco perché dovrebbero sempre essere sfuggiti o citati.

I problemi con gli spazi possono essere evitati utilizzando il completamento tramite tabulazione. Premi il tasto "Tab" quando stai digitando un nome file o un percorso di directory e la shell completerà automaticamente quanto più percorso o nome file possibile. Potrebbe essere necessario digitare una lettera per distinguere tra il file desiderato e qualsiasi altro file che condivide parte dello stesso nome, ma un'altra pressione del tasto "Tab" completerà il resto del nome file per te.
Ciò consente di risparmiare sulle sequenze di tasti, impedisce agli spazi di insinuarsi a causa di errori di battitura e sfugge correttamente a eventuali spazi legittimi in modo che non causino problemi.
Supponiamo di avere una directory "Development" che contiene altre due directory, "geocoder" e "bin". C'è anche una directory “bin” all'interno della directory “geocoder”.
Per eliminare i file nella directory "geocoder/bin" e rimuovere la directory, utilizzare questo comando.
rm -r geocodificatore/bin

Ora immagina di aver aggiunto inavvertitamente uno spazio dopo "geocoder/", in questo modo.
Questo è il comando errato :
rm -r geocodificatore/bin

Boom. La directory "Sviluppo" è ora vuota. Le directory "Development/geocoder", "Development/geocoder/bin" e "Development/bin" sono state completamente cancellate.
Ricorda, il completamento della scheda è tuo amico.
CORRELATO: Usa il completamento tramite tabulazione per digitare i comandi più velocemente su qualsiasi sistema operativo
7. Usando > Invece di >>
Il reindirizzamento invia l'output di un processo a un file. Usiamo il segno maggiore di " > " per catturare l'output di un processo. Se il file esiste, viene prima svuotato.
Diciamo che stiamo indagando su una perdita di memoria. Abbiamo uno script chiamato "memlog.sh". Visualizza le statistiche della memoria una volta al secondo. Lo reindirizzeremo in un file chiamato "memory.txt", per un'analisi successiva.
memlog.sh > memoria.txt
head memory.txt
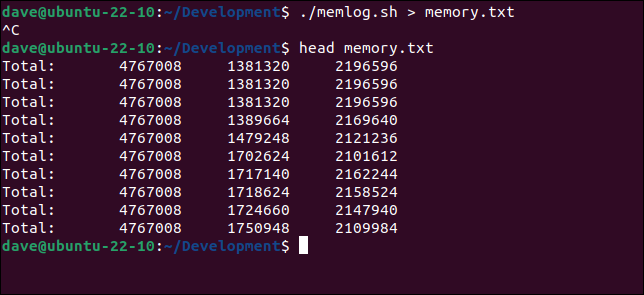
Il giorno dopo, vogliamo continuare con la nostra indagine e riavviamo la sceneggiatura. Questa volta abbiamo bisogno di usare due segni maggiore di " >> " in modo che i nuovi dati vengano aggiunti al file.
memlog.sh >> memoria.txt

Se usiamo un singolo segno maggiore di ">", perderemo i dati di ieri perché il file viene svuotato prima.
CORRELATO: Cosa sono stdin, stdout e stderr su Linux?
8. Reindirizzamento nella direzione sbagliata
Il reindirizzamento può utilizzare il contenuto di un file come input per un programma.
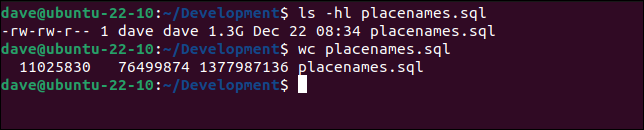
Abbiamo un file chiamato “placenames.sql” che vogliamo importare in sqlite3 . Il file dello schema descrive come ricreare le tabelle del database. Contiene anche i dati che vogliamo archiviare nel database. Con 1,3 GB e oltre 11 milioni di righe, è un file di grandi dimensioni.
ls -hl toponimi.sql
wc placenames.sql
Possiamo creare un nuovo database chiamato "places.sqlite3" con questo comando.
sqlite3 luoghi.sqlite3 < toponimi.sql

Il più delle volte, quando stiamo reindirizzando usiamo il carattere ">". Devi concentrarti per evitare di digitare ">" per abitudine. Se lo fai, qualsiasi output generato da sqlite3 viene scritto nel tuo file di schema, cancellandolo.
Questo è il comando errato :
sqlite3 luoghi.sqlite3 > toponimi.sql

Il nostro file schema è stato distrutto, sovrascritto dal messaggio di benvenuto della shell sqlite3 .
cat placenames.sql

Ciao ciao, 1,3 GB di dati.
Come evitare errori di battitura della riga di comando
Ci sono buone abitudini che puoi adottare per evitare di commettere questo tipo di errori.
Usa il completamento tramite tabulazioni ove possibile. Eviterai problemi con gli spazi nei percorsi delle directory e nei nomi dei file.
Crea i tuoi alias brevi e memorabili per comandi lunghi e complicati che devi usare occasionalmente. In questo modo, non sbaglierai utilizzando le opzioni e i parametri sbagliati.
È notoriamente difficile correggere le bozze della tua scrittura, ma è quello che devi fare sulla riga di comando. Leggi cosa c'è davvero. Non limitarti a guardarlo e pensare che dica cosa intendevi digitare. Cosa dice veramente? Perché è quello che farà davvero.
CORRELATO: 8 comandi mortali che non dovresti mai eseguire su Linux