
Come eseguire l'OCR dalla riga di comando di Linux utilizzando Tesseract
Pubblicato: 2022-01-29
Puoi estrarre il testo dalle immagini sulla riga di comando di Linux utilizzando il motore OCR Tesseract. È veloce, preciso e funziona in circa 100 lingue. Ecco come usarlo.
Riconoscimento ottico dei caratteri
Il riconoscimento ottico dei caratteri (OCR) è la capacità di guardare e trovare le parole in un'immagine, quindi estrarle come testo modificabile. Questo semplice compito per gli esseri umani è molto difficile da fare per i computer. I primi sforzi sono stati goffi, per non dire altro. I computer erano spesso confusi se il carattere o le dimensioni non erano di gradimento del software OCR.
Tuttavia, i pionieri in questo campo erano ancora tenuti in grande considerazione. Se hai perso la copia elettronica di un documento, ma hai ancora una versione stampata, l'OCR potrebbe ricreare una versione elettronica modificabile. Anche se i risultati non erano accurati al 100%, questo è stato comunque un grande risparmio di tempo.
Con un po' di riordino manuale, avresti riavuto il tuo documento. Le persone hanno perdonato gli errori commessi perché hanno compreso la complessità del compito che deve affrontare un pacchetto OCR. Inoltre, era meglio che riscrivere l'intero documento.
Da allora le cose sono notevolmente migliorate. L'applicazione Tesseract OCR, scritta da Hewlett Packard, iniziò negli anni '80 come applicazione commerciale. Era open source nel 2005 e ora è supportato da Google. Ha capacità multilingua, è considerato uno dei sistemi OCR più accurati disponibili e puoi usarlo gratuitamente.
Installazione di Tesseract OCR
Per installare Tesseract OCR su Ubuntu, usa questo comando:
sudo apt-get install tesseract-ocr

Su Fedora, il comando è:
sudo dnf installa tesseract

Su Manjaro, devi digitare:
sudo pacman -Syu tesseract

Utilizzando Tesseract OCR
Presenteremo una serie di sfide a Tesseract OCR. La nostra prima immagine che contiene testo è un estratto dal considerando 63 del Regolamento generale sulla protezione dei dati. Vediamo se l'OCR può leggere questo (e rimanere sveglio).

È un'immagine complicata perché ogni frase inizia con un debole numero in apice, tipico dei documenti legislativi.
Dobbiamo fornire al comando tesseract alcune informazioni, tra cui:
- Il nome del file immagine che vogliamo che elabori.
- Il nome del file di testo che creerà per contenere il testo estratto. Non è necessario fornire l'estensione del file (sarà sempre .txt). Se esiste già un file con lo stesso nome, verrà sovrascritto.
- Possiamo usare l'opzione
--dpiper dire atesseractqual è la risoluzione dei punti per pollice (dpi) dell'immagine. Se non forniamo un valore dpi,tesseractproverà a capirlo.
Il nostro file immagine si chiama "recital-63.png" e la sua risoluzione è di 150 dpi. Creeremo da esso un file di testo chiamato "recital.txt".
Il nostro comando si presenta così:
tesseract considerando-63.png considerando --dpi 150

I risultati sono molto buoni. L'unico problema sono gli apici: erano troppo deboli per essere letti correttamente. Una buona qualità dell'immagine è fondamentale per ottenere buoni risultati.

tesseract ha interpretato i numeri in apice come virgolette (“) e simboli di grado (°), ma il testo vero e proprio è stato estratto perfettamente (il lato destro dell'immagine doveva essere tagliato per adattarlo qui).
Il carattere finale è un byte con il valore esadecimale 0x0C, che è un ritorno a capo.
Di seguito è riportata un'altra immagine con testo di diverse dimensioni, sia in grassetto che in corsivo.

Il nome di questo file è "bold-italic.png". Vogliamo creare un file di testo chiamato "bold.txt", quindi il nostro comando è:
tesseract bold-italic.png bold --dpi 150

Questo non ha posto alcun problema e il testo è stato estratto perfettamente.

Utilizzo di lingue diverse
Tesseract OCR supporta circa 100 lingue. Per utilizzare una lingua, devi prima installarla. Quando trovi la lingua che desideri utilizzare nell'elenco, prendi nota della sua abbreviazione. Installeremo il supporto per il gallese. La sua abbreviazione è "cym", che è l'abbreviazione di "Cymru", che significa gallese.
Il pacchetto di installazione si chiama "tesseract-ocr-" con l'abbreviazione della lingua contrassegnata alla fine. Per installare il file della lingua gallese in Ubuntu, useremo:
sudo apt-get install tesseract-ocr-cym


L'immagine con il testo è sotto. È la prima strofa dell'inno nazionale gallese.

Vediamo se Tesseract OCR è all'altezza della sfida. Useremo l'opzione -l (lingua) per far conoscere a tesseract la lingua in cui vogliamo lavorare:
tesseract hen-wlad-fy-nhadau.png inno -l cym --dpi 150

tesseract si adatta perfettamente, come mostrato nel testo estratto di seguito. Da iawn , Tesseract OCR.

Se il tuo documento contiene due o più lingue (come un dizionario gallese-inglese, ad esempio), puoi utilizzare un segno più ( + ) per dire a tesseract di aggiungere un'altra lingua, in questo modo:
tesseract image.png file di testo -l eng+cym+fra
Utilizzo di Tesseract OCR con i PDF
Il comando tesseract è progettato per funzionare con i file di immagine, ma non è in grado di leggere i PDF. Tuttavia, se è necessario estrarre del testo da un PDF, è possibile utilizzare prima un'altra utilità per generare una serie di immagini. Una singola immagine rappresenterà una singola pagina del PDF.
L'utilità pdftppm di cui hai bisogno dovrebbe essere già installata sul tuo computer Linux. Il PDF che useremo per il nostro esempio è una copia del documento fondamentale di Alan Turing sull'intelligenza artificiale, "Computing Machinery and Intelligence".

Usiamo l'opzione -png per specificare che vogliamo creare file PNG. Il nome del file del nostro PDF è "turing.pdf". Chiameremo i nostri file immagine "turing-01.png", "turing-02.png" e così via:
pdftoppm -png turing.pdf turing

Per eseguire tesseract su ciascun file immagine utilizzando un singolo comando, è necessario utilizzare un ciclo for. Per ciascuno dei nostri file "turing- nn .png", eseguiamo tesseract e creiamo un file di testo chiamato "text-" più "turing- nn " come parte del nome del file immagine:
per i in turing-??.png; do tesseract "$i" "testo-$i" -l eng; fatto;

Per combinare tutti i file di testo in uno, possiamo usare cat :
cat text-turing* > complete.txt

Allora, come è andata? Molto bene, come puoi vedere qui sotto. La prima pagina sembra piuttosto impegnativa, però. Ha diversi stili e dimensioni del testo e decorazioni. C'è anche una "filigrana" verticale sul bordo destro della pagina.
Tuttavia, l'output è vicino all'originale. Ovviamente la formattazione è andata persa, ma il testo è corretto.
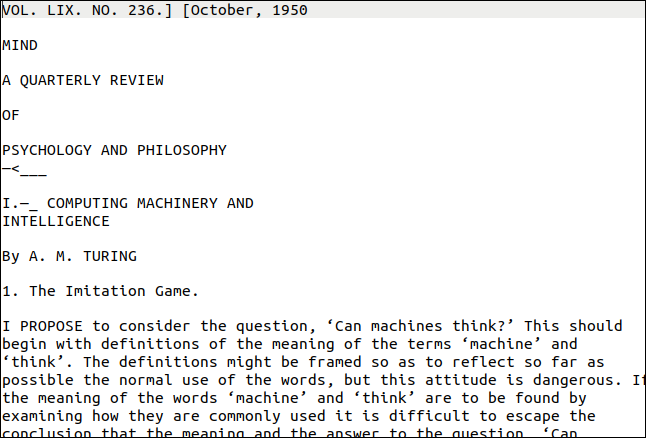
La filigrana verticale è stata trascritta come una linea di parole senza senso in fondo alla pagina. Il testo era troppo piccolo per essere letto accuratamente da tesseract , ma sarebbe stato abbastanza facile trovarlo ed eliminarlo. Il risultato peggiore sarebbero stati i caratteri vaganti alla fine di ogni riga.
Curiosamente, le singole lettere all'inizio dell'elenco di domande e risposte a pagina due sono state ignorate. La sezione del PDF è mostrata di seguito.

Come puoi vedere di seguito, le domande rimangono, ma la "Q" e la "A" all'inizio di ogni riga sono andate perse.

Anche i diagrammi non verranno trascritti correttamente. Diamo un'occhiata a cosa succede quando proviamo ad estrarre quello mostrato di seguito dal PDF di Turing.

Come puoi vedere nel nostro risultato di seguito, i caratteri sono stati letti, ma il formato del diagramma è stato perso.

Ancora una volta, tesseract lottato con le piccole dimensioni dei pedici e sono stati resi in modo errato.
In tutta onestà, però, è stato comunque un buon risultato. Non siamo stati in grado di estrarre un testo semplice, ma questo esempio è stato scelto deliberatamente perché presentava una sfida.
Una buona soluzione quando ne hai bisogno
L'OCR non è qualcosa che dovrai usare quotidianamente. Tuttavia, quando se ne presenta la necessità, è bene sapere di avere a disposizione uno dei migliori motori OCR.