
cURL vs. wget in Linux: qual è la differenza?
Pubblicato: 2022-07-13
Se chiedi a un gruppo di utenti Linux con cosa scaricano i file, alcuni diranno wget e altri cURL . Qual è la differenza, ed è uno migliore dell'altro?
È iniziato con la connettività
Già negli anni '60 i ricercatori governativi stavano iniziando a collegare reti diverse, dando vita a reti interconnesse . Ma la nascita di Internet come la conosciamo è avvenuta il 1 gennaio 1983 quando è stato implementato il protocollo TCP/IP. Questo era l'anello mancante. Ha consentito a computer e reti disparate di comunicare utilizzando uno standard comune.
Nel 1991, il CERN ha rilasciato il suo software World Wide Web che utilizzava internamente da alcuni anni. L'interesse per questa sovrapposizione visiva per Internet è stato immediato e diffuso. Alla fine del 1994 c'erano 10.000 server web e 10 milioni di utenti.

Queste due pietre miliari, Internet e Web, rappresentano facce molto diverse della connettività. Ma condividono anche molte delle stesse funzionalità.
Connettività significa proprio questo. Ti stai connettendo a un dispositivo remoto, come un server. E ti stai connettendo ad esso perché c'è qualcosa su di esso di cui hai bisogno o che desideri. Ma come recuperare quella risorsa ospitata in remoto sul tuo computer locale, dalla riga di comando di Linux?
Nel 1996 sono nate due utility che consentono di scaricare risorse ospitate in remoto. Sono wget , che è stato rilasciato a gennaio, e cURL , che è stato rilasciato a dicembre. Entrambi operano sulla riga di comando di Linux. Entrambi si connettono a server remoti ed entrambi recuperano materiale per te.
Ma questo non è solo il solito caso di Linux che fornisce due o più strumenti per fare lo stesso lavoro. Queste utilità hanno scopi diversi e specializzazioni diverse. Il problema è che sono abbastanza simili da creare confusione su quale usare e quando.
Considera due chirurghi. Probabilmente non vuoi che un chirurgo oculista esegua l'intervento di bypass cardiaco, né vuoi che il chirurgo cardiaco faccia l'operazione di cataratta. Sì, sono entrambi professionisti medici altamente qualificati, ma ciò non significa che si sostituiscono l'uno con l'altro.
Lo stesso vale per wget e cURL .
Scopi diversi, caratteristiche diverse, alcune sovrapposizioni
La "w" nel comando wget è un indicatore dello scopo previsto. Il suo scopo principale è scaricare pagine Web o persino interi siti Web. La sua pagina man lo descrive come un'utilità per scaricare file dal Web utilizzando i protocolli HTTP, HTTPS e FTP.
Al contrario, cURL funziona con 26 protocolli, inclusi SCP, SFTP, SMSB e HTTPS. La sua pagina man dice che è uno strumento per il trasferimento di dati da o verso un server. Non è su misura per funzionare con i siti Web, in particolare. È pensato per interagire con server remoti, utilizzando uno dei numerosi protocolli Internet che supporta.
Quindi, wget è prevalentemente incentrato sul sito Web, mentre cURL è qualcosa che opera a un livello più profondo, al livello di Internet semplice.
wget è in grado di recuperare pagine Web e può navigare ricorsivamente intere strutture di directory sui server Web per scaricare interi siti Web. È anche in grado di regolare i collegamenti nelle pagine recuperate in modo che puntino correttamente alle pagine Web sul computer locale e non alle loro controparti sul server Web remoto.
cURL ti consente di interagire con il server remoto. Può caricare file e recuperarli. cURL funziona con i proxy SOCKS4 e SOCKS5 e HTTPS al proxy. Supporta la decompressione automatica di file compressi nei formati GZIP, BROTLI e ZSTD. cURL ti consente anche di scaricare più trasferimenti in parallelo.
La sovrapposizione tra loro è che wget e cURL ti consentono entrambi di recuperare pagine Web e utilizzare server FTP.
È solo una metrica approssimativa, ma puoi apprezzare i relativi set di funzionalità dei due strumenti osservando la lunghezza delle loro pagine man . Sulla nostra macchina di prova, la pagina man per wget è lunga 1433 righe. La pagina man di cURL è di ben 5296 righe.
Una rapida occhiata a wget
Poiché wget fa parte del progetto GNU, dovresti trovarlo preinstallato su tutte le distribuzioni Linux. Usarlo è semplice, soprattutto per i suoi usi più comuni: scaricare pagine Web o file.

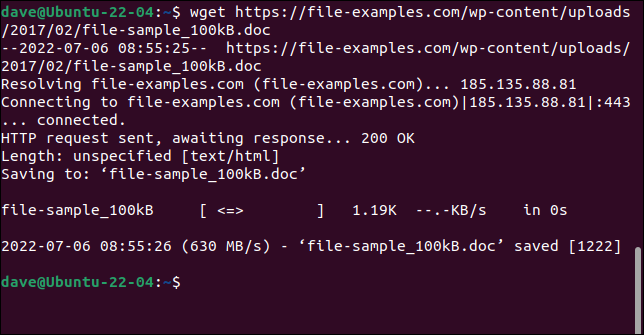
Basta usare il comando wget con l'URL della pagina Web o del file remoto.
wget https://file-examples.com/wp-content/uploads/2017/02/file-sample_100kB.doc

Il file viene recuperato e salvato sul tuo computer con il suo nome originale.
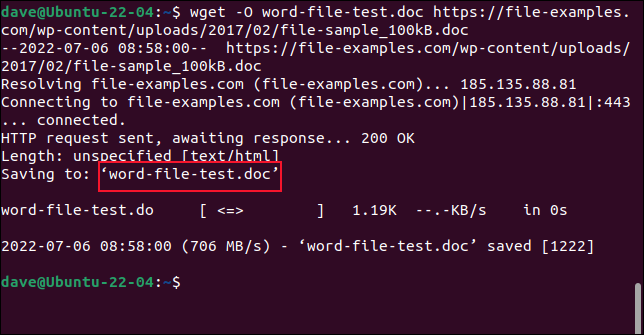
Per salvare il file con un nuovo nome, utilizzare l'opzione -O (documento di output).
wget -O word-file-test.doc https://file-examples.com/wp-content/uploads/2017/02/file-sample_100kB.doc

Il file recuperato viene salvato con il nome che abbiamo scelto.
Non utilizzare l'opzione -O durante il recupero di siti Web. In tal caso, tutti i file recuperati vengono aggiunti in uno.
Per recuperare un intero sito Web, utilizzare l'opzione -m (mirror) e l'URL della home page del sito Web. Ti consigliamo inoltre di utilizzare --page-requisites per assicurarti che anche tutti i file di supporto necessari per eseguire correttamente il rendering delle pagine Web vengano scaricati. L'opzione --convert-links regola i collegamenti nel file recuperato in modo che puntino alle destinazioni corrette sul computer locale anziché a posizioni esterne sul sito Web.
CORRELATI: Come utilizzare wget, lo strumento di download della riga di comando definitivo
Una rapida occhiata a cURL
cURL è un progetto open source indipendente. È preinstallato su Manjaro 21 e Fedora 36 ma doveva essere installato su Ubuntu 21.04.
Questo è il comando per installare cURL su Ubuntu.
sudo apt install curl

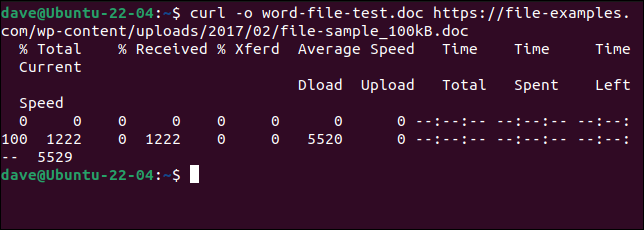
Per scaricare lo stesso file che abbiamo fatto con wget e salvarlo con lo stesso nome, dobbiamo usare questo comando. Si noti che l'opzione -o (output) è minuscola con cURL .
curl -o word-file-test.doc https://file-examples.com/wp-content/uploads/2017/02/file-sample_100kB.doc

Il file viene scaricato per noi. Durante il download viene visualizzata una barra di avanzamento ASCII.
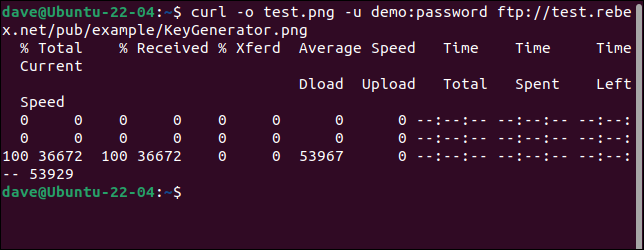
Per connettersi a un server FTP e scaricare un file, utilizzare l'opzione -u (utente) e fornire una coppia nome utente e password, come questa:
curl -o test.png -u demo:password ftp://test.rebex.net/pub/example/KeyGenerator.png

Questo scarica e rinomina un file da un server FTP di prova.
CORRELATI: Come utilizzare curl per scaricare file dalla riga di comando di Linux
Non esiste il meglio
È impossibile rispondere "Quale dovrei usare" senza chiedere "Cosa stai cercando di fare?"
Una volta capito cosa fanno wget e cURL , ti renderai conto che non sono in competizione. Non soddisfano lo stesso requisito e non stanno cercando di fornire la stessa funzionalità.
Il download di pagine Web e siti Web è dove risiede la superiorità di wget . Se è quello che stai facendo, usa wget . Per qualsiasi altra cosa, ad esempio il caricamento o l'utilizzo di una moltitudine di altri protocolli, utilizza cURL .