
Come funziona il motore di ricerca e ti semplifica la vita?
Pubblicato: 2015-11-06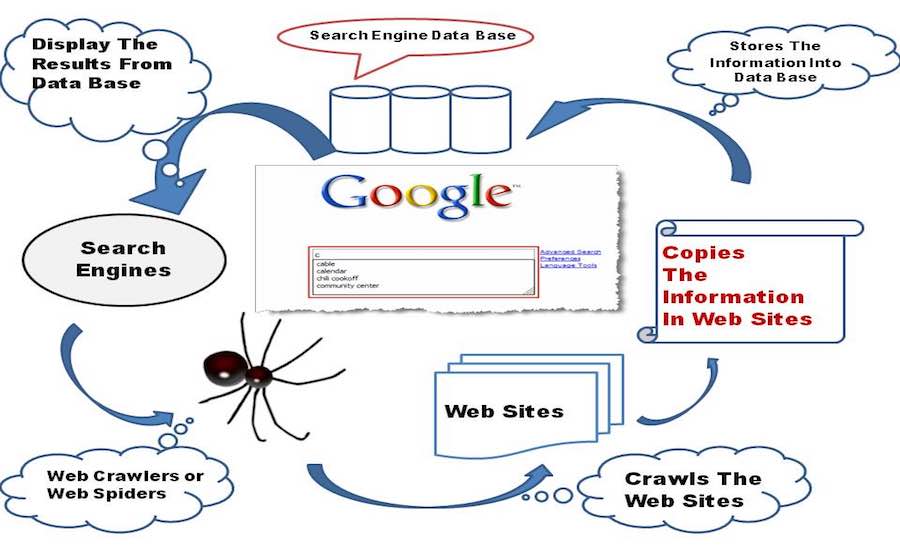 Byte brevi: Search Engine è un software che permette la visualizzazione dei risultati di pagine web rilevanti in base alla query di ricerca immessa mediante l'utilizzo di Web Crawling e Web Indexing, alcune formule fatiscenti e algoritmi intelligenti per raccogliere i dati appropriati.
Byte brevi: Search Engine è un software che permette la visualizzazione dei risultati di pagine web rilevanti in base alla query di ricerca immessa mediante l'utilizzo di Web Crawling e Web Indexing, alcune formule fatiscenti e algoritmi intelligenti per raccogliere i dati appropriati.
In che modo Google ti offre i migliori risultati in un batter d'occhio? In realtà, non importa fino a quando Google, Bing non sono lì. Lo scenario sarebbe stato molto diverso se non ci fossero stati Google, Bing o Yahoo. Immergiamoci nel mondo dei motori di ricerca e vediamo come funziona un motore di ricerca.
Sbirciando nella storia
La favola dei motori di ricerca è iniziata negli anni '90, quando Tim Berners-Lee arruolava ogni nuovo server web che andava online, nell'elenco gestito dal server web del CERN. Fino al settembre 93 non esistevano motori di ricerca su Internet, ma solo pochi strumenti in grado di mantenere un database di nomi di file. Archie, Veronica, Jughead sono stati i primissimi ad entrare in questa categoria.
Oscar Nierstraz dell'Università di Ginevra è accreditato per il primo motore di ricerca che è nato, chiamato W3Catalog. Ha fatto alcuni seri scripting Perl e alla fine è uscito con il primo motore di ricerca al mondo il 3 settembre 1993. Inoltre, l'anno 1993 ha visto l'avvento di molti altri motori di ricerca. JumpStation di Jonathon Fletcher, AliWeb, WWW Worm, ecc. Yahoo! è stato lanciato nel 1995 come directory web, ma ha iniziato a utilizzare il motore di ricerca di Inktomi dal 2000 per poi passare a Bing di Microsoft nel 2009.
Ora, parlare del nome che è il sinonimo principale del termine motore di ricerca, Google Search, era un progetto di ricerca per due laureati di Stanford, Larry Page e Sergy Brin, che ha avuto le sue impronte iniziali nel marzo 1995. Il lavoro di Google è stato inizialmente ispirato dal metodo di collegamento a ritroso di Page che effettuava calcoli in base al numero di collegamenti a ritroso originati da una pagina Web, in modo da misurare l'importanza di quella pagina nel World Wide Web. "Il miglior consiglio che abbia mai ricevuto", ha detto Page, mentre ricordava come il suo supervisore Terry Winograd sostenne la sua idea. E da allora, Google non si è più guardato indietro.
Tutto inizia con un gattonare
Un motore di ricerca per bambini nella sua fase nascente inizia a esplorare il World Wide Web, con le sue piccole mani e le sue ginocchia esplora ogni altro collegamento che trova su una pagina Web e li memorizza nel suo database.
Ora, concentriamoci su alcuni pensieri tecnici dietro le quinte, un motore di ricerca incorpora un software Web Crawler che è fondamentalmente un bot Internet a cui è assegnato il compito di aprire tutti i collegamenti ipertestuali presenti su una pagina Web e creare un database di testo e metadati da tutti i collegamenti . Inizia con una serie iniziale di link da visitare, chiamati Seeds. Non appena procede con la visita di tali collegamenti, aggiunge nuovi collegamenti nell'elenco esistente di URL da visitare, noto come Crawl Frontier.
Mentre il crawler attraversa i collegamenti, scarica le informazioni da quelle pagine Web per essere visualizzate in seguito sotto forma di istantanee, poiché il download dell'intera pagina Web richiederebbe un sacco di dati e ha un prezzo conveniente, almeno in paesi come l'India. E posso scommettere, se Google fosse stato fondato in India, tutti i loro soldi sarebbero stati utilizzati per pagare le bollette di Internet. Si spera che per ora non sia un argomento di preoccupazione.
Il crawler Web esplora le pagine Web in base ad alcuni criteri:
Politica di selezione: il crawler decide quali pagine scaricare e quali no. La politica di selezione si concentra sul download del contenuto più rilevante di una pagina Web piuttosto che di alcuni dati non importanti.
Re-Visit Policy: il crawler pianifica l'ora in cui dovrebbe riaprire le pagine web e modificare le modifiche nel suo database, grazie alla natura dinamica di Internet che rende molto difficile per i crawler rimanere aggiornati con le ultime versioni di le pagine web.
Politica di parallelizzazione: i crawler utilizzano più processi contemporaneamente per esplorare i collegamenti noti come Scansione distribuita, ma a volte ci sono possibilità che processi diversi possano scaricare la stessa pagina Web, quindi il crawler mantiene un coordinamento tra tutti i processi per eliminare ogni possibilità di duplicità.
Politica di cortesia: quando un crawler attraversa un sito Web, scarica simultaneamente le pagine Web da esso, aumentando così il carico sul server Web che ospita il sito Web. Quindi, viene implementato un termine "Crawl-Delay" in cui il crawler deve attendere alcuni secondi dopo aver scaricato alcuni dati da un server web ed è regolato dalla Politica di cortesia.
Leggi anche: Come creare un web crawler di base in Python
Architettura di alto livello di un Web Crawler standard:
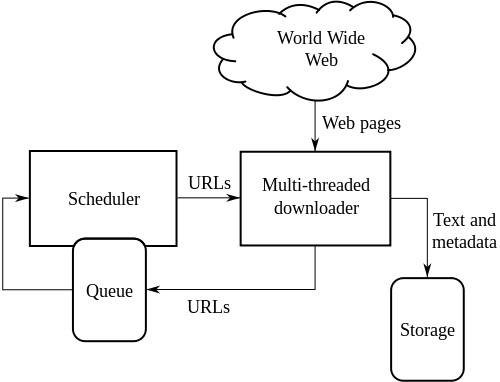
L'illustrazione sopra mostra come funziona un web crawler. Apre l'elenco iniziale di collegamenti e quindi i collegamenti all'interno di quei collegamenti e così via.
Wikipedia scrive, i ricercatori di informatica Vladislav Shkapenyuk e Torsten Suel hanno notato che:
Sebbene sia abbastanza facile creare un crawler lento che scarichi alcune pagine al secondo per un breve periodo di tempo, la creazione di un sistema ad alte prestazioni in grado di scaricare centinaia di milioni di pagine in diverse settimane presenta una serie di sfide nella progettazione del sistema, Efficienza di I/O e rete, robustezza e gestibilità.
Indicizzazione dei crawl
Dopo che il motore di ricerca per bambini esegue la scansione su Internet, crea un indice di tutte le pagine Web che trova sulla sua strada. Avere un indice è molto meglio che perdere tempo a trovare la query di ricerca da un mucchio di documenti di grandi dimensioni, ti farà risparmiare tempo e risorse.
Ci sono molti fattori che contribuiscono a creare un sistema di indicizzazione efficiente per un motore di ricerca. Le tecniche di archiviazione utilizzate dagli indicizzatori, la dimensione dell'indice, la capacità di trovare rapidamente i documenti contenenti le parole chiave ricercate, ecc. sono i fattori responsabili dell'efficienza e dell'affidabilità di un indice.
Uno dei maggiori ostacoli nel percorso per realizzare indici web di successo è la collisione tra due processi. Supponiamo che un processo voglia cercare un documento e allo stesso tempo un altro processo voglia aggiungere un documento nell'indice, in qualche modo crea un conflitto tra i due processi. Il problema è ulteriormente aggravato dall'implementazione del calcolo distribuito da parte dei motori di ricerca per gestire più dati.
Tipi di indice
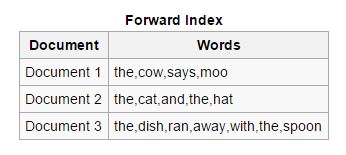
Avanti: In questo tipo di indici, tutte le parole chiave presenti in un documento sono memorizzate in un elenco. L'indice diretto è facile da creare nella fase iniziale dell'indicizzazione poiché consente agli indicizzatori asincroni di collaborare tra loro.
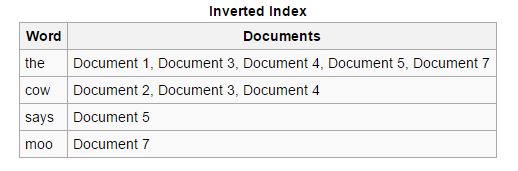
Reverse: gli indici diretti vengono ordinati e convertiti in indici inversi, in cui ogni documento contenente una parola chiave specifica viene unito ad altri documenti contenenti quella parola chiave. Gli indici inversi facilitano il processo di ricerca di documenti rilevanti per una determinata query di ricerca, il che non è il caso degli indici in avanti.

Leggi anche: Cos'è il DNS (Domain Name System) e come funziona?
Analisi di documenti
Detta anche Tokenizzazione, si riferisce alla scomposizione di componenti di un documento come parole chiave (chiamate token), immagini e altri media, in modo che possano essere successivamente inseriti negli indici. Il metodo si concentra fondamentalmente sulla comprensione della lingua madre e sulla previsione delle parole chiave che un utente potrebbe cercare, che servono come base per creare un efficace sistema di indicizzazione web.
Le principali sfide includono trovare i confini delle parole delle parole chiave da estrarre, poiché possiamo vedere che lingue come il cinese e il giapponese generalmente non hanno spazi bianchi nei loro script di lingua. Anche la comprensione dell'ambiguità posseduta da una lingua è motivo di preoccupazione, poiché alcune lingue iniziano a differire leggermente o addirittura considerevolmente con i cambiamenti geografici. Inoltre, l'inefficienza di alcune pagine Web nel non menzionare chiaramente la lingua utilizzata è motivo di preoccupazione e aumenta il carico di lavoro sugli indicizzatori.
I motori di ricerca hanno la capacità di riconoscere vari formati di file ed estrarne con successo i dati, ed è necessario prestare la massima attenzione in questi casi.
I meta tag sono anche molto utili per creare gli indici molto rapidamente, riducono gli sforzi dell'indicizzatore web e alleviano la necessità di analizzare completamente l'intero documento. Troverai i meta tag allegati in fondo a questo articolo.
Ricerca nell'indice
Ora, il motore di ricerca per bambini non è più un bambino, ha imparato, come gattonare e come afferrare le cose in modo rapido ed efficiente, e come sistemare le sue cose in modo sistematico. Supponiamo che il suo amico gli chieda di trovare qualcosa dal suo arrangiamento, cosa farà? Esistono quattro tipi di query di ricerca in uso, sebbene non siano derivate formalmente, ma si sono evolute nel tempo e sono state trovate valide in termini di query di vita reale fatte dagli utenti.
Navigazione: questo termine viene utilizzato per quelle query in cui l'utente desidera accedere a una pagina Web specifica oa un sito Web esistente su Internet. Ad esempio, quando cerchi fossBytes su Google, stai avviando una query di navigazione.
Informativo: questo tipo di query ha migliaia di risultati e copre argomenti generali che migliorano la conoscenza dell'utente. Ad esempio, quando cerchi, ad esempio Steve Jobs, ti verranno presentati tutti i collegamenti rilevanti per Steve Jobs.
Transazionale: le query incentrate sull'intenzione dell'utente di eseguire una determinata azione possono implicare un insieme predefinito di istruzioni. Ad esempio, come trovare il tuo laptop smarrito/rubato?
Connettività: questo tipo di query non viene utilizzato di frequente, si concentrano su come è connesso l'indice creato da un sito Web. Ad esempio, se cerchi, Quante pagine ci sono su Wikipedia?
Google e Bing hanno creato alcuni algoritmi seri che sono abbastanza in grado di determinare i risultati più rilevanti per la tua query. Google afferma di calcolare i risultati della tua ricerca in base a oltre 200 fattori come la qualità del contenuto, nuovo o vecchio, la sicurezza della pagina web e molti altri. Hanno le migliori menti del mondo nominate nei loro laboratori di ricerca, che fanno calcoli difficili e si occupano di formule strabilianti, solo per rendere la ricerca più semplice e veloce per te.
Altre caratteristiche degne di nota*
Ricerca di immagini: sarai sorpreso di conoscere l'ispirazione di Google dietro il loro famoso strumento di ricerca di immagini. J.Lo, sì, hai sentito bene, J.Lo e il suo abito verde Versace(ver-sah-chay) ai Grammy Awards, 2000, sono stati il vero motivo per cui Google è uscito con la sua ricerca di immagini, dato che le persone erano impegnate a cercare su Google suo.
Ha detto Eric Schmidt nel suo scritto intitolato "The Tinkerer's Apprentice", pubblicato il 19 gennaio 2015.
Ricerca vocale: Google è stato il primo a introdurre la ricerca vocale sul suo motore di ricerca dopo molto duro lavoro e successivamente anche altri motori di ricerca l'hanno implementata.
Lotta contro lo spam: i motori di ricerca implementano alcuni algoritmi seri, in modo che possano proteggerti dagli attacchi di spam . Uno spam è fondamentalmente un messaggio o un file che viene diffuso su Internet, magari per pubblicità o per trasmettere virus. Anche in questo caso, i ragazzi di Google informano manualmente il sito Web che ritengono responsabile della diffusione di messaggi di spam su Internet.
Ottimizzazione della posizione: i motori di ricerca sono ora in grado di visualizzare i risultati in base alla posizione dell'utente. Se cerchi Com'è il tempo a Bangalore, le statistiche meteorologiche saranno in riferimento a Bangalore.
Ti capisce meglio: i motori di ricerca moderni sono in grado di comprendere il significato della query dell'utente piuttosto che trovare le parole chiave inserite dall'utente.
Completamento automatico : la possibilità di prevedere la query di ricerca durante la digitazione in base alle ricerche precedenti e alle ricerche effettuate da altri utenti.
Knowledge Graph: questa funzione, fornita da Ricerca Google, mostra la sua capacità di fornire risultati di ricerca basati su persone, luoghi ed eventi della vita reale.
Parental Control: i motori di ricerca consentono ai genitori di piccole dimensioni di controllare ciò che il loro bambino ha fatto su Internet.
* È difficile coprire il vasto elenco di funzionalità fornite da questi potenti motori di ricerca.
Finendo
I motori di ricerca hanno contribuito a semplificarci la vita e il duro lavoro che hanno svolto per sfruttare tutte le informazioni su Internet non ha prezzo. Ma questa esplorazione ha portato all'esposizione del nostro spazio personale su una piattaforma pubblica, e devo dire che è giunto il momento di agitarci sul percorso che abbiamo attraversato così a lungo, a meno che non sia troppo tardi per rivedere le nostre azioni e la nostra vita non sarà che una biennale di imbarazzi. Non possiamo negare il fatto che i motori di ricerca siano ora una parte vitale della nostra doppia personalità digitale. Dobbiamo solo utilizzare la tecnologia che ci è stata data, non permettere che ci renda schiavi nelle catene dei nostri stessi misfatti.
Ok, niente più discorsi emotivi, adora solo la carineria e i talenti di quel motore di ricerca per bambini che ora è diventato un adolescente e ti capisce molto meglio. Google è stato lì per cercare tutto per noi, è Internet per molti di noi e dobbiamo amare le belle esperienze che abbiamo guadagnato utilizzando la Ricerca Google. Oh! Ho dimenticato di menzionare Bing, anche tu sei fantastico. Stai attento, stai al sicuro e cercalo su Google.
Guarda questo video e scopri di più sui motori di ricerca:
Hai mai fatto clic sul pulsante Mi sento fortunato su Ricerca Google. Aprilo e dicci quale doodle ti è piaciuto di più nella sezione commenti qui sotto.