
Come analizzare i dati CSV in Bash
Pubblicato: 2022-09-16
I file CSV (Comma Separated Values) sono uno dei formati più comuni per i dati esportati. Su Linux, possiamo leggere i file CSV usando i comandi Bash. Ma può diventare molto complicato, molto rapidamente. Daremo una mano.
Che cos'è un file CSV?
Un file di valori separati da virgola è un file di testo che contiene dati tabulati. CSV è un tipo di dati delimitati. Come suggerisce il nome, una virgola " , " viene utilizzata per separare ogni campo di dati, o valore, dai suoi vicini.
CSV è ovunque. Se un'applicazione dispone di funzioni di importazione ed esportazione, supporterà quasi sempre CSV. I file CSV sono leggibili dall'uomo. Puoi guardarci dentro con meno, aprirli in qualsiasi editor di testo e spostarli da un programma all'altro. Ad esempio, puoi esportare i dati da un database SQLite e aprirlo in LibreOffice Calc.
Tuttavia, anche CSV può diventare complicato. Vuoi avere una virgola in un campo dati? Questo campo deve essere racchiuso tra virgolette " " ". Per includere le virgolette in un campo, ciascuna virgoletta deve essere inserita due volte.
Ovviamente, se stai lavorando con CSV generato da un programma o uno script che hai scritto, è probabile che il formato CSV sia semplice e diretto. Se sei costretto a lavorare con formati CSV più complessi, essendo Linux Linux, ci sono soluzioni che possiamo usare anche per questo.
Alcuni dati di esempio
Puoi facilmente generare alcuni dati CSV di esempio, utilizzando siti come Online Data Generator. Puoi definire i campi che desideri e scegliere quante righe di dati desideri. I tuoi dati vengono generati utilizzando valori fittizi realistici e scaricati sul tuo computer.
Abbiamo creato un file contenente 50 righe di informazioni fittizie sui dipendenti:
- id : un valore intero univoco semplice.
- nome : il nome della persona.
- cognome : il cognome della persona.
- job-title : il titolo di lavoro della persona.
- indirizzo e-mail : l'indirizzo e-mail della persona.
- branch : il ramo aziendale in cui lavorano.
- state : lo stato in cui si trova la filiale.
Alcuni file CSV hanno una riga di intestazione che elenca i nomi dei campi. Il nostro file di esempio ne ha uno. Ecco la parte superiore del nostro file:
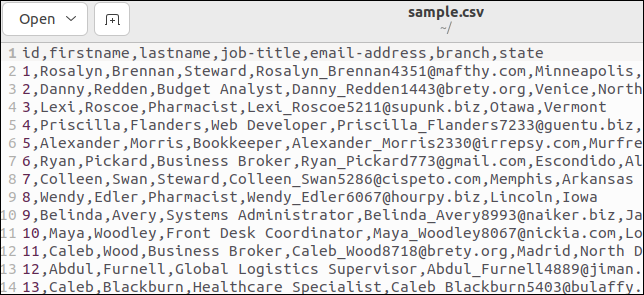
La prima riga contiene i nomi dei campi come valori separati da virgole.
Analisi dei dati Forma il file CSV
Scriviamo uno script che leggerà il file CSV ed estrarrà i campi da ogni record. Copia questo script in un editor e salvalo in un file chiamato "field.sh".
#! /bin/bash while IFS="," read -r id nome cognome jobtitle email branch state fare echo "ID record: $id" echo "Nome: $nome" echo " Cognome: $cognome" echo "Titolo lavoro: $titolo lavoro" echo "Aggiungi email: $email" echo " Ramo: $ramo" echo "Stato: $stato" eco "" done <(tail -n +2 sample.csv)
C'è un bel po' di cose nel nostro piccolo copione. Analizziamolo.

Stiamo usando un ciclo while . Finché la condizione del ciclo while si risolve in true, il corpo del ciclo while verrà eseguito. Il corpo del ciclo è abbastanza semplice. Una raccolta di istruzioni echo viene utilizzata per stampare i valori di alcune variabili nella finestra del terminale.
La condizione del ciclo while è più interessante del corpo del ciclo. Specifichiamo che una virgola deve essere utilizzata come separatore di campo interno, con l'istruzione IFS="," . L'IFS è una variabile d'ambiente. Il comando read fa riferimento al suo valore durante l'analisi di sequenze di testo.
Stiamo usando l'opzione -r (conserva barre inverse) del comando di read per ignorare eventuali barre inverse che potrebbero essere presenti nei dati. Saranno trattati come caratteri normali.
Il testo analizzato dal comando di read viene archiviato in una serie di variabili denominate in base ai campi CSV. Avrebbero potuto essere nominati altrettanto facilmente field1, field2, ... field7 , ma i nomi significativi semplificano la vita.
I dati sono ottenuti come output dal comando tail . Stiamo usando tail perché ci offre un modo semplice per saltare la riga di intestazione del file CSV. L'opzione -n +2 (numero riga) dice a tail di iniziare a leggere dalla riga numero due.
Il costrutto <(...) è chiamato sostituzione di processo. Fa sì che Bash accetti l'output di un processo come se provenisse da un descrittore di file. Questo viene quindi reindirizzato nel ciclo while , fornendo il testo che il comando di read analizzerà.
Rendi eseguibile lo script usando il comando chmod . Dovrai farlo ogni volta che copi uno script da questo articolo. Sostituire in ogni caso il nome dello script appropriato.
chmod +x campo.sh

Quando eseguiamo lo script, i record vengono suddivisi correttamente nei loro campi costitutivi, con ogni campo memorizzato in una variabile diversa.
./campo.sh
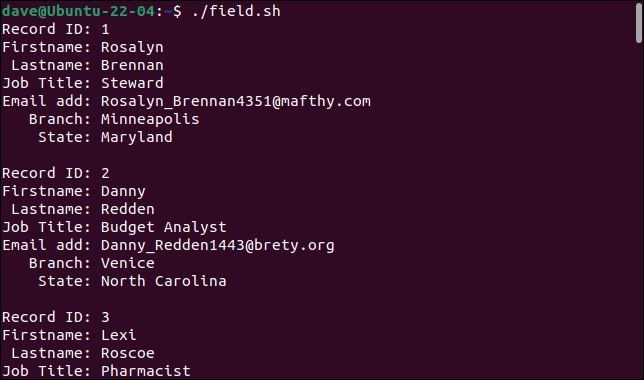
Ogni record viene stampato come un insieme di campi.
Selezione dei campi
Forse non vogliamo o non dobbiamo recuperare ogni campo. Possiamo ottenere una selezione di campi incorporando il comando di cut .
Questo script è chiamato "select.sh".
#!/bin/bash while IFS="," read -r id stato del ramo del titolo di lavoro fare echo "ID record: $id" echo "Titolo lavoro: $titolo lavoro" echo " Ramo: $ramo" echo "Stato: $stato" eco "" done <(cut -d "," -f1,4,6,7 sample.csv | tail -n +2)
Abbiamo aggiunto il comando cut nella clausola di sostituzione del processo. Stiamo usando l'opzione -d (delimitatore) per dire a cut di usare le virgole “ , ” come delimitatore. L'opzione -f (campo) dice a cut che vogliamo i campi uno, quattro, sei e sette. Questi quattro campi vengono letti in quattro variabili, che vengono stampate nel corpo del ciclo while .
Questo è ciò che otteniamo quando eseguiamo lo script.
./seleziona.sh
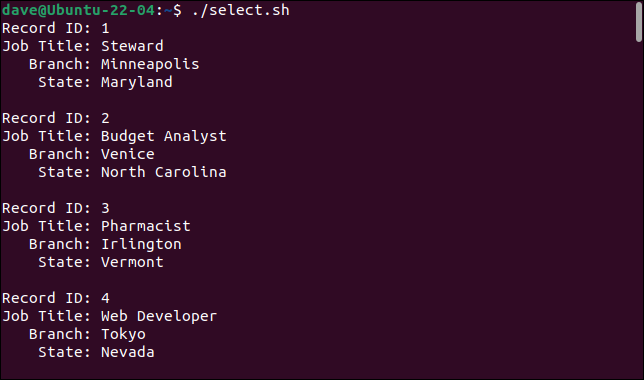
Aggiungendo il comando cut , possiamo selezionare i campi che vogliamo e ignorare quelli che non vogliamo.
Fin qui tutto bene. Ma…
Se il CSV con cui hai a che fare non è complicato senza virgole o virgolette nei dati dei campi, ciò che abbiamo trattato probabilmente soddisferà le tue esigenze di analisi CSV. Per mostrare i problemi che possiamo incontrare, abbiamo modificato un piccolo campione di dati in modo che assomigli a questo.
id,nome,cognome,titolo del lavoro,indirizzo e-mail,filiale,stato 1,Rosalyn,Brennan,"Steward, Senior",Rosalyn_Brennan4351@mafthy.com,Minneapolis,Maryland 2,Danny,Redden,"Analista ""Budget""",Danny_Redden1443@brety.org,Venezia,Carolina del Nord 3,Lexi,Roscoe,Farmacista,,Irlington,Vermont
- Il record uno ha una virgola nel campo
job-title, quindi il campo deve essere racchiuso tra virgolette. - Il record due ha una parola racchiusa tra due serie di virgolette nel campo
jobs-title. - Il record tre non ha dati nel campo
email-address.
Questi dati sono stati salvati come "sample2.csv". Modifica il tuo script "field.sh" per chiamare "sample2.csv" e salvalo come "field2.sh".
#! /bin/bash while IFS="," read -r id nome cognome jobtitle email branch state fare echo "ID record: $id" echo "Nome: $nome" echo " Cognome: $cognome" echo "Titolo lavoro: $titolo lavoro" echo "Aggiungi email: $email" echo " Ramo: $ramo" echo "Stato: $stato" eco "" fatto < <(tail -n +2 sample2.csv)
Quando eseguiamo questo script, possiamo vedere delle crepe che appaiono nei nostri semplici parser CSV.

./field2.sh

Il primo record divide il campo del titolo di lavoro in due campi, trattando la seconda parte come l'indirizzo e-mail. Ogni campo dopo questo viene spostato di un posto a destra. L'ultimo campo contiene sia il branch che i valori di state .
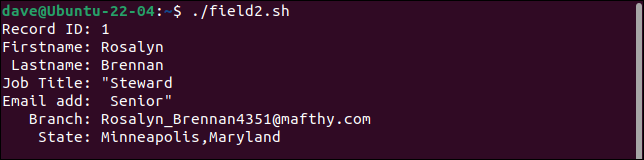
Il secondo record conserva tutte le virgolette. Dovrebbe contenere solo una coppia di virgolette attorno alla parola "Budget".
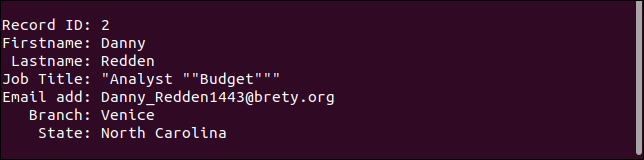
Il terzo record gestisce effettivamente il campo mancante come dovrebbe. Manca l'indirizzo email, ma tutto il resto è come dovrebbe essere.

Controintuitivamente, per un semplice formato di dati, è molto difficile scrivere un robusto parser CSV generico. Strumenti come awk ti permetteranno di avvicinarti, ma ci sono sempre casi limite ed eccezioni che sfuggono.

Cercare di scrivere un parser CSV infallibile probabilmente non è il modo migliore per procedere. Un approccio alternativo, soprattutto se stai lavorando per una scadenza di qualche tipo, utilizza due strategie diverse.
Uno consiste nell'utilizzare uno strumento appositamente progettato per manipolare ed estrarre i dati. Il secondo è disinfettare i tuoi dati e sostituire scenari problematici come virgole e virgolette incorporate. I tuoi semplici parser Bash possono quindi far fronte al CSV compatibile con Bash.
Il csvkit Toolkit
Il CSV toolkit csvkit è una raccolta di utilità appositamente creata per aiutare a lavorare con i file CSV. Dovrai installarlo sul tuo computer.
Per installarlo su Ubuntu, usa questo comando:
sudo apt install csvkit

Per installarlo su Fedora, devi digitare:
sudo dnf install python3-csvkit

Su Manjaro il comando è:
sudo pacman -S csvkit

Se gli passiamo il nome di un file CSV, l'utilità csvlook mostra una tabella che mostra il contenuto di ogni campo. Il contenuto del campo viene visualizzato per mostrare cosa rappresentano i contenuti del campo, non come sono archiviati nel file CSV.
Proviamo csvlook con il nostro file problematico "sample2.csv".
csvlook sample2.csv
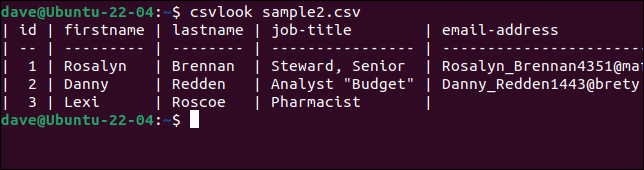
Tutti i campi sono visualizzati correttamente. Questo dimostra che il problema non è il CSV. Il problema è che i nostri script sono troppo semplicistici per interpretare correttamente il CSV.
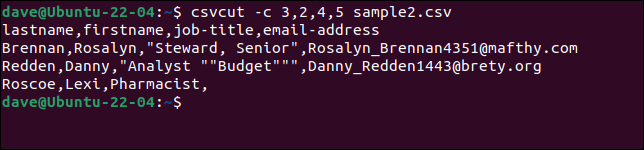
Per selezionare colonne specifiche, utilizzare il comando csvcut . L'opzione -c (colonna) può essere utilizzata con nomi di campo o numeri di colonna o una combinazione di entrambi.
Supponiamo di dover estrarre il nome e il cognome, i titoli di lavoro e gli indirizzi e-mail da ciascun record, ma vogliamo che l'ordine dei nomi sia "cognome, nome". Tutto quello che dobbiamo fare è mettere i nomi dei campi oi numeri nell'ordine in cui li vogliamo.
Questi tre comandi sono tutti equivalenti.
csvcut -c cognome, nome, titolo del lavoro, indirizzo e-mail sample2.csv
csvcut -c cognome, nome,4,5 sample2.csv
csvcut -c 3,2,4,5 sample2.csv
Possiamo aggiungere il comando csvsort per ordinare l'output in base a un campo. Utilizziamo l'opzione -c (colonna) per specificare la colonna in base alla quale eseguire l'ordinamento e l'opzione -r (inversa) per ordinare in ordine decrescente.
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r
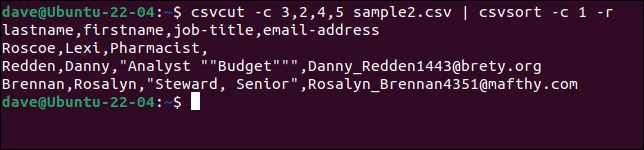
Per rendere l'output più bello possiamo alimentarlo tramite csvlook .
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r | csvlook
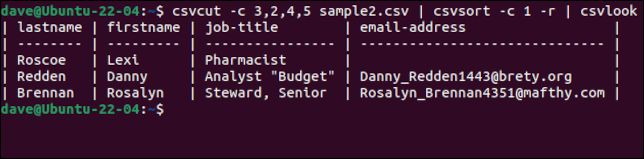
Un bel tocco è che, anche se i record sono ordinati, la riga di intestazione con i nomi dei campi viene mantenuta come prima riga. Una volta che siamo felici di avere i dati nel modo desiderato, possiamo rimuovere csvlook dalla catena di comando e creare un nuovo file CSV reindirizzando l'output in un file.
Abbiamo aggiunto più dati a "sample2.file", rimosso il comando csvsort e creato un nuovo file chiamato "sample3.csv".
csvcut -c 3,2,4,5 sample2.csv > sample3.csv

Un modo sicuro per disinfettare i dati CSV
Se apri un file CSV in LibreOffice Calc, ogni campo verrà inserito in una cella. Puoi utilizzare la funzione trova e sostituisci per cercare le virgole. Potresti sostituirli con "niente" in modo che svaniscano, o con un carattere che non influisca sull'analisi CSV, come un punto e virgola " ; " Per esempio.
Non vedrai le virgolette intorno ai campi tra virgolette. Le uniche virgolette che vedrai sono le virgolette incorporate all'interno dei dati del campo. Questi sono visualizzati come virgolette singole. Trovarli e sostituirli con un unico apostrofo “ ' ” sostituiranno le virgolette doppie nel file CSV.
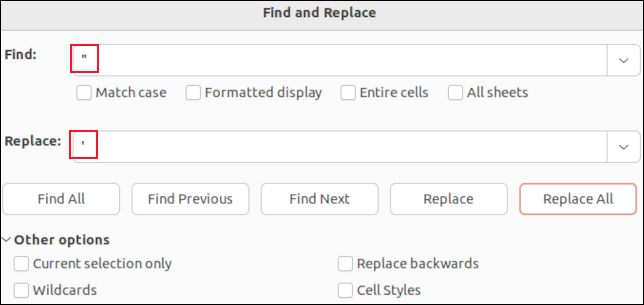
Trovare e sostituire in un'applicazione come LibreOffice Calc significa che non è possibile eliminare accidentalmente nessuna delle virgole del separatore di campo, né eliminare le virgolette attorno ai campi tra virgolette. Cambierai solo i valori dei dati dei campi.
Abbiamo modificato tutte le virgole nei campi con punto e virgola e tutte le virgolette incorporate con apostrofi e abbiamo salvato le modifiche.
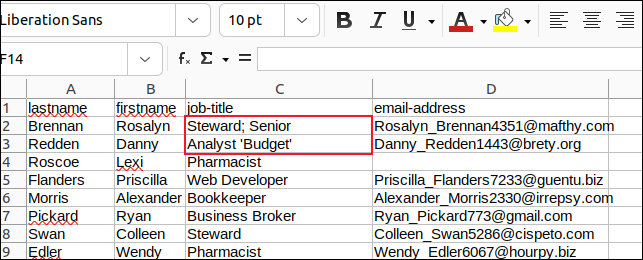
Abbiamo quindi creato uno script chiamato "field3.sh" per analizzare "sample3.csv".
#! /bin/bash while IFS="," read -r cognome nome nome lavoro e-mail fare echo " Cognome: $cognome" echo "Nome: $nome" echo "Titolo lavoro: $titolo lavoro" echo "Aggiungi email: $email" eco "" done <(tail -n +2 sample3.csv)
Vediamo cosa otteniamo quando lo eseguiamo.
./field3.sh
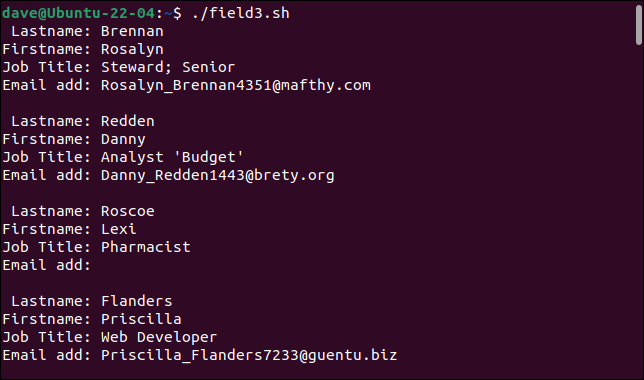
Il nostro semplice parser ora può gestire i nostri record precedentemente problematici.
Vedrai un sacco di CSV
CSV è probabilmente la cosa più vicina a una lingua comune per i dati delle applicazioni. La maggior parte delle applicazioni che gestiscono una qualche forma di dati supporta l'importazione e l'esportazione di CSV. Sapere come gestire CSV, in modo realistico e pratico, ti sarà di grande aiuto.
CORRELATI: 9 esempi di script Bash per iniziare su Linux