
Bagaimana Mesin Pencari Bekerja dan Membuat Hidup Anda Lebih Mudah?
Diterbitkan: 2015-11-06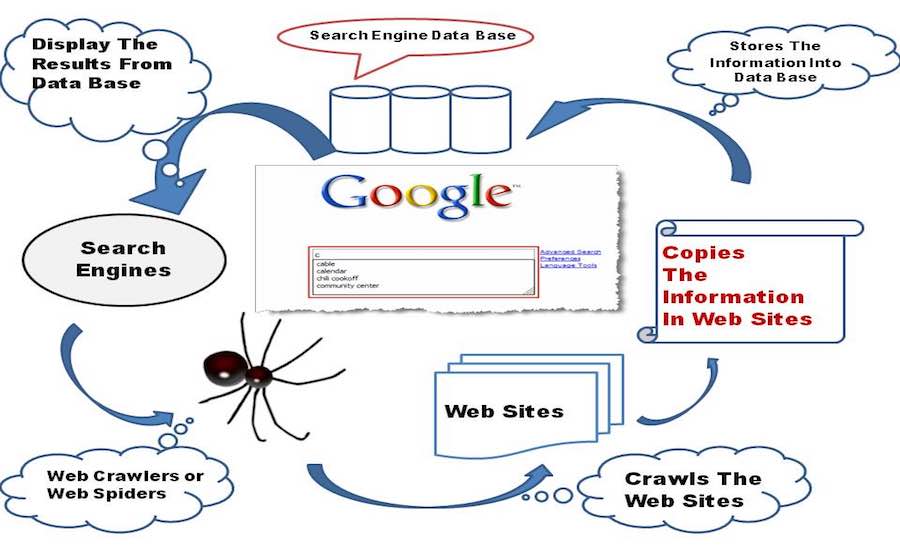 Short Bytes: Search Engine adalah perangkat lunak yang memungkinkan tampilan hasil halaman web yang relevan berdasarkan input permintaan pencarian dengan menggunakan Perayapan Web dan Pengindeksan Web, beberapa formula gemuk dan algoritme cerdas untuk mengumpulkan data yang sesuai.
Short Bytes: Search Engine adalah perangkat lunak yang memungkinkan tampilan hasil halaman web yang relevan berdasarkan input permintaan pencarian dengan menggunakan Perayapan Web dan Pengindeksan Web, beberapa formula gemuk dan algoritme cerdas untuk mengumpulkan data yang sesuai.
Bagaimana Google memberikan Anda hasil terbaik dalam sekejap mata? Sebenarnya, tidak masalah sampai Google, Bing ada di sana. Skenarionya akan sangat berbeda jika tidak ada Google, Bing, atau Yahoo. Mari kita selami dunia mesin pencari dan lihat, bagaimana mesin pencari bekerja.
Mengintip ke dalam sejarah
Dongeng mesin pencari dimulai pada 1990-an ketika Tim Berners-Lee biasa mendaftarkan setiap server web baru yang online, ke daftar yang dikelola oleh server web CERN. Sampai September, 93, tidak ada mesin pencari di internet tetapi hanya beberapa alat yang mampu memelihara database nama file. Archie, Veronica, Jughead adalah peserta pertama dalam kategori ini.
Oscar Nierstrasz dari Universitas Jenewa diakreditasi untuk mesin pencari pertama yang muncul, bernama W3Catalog. Dia melakukan beberapa skrip Perl yang serius dan akhirnya keluar dengan mesin pencari pertama di dunia pada tanggal 3 September 1993. Selanjutnya, tahun 1993 melihat munculnya banyak mesin pencari lainnya. JumpStation oleh Jonathon Fletcher, AliWeb, WWW Worm, dll. Yahoo! diluncurkan pada tahun 1995 sebagai direktori web, tetapi mulai menggunakan pencarian mesin Inktomi dari tahun 2000 dan kemudian bergeser ke Microsoft Bing pada tahun 2009.
Sekarang, berbicara tentang nama yang merupakan sinonim utama untuk istilah mesin pencari, Google Search, adalah sebuah proyek penelitian untuk dua lulusan Stanford, Larry Page dan Sergy Brin, yang memulai jejak kaki pada Maret 1995. Kerja Google awalnya terinspirasi dengan metode back-linking Page yang melakukan perhitungan berdasarkan berapa banyak backlink yang berasal dari sebuah halaman web, sehingga dapat mengukur pentingnya halaman tersebut di World Wide Web. “Saran terbaik yang pernah saya dapatkan”, kata Page, sambil mengenang, bagaimana supervisornya Terry Winograd mendukung idenya. Dan sejak itu, Google tidak pernah melihat ke belakang.
Semuanya dimulai dengan merangkak
Mesin pencari bayi dalam tahap awal mulai menjelajahi World Wide Web, dengan tangan dan lututnya yang kecil ia menjelajahi setiap tautan lain yang ditemukannya di halaman web dan menyimpannya di basis datanya.
Sekarang, mari kita fokus pada beberapa pemikiran teknis di balik layar, mesin pencari menggabungkan perangkat lunak Web Crawler yang pada dasarnya adalah bot internet yang ditugaskan untuk membuka semua hyperlink yang ada di halaman web dan membuat basis data teks dan metadata dari semua tautan . Ini dimulai dengan serangkaian tautan awal untuk dikunjungi, yang disebut Seeds. Segera setelah melanjutkan dengan mengunjungi tautan tersebut, tambahkan tautan baru di daftar URL yang ada untuk dikunjungi, yang dikenal sebagai Perayapan Perbatasan.
Saat Crawler melintasi tautan, ia mengunduh informasi dari halaman web tersebut untuk dilihat nanti dalam bentuk snapshot, karena mengunduh seluruh halaman web akan membutuhkan banyak data, dan harganya sangat mahal, setidaknya dalam negara seperti India. Dan saya berani bertaruh, jika Google didirikan di India, semua uang mereka akan digunakan untuk membayar tagihan internet. Mudah-mudahan, itu bukan topik yang menjadi perhatian untuk saat ini.
Perayap web menjelajahi halaman web berdasarkan beberapa kebijakan:
Kebijakan Pemilihan: Crawler memutuskan halaman mana yang harus diunduh dan mana yang tidak. Kebijakan pemilihan berfokus pada mengunduh konten halaman web yang paling relevan daripada beberapa data yang tidak penting.
Kebijakan Kunjungan Ulang: Crawler menjadwalkan waktu ketika harus membuka kembali halaman web dan mengedit perubahan dalam basis datanya, berkat sifat dinamis internet yang membuat sangat sulit bagi Crawler untuk tetap diperbarui dengan versi terbaru dari halaman web.
Kebijakan Paralelisasi: Perayap menggunakan beberapa proses sekaligus untuk menjelajahi tautan yang dikenal sebagai Perayapan Terdistribusi, tetapi terkadang ada kemungkinan bahwa proses yang berbeda dapat mengunduh halaman web yang sama, sehingga perayap mempertahankan koordinasi antara semua proses untuk menghilangkan kemungkinan bermuka dua.
Kebijakan Kesopanan: Ketika perayap melintasi situs web, perayap secara bersamaan mengunduh halaman web darinya, sehingga meningkatkan beban server web yang menghosting situs web. Oleh karena itu, istilah "Penundaan Perayapan" diimplementasikan di mana perayap harus menunggu beberapa detik setelah mengunduh beberapa data dari server web, dan diatur oleh Kebijakan Kesopanan.
Baca juga: Cara Membangun Perayap Web Dasar dengan Python
Arsitektur Tingkat Tinggi dari Web Crawler standar:
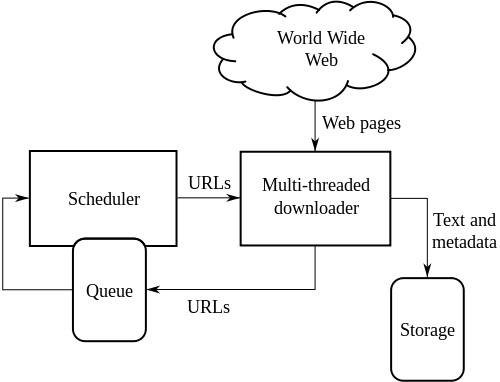
Ilustrasi di atas menggambarkan cara kerja perayap web. Itu membuka daftar tautan awal dan kemudian tautan di dalam tautan itu dan seterusnya.
Wikipedia menulis, peneliti ilmu komputer Vladislav Shkapenyuk dan Torsten Suel mencatat bahwa:
Meskipun cukup mudah untuk membangun perayap lambat yang mengunduh beberapa halaman per detik untuk waktu yang singkat, membangun sistem berkinerja tinggi yang dapat mengunduh ratusan juta halaman selama beberapa minggu menghadirkan sejumlah tantangan dalam desain sistem, I/O dan efisiensi jaringan, serta ketahanan dan pengelolaan.
Mengindeks perayapan
Setelah mesin pencari bayi merangkak di seluruh internet, itu membuat Indeks semua halaman web yang ditemukannya di jalannya. Memiliki indeks jauh lebih baik daripada membuang waktu untuk menemukan kueri pencarian dari tumpukan dokumen berukuran besar, ini akan menghemat waktu dan sumber daya.
Ada banyak faktor yang berkontribusi untuk menciptakan sistem pengindeksan yang efisien untuk mesin pencari. Teknik penyimpanan yang digunakan oleh pengindeks, ukuran indeks, kemampuan untuk menemukan dokumen yang berisi kata kunci yang dicari dengan cepat, dll. adalah faktor yang bertanggung jawab atas efisiensi dan keandalan indeks.
Salah satu hambatan utama dalam membuat indeks web yang sukses adalah tabrakan antara dua proses. Katakanlah satu proses ingin mencari dokumen dan pada saat yang sama proses lain ingin menambahkan dokumen dalam indeks, semacam menciptakan konflik antara dua proses. Masalahnya semakin diperparah dengan penerapan komputasi terdistribusi oleh mesin pencari untuk menangani lebih banyak data.
Jenis Indeks
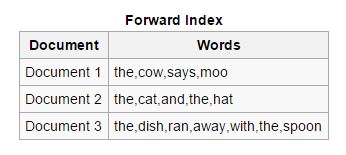
Teruskan: Dalam jenis indeks ini, semua kata kunci yang ada dalam dokumen disimpan dalam daftar. Indeks maju mudah dibuat pada fase awal pengindeksan karena memungkinkan pengindeks asinkron untuk berkolaborasi satu sama lain.
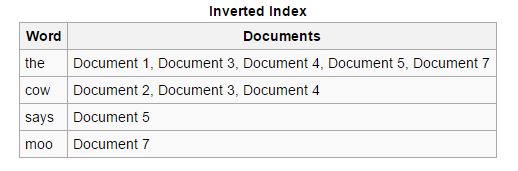
Reverse: Indeks maju diurutkan dan diubah menjadi indeks terbalik, di mana setiap dokumen yang berisi kata kunci tertentu disatukan dengan dokumen lain yang mengandung kata kunci tersebut. Indeks terbalik memudahkan proses menemukan dokumen yang relevan untuk permintaan pencarian tertentu, yang tidak terjadi dengan indeks maju.

Baca Juga: Apa Itu DNS (Domain Name System) dan Bagaimana Cara Kerjanya?
Parsing Dokumen
Disebut juga Tokenization, mengacu pada penguraian komponen dokumen seperti kata kunci (disebut token), gambar dan media lainnya, sehingga nantinya dapat dimasukkan ke dalam indeks. Metode ini pada dasarnya berfokus pada pemahaman bahasa asli dan memprediksi kata kunci yang mungkin dicari pengguna, yang berfungsi sebagai dasar untuk membuat sistem pengindeksan web yang efektif.
Tantangan Utama termasuk menemukan batas kata dari kata kunci yang akan diekstraksi, karena kita dapat melihat bahasa seperti Cina dan Jepang umumnya tidak memiliki spasi putih dalam skrip bahasa mereka. Memahami ambiguitas yang dimiliki oleh suatu bahasa juga menjadi perhatian, karena beberapa bahasa mulai sedikit atau bahkan jauh berbeda dengan perubahan geografis. Selain itu, ketidakefisienan beberapa halaman web untuk tidak secara jelas menyebutkan bahasa yang digunakan juga menjadi perhatian dan meningkatkan beban kerja pada pengindeks.
Mesin pencari memiliki kemampuan untuk mengenali berbagai format file dan berhasil mengekstrak data darinya, dan dalam kasus ini harus sangat berhati-hati.
Meta Tag juga sangat berguna dalam membuat indeks dengan sangat cepat, mereka mengurangi upaya pengindeks web dan memudahkan kebutuhan untuk menguraikan seluruh dokumen secara lengkap. Anda akan menemukan Meta Tag terlampir di bagian bawah artikel ini.
Mencari indeks
Sekarang baby search engine sudah bukan bayi lagi, dia sudah belajar, bagaimana cara merangkak dan mengambil sesuatu dengan cepat dan efisien, dan bagaimana mengatur barang-barangnya secara sistematis. Misalkan, temannya meminta dia untuk menemukan sesuatu dari pengaturannya, apa yang akan dia lakukan? Ada empat jenis kueri penelusuran yang digunakan, meskipun tidak diturunkan secara formal, namun telah berkembang seiring waktu, dan dianggap valid dalam kaitannya dengan kueri kehidupan nyata yang dibuat oleh pengguna.
Navigasi: Istilah ini digunakan untuk kueri di mana pengguna ingin membuka halaman web atau situs web tertentu yang ada di internet. Misalnya, ketika Anda mencari fossBytes di Google, maka Anda memulai Kueri Navigasi.
Informasional: Jenis kueri ini memiliki ribuan hasil dan mencakup topik umum yang meningkatkan pengetahuan pengguna. Misalnya, saat Anda mencari, katakanlah Steve Jobs, Anda akan disajikan semua tautan yang relevan dengan Steve Jobs.
Transaksional: Kueri yang berfokus pada maksud pengguna untuk melakukan tindakan tertentu, mungkin melibatkan serangkaian instruksi yang telah ditentukan sebelumnya. Misalnya, Bagaimana cara menemukan Laptop yang Hilang/Dicuri?
Konektivitas: Jenis kueri ini tidak sering digunakan, mereka berfokus pada seberapa terhubung indeks yang dibuat dari situs web. Misalnya, jika Anda mencari, Berapa banyak halaman yang ada di Wikipedia?
Google dan Bing telah membuat beberapa algoritme serius yang cukup mampu untuk menentukan hasil yang paling relevan untuk kueri Anda. Google mengklaim untuk menghitung hasil pencarian Anda berdasarkan lebih dari 200 faktor seperti kualitas konten, baru atau lama, keamanan halaman web, dan banyak lagi. Mereka memiliki pemikir terhebat di dunia yang ditunjuk di lab Pencarian mereka, yang melakukan perhitungan keras dan menangani formula yang menakjubkan, hanya untuk membuat Pencarian lebih sederhana dan cepat untuk Anda.
Fitur penting lainnya*
Pencarian Gambar: Anda akan terkejut mengetahui inspirasi Google di balik alat pencarian gambar terkenal mereka. J.Lo, ya Anda dengar itu benar, J.Lo dan gaun hijau Versace(ver-sah-chay) di Grammy Awards, 2000, adalah alasan sebenarnya Google keluar dengan pencarian gambarnya, karena orang-orang sibuk mencari-cari di Google dia.
Demikian kata Eric Schmidt dalam tulisannya yang berjudul “The Tinkerer's Apprentice” yang diterbitkan pada 19 Januari 2015.
Pencarian Suara: Google pertama kali memperkenalkan pencarian suara di mesin pencarinya setelah banyak kerja keras dan kemudian mesin pencari lain juga menerapkannya.
Pemberantasan Spam: Mesin telusur menerapkan beberapa algoritme serius, sehingga mereka dapat melindungi Anda dari serangan spam . Spam pada dasarnya adalah pesan atau file yang tersebar di internet, mungkin untuk iklan atau untuk menyebarkan virus. Dalam hal ini juga, orang Google secara manual menginformasikan situs web yang mereka temukan bertanggung jawab untuk menyebarkan pesan spam di internet.
Optimasi Lokasi: Mesin pencari sekarang mampu menampilkan hasil berdasarkan lokasi pengguna. Jika mencari, Seperti apa cuaca di Bengaluru, maka statistik cuaca akan mengacu pada Bengaluru.
Memahami Anda dengan lebih baik: Mesin telusur modern mampu memahami arti kueri pengguna daripada menemukan kata kunci yang dimasukkan oleh pengguna.
Pelengkapan otomatis : Kemampuan untuk memprediksi kueri penelusuran saat Anda mengetik berdasarkan penelusuran sebelumnya dan penelusuran yang dilakukan oleh pengguna lain.
Grafik Pengetahuan: Fitur ini, yang disediakan oleh Google Penelusuran, menunjukkan kemampuannya untuk memberikan hasil penelusuran berdasarkan orang, tempat, dan peristiwa di kehidupan nyata.
Kontrol Orang Tua: Mesin pencari memungkinkan orang tua dari jenis kecil untuk mengontrol apa yang dilakukan anak mereka di internet.
* Sulit untuk menutupi daftar besar fitur yang disediakan oleh mesin pencari yang hebat ini.
Berakhir
Mesin pencari telah berkontribusi untuk membuat hidup kita lebih sederhana dan kerja keras yang telah mereka lakukan untuk memanfaatkan semua informasi di internet sangat berharga. Tetapi penjelajahan ini telah mengarah pada pameran ruang pribadi kita di platform publik, dan saya harus mengatakan, sudah saatnya kita bingung tentang jalan yang telah kita lalui selama ini, kecuali jika sudah terlambat bagi kita untuk meninjau kembali tindakan kita. dan hidup kita hanya menjadi biennale yang memalukan. Kami tidak dapat menyangkal fakta bahwa mesin pencari sekarang menjadi bagian penting dari kepribadian ganda digital kami. Kita hanya perlu memanfaatkan teknologi yang telah diberikan kepada kita, tidak membiarkannya memperbudak kita dalam rantai perbuatan buruk kita sendiri.
Oke, tidak ada lagi pembicaraan emosional, hanya mengagumi kelucuan dan bakat mesin pencari bayi yang kini telah menjadi remaja, dan memahami Anda jauh lebih baik. Google telah ada untuk mencari segalanya untuk kita, ini adalah internet bagi banyak dari kita, dan kita harus menghargai pengalaman baik yang kita peroleh saat menggunakan Google Penelusuran. Oh! Saya lupa menyebutkan Bing, Anda juga luar biasa. Tetap waspada, tetap aman dan Google itu.
Tonton video ini dan ketahui lebih banyak tentang mesin pencari:
Pernahkah Anda mengklik tombol Saya merasa Beruntung di Google Penelusuran. Buka dan beri tahu kami doodle mana yang paling Anda sukai di bagian komentar di bawah.