
Cara Mengurai Data CSV di Bash
Diterbitkan: 2022-09-16
File Comma Separated Values (CSV) adalah salah satu format paling umum untuk data yang diekspor. Di Linux, kita dapat membaca file CSV menggunakan perintah Bash. Tapi itu bisa menjadi sangat rumit, sangat cepat. Kami akan membantu.
Apa itu File CSV?
File Nilai yang Dipisahkan Koma adalah file teks yang menyimpan data yang ditabulasi. CSV adalah jenis data yang dibatasi. Seperti namanya, koma “ , ” digunakan untuk memisahkan setiap bidang data—atau nilai —dari tetangganya.
CSV ada di mana-mana. Jika sebuah aplikasi memiliki fungsi impor dan ekspor, itu hampir selalu mendukung CSV. File CSV dapat dibaca manusia. Anda dapat melihat di dalamnya dengan lebih sedikit, membukanya di editor teks apa pun, dan memindahkannya dari program ke program. Misalnya, Anda dapat mengekspor data dari database SQLite dan membukanya di LibreOffice Calc.
Namun, bahkan CSV bisa menjadi rumit. Ingin memiliki koma di bidang data? Bidang itu harus memiliki tanda kutip “ " ” yang melingkarinya. Untuk memasukkan tanda kutip di bidang, setiap tanda kutip harus dimasukkan dua kali.
Tentu saja, jika Anda bekerja dengan CSV yang dihasilkan oleh program atau skrip yang telah Anda tulis, format CSV cenderung sederhana dan mudah. Jika Anda terpaksa bekerja dengan format CSV yang lebih kompleks, dengan Linux menjadi Linux, ada solusi yang dapat kami gunakan untuk itu juga.
Beberapa Contoh Data
Anda dapat dengan mudah menghasilkan beberapa contoh data CSV, menggunakan situs seperti Online Data Generator. Anda dapat menentukan bidang yang Anda inginkan dan memilih berapa banyak baris data yang Anda inginkan. Data Anda dihasilkan menggunakan nilai dummy realistis dan diunduh ke komputer Anda.
Kami membuat file yang berisi 50 baris informasi karyawan dummy:
- id : Nilai integer unik yang sederhana.
- firstname : Nama depan orang tersebut.
- lastname : Nama belakang orang tersebut.
- job-title : Jabatan orang tersebut.
- email-address : Alamat email orang tersebut.
- branch : Cabang perusahaan tempat mereka bekerja.
- state : Negara tempat cabang berada.
Beberapa file CSV memiliki baris header yang mencantumkan nama bidang. File sampel kami memiliki satu. Inilah bagian atas file kami:
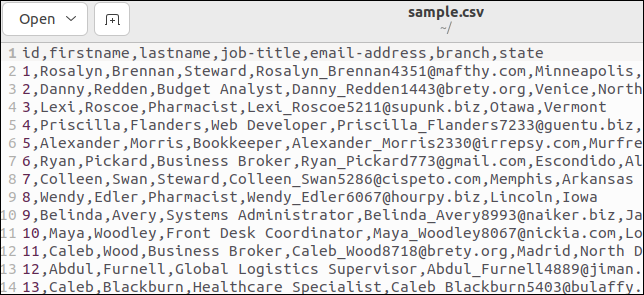
Baris pertama menyimpan nama bidang sebagai nilai yang dipisahkan koma.
Parsing Data Bentuk file CSV
Mari kita menulis skrip yang akan membaca file CSV dan mengekstrak bidang dari setiap catatan. Salin skrip ini ke editor, dan simpan ke file bernama “field.sh.”
#! /bin/bash while IFS="," read -r id firstname lastname jobtitle status cabang email melakukan echo "ID Rekam: $id" echo "Nama depan: $namadepan" echo "Nama belakang: $namabelakang" echo "Judul Pekerjaan: $jobtitle" echo "Tambahkan email: $email" echo "Cabang: $cabang" echo "Negara: $negara" gema "" selesai < <(tail -n +2 sample.csv)
Ada cukup banyak yang dikemas ke dalam skrip kecil kami. Mari kita hancurkan.

Kami menggunakan loop while . Selama kondisi perulangan while bernilai true, badan perulangan while akan dieksekusi. Tubuh loop cukup sederhana. Kumpulan pernyataan echo digunakan untuk mencetak nilai beberapa variabel ke jendela terminal.
Kondisi perulangan while lebih menarik daripada isi perulangan. Kami menetapkan bahwa koma harus digunakan sebagai pemisah bidang internal, dengan pernyataan IFS="," . IFS adalah variabel lingkungan. Perintah read mengacu pada nilainya saat mem-parsing urutan teks.
Kami menggunakan opsi -r (mempertahankan garis miring terbalik) perintah read untuk mengabaikan garis miring terbalik yang mungkin ada dalam data. Mereka akan diperlakukan sebagai karakter biasa.
Teks yang diurai oleh perintah read disimpan dalam sekumpulan variabel yang dinamai sesuai bidang CSV. Mereka bisa dengan mudah diberi nama field1, field2, ... field7 , tetapi nama yang bermakna membuat hidup lebih mudah.
Data diperoleh sebagai output dari perintah tail . Kami menggunakan tail karena memberi kami cara sederhana untuk melewati baris header file CSV. Opsi -n +2 (nomor baris) memberitahu tail untuk mulai membaca pada baris nomor dua.
Konstruk <(...) disebut proses substitusi. Itu menyebabkan Bash menerima output dari suatu proses seolah-olah itu berasal dari deskriptor file. Ini kemudian diarahkan ke loop while , menyediakan teks yang akan diurai oleh perintah read .
Jadikan skrip dapat dieksekusi menggunakan perintah chmod . Anda harus melakukan ini setiap kali Anda menyalin skrip dari artikel ini. Ganti nama skrip yang sesuai dalam setiap kasus.
chmod +x bidang.sh

Saat kami menjalankan skrip, catatan dibagi dengan benar ke dalam bidang penyusunnya, dengan masing-masing bidang disimpan dalam variabel yang berbeda.
./field.sh
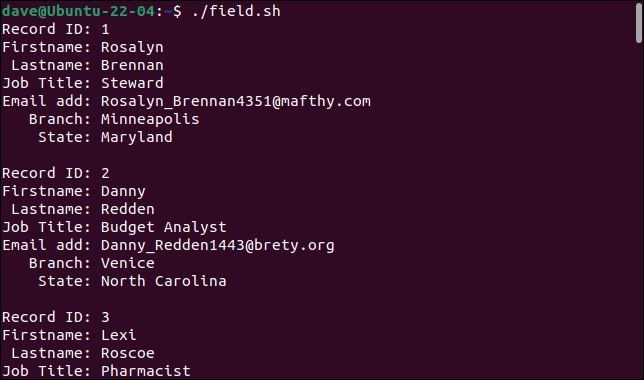
Setiap catatan dicetak sebagai satu set bidang.
Memilih Bidang
Mungkin kita tidak ingin atau perlu mengambil setiap bidang. Kita bisa mendapatkan pilihan bidang dengan memasukkan perintah cut .
Skrip ini disebut "select.sh."
#!/bin/bash sementara IFS="," baca -r id status cabang jobtitle melakukan echo "ID Rekam: $id" echo "Judul Pekerjaan: $jobtitle" echo "Cabang: $cabang" echo "Negara: $negara" gema "" selesai < <(cut -d "," -f1,4,6,7 sample.csv | tail -n +2)
Kami telah menambahkan perintah cut ke dalam klausa substitusi proses. Kami menggunakan opsi -d (pembatas) untuk memberi tahu cut untuk menggunakan koma “ , ” sebagai pembatas. Opsi -f (bidang) memberi tahu cut bahwa kita menginginkan bidang satu, empat, enam, dan tujuh. Keempat bidang tersebut dibaca menjadi empat variabel, yang dicetak di badan loop while .
Inilah yang kami dapatkan ketika kami menjalankan skrip.
./pilih.sh
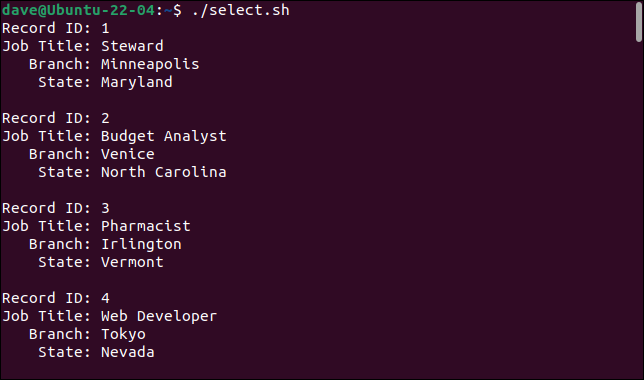
Dengan menambahkan perintah cut , kita dapat memilih field yang kita inginkan dan mengabaikan yang tidak kita inginkan.
Sejauh ini bagus. Tetapi…
Jika CSV yang Anda tangani tidak rumit tanpa koma atau tanda kutip dalam data lapangan, apa yang telah kami bahas mungkin akan memenuhi kebutuhan penguraian CSV Anda. Untuk menunjukkan masalah yang dapat kami hadapi, kami memodifikasi sampel kecil data agar terlihat seperti ini.
id, nama depan, nama belakang, jabatan, alamat email, cabang, negara bagian 1,Rosalyn,Brennan,"Steward, Senior",[email protected],Minneapolis,Maryland 2,Danny,Redden,"Analis ""Anggaran""",[email protected],Venice,North Carolina 3,Lexi, Roscoe, Apoteker,,Irlington, Vermont
- Rekam satu memiliki koma di bidang
job-title, sehingga bidang tersebut perlu dibungkus dengan tanda kutip. - Rekam dua memiliki kata yang dibungkus dengan dua set tanda kutip di bidang
jobs-title. - Catatan tiga tidak memiliki data di bidang
email-address.
Data ini disimpan sebagai "sample2.csv." Ubah skrip "field.sh" Anda untuk memanggil "sample2.csv", dan simpan sebagai "field2.sh."
#! /bin/bash while IFS="," read -r id firstname lastname jobtitle status cabang email melakukan echo "ID Rekam: $id" echo "Nama depan: $namadepan" echo "Nama belakang: $namabelakang" echo "Judul Pekerjaan: $jobtitle" echo "Tambahkan email: $email" echo "Cabang: $cabang" echo "Negara: $negara" gema "" selesai < <(ekor -n +2 sample2.csv)
Saat kami menjalankan skrip ini, kami dapat melihat retakan muncul di parser CSV sederhana kami.

./field2.sh

Catatan pertama membagi bidang jabatan menjadi dua bidang, memperlakukan bagian kedua sebagai alamat email. Setiap bidang setelah ini digeser satu tempat ke kanan. Bidang terakhir berisi nilai branch dan state .
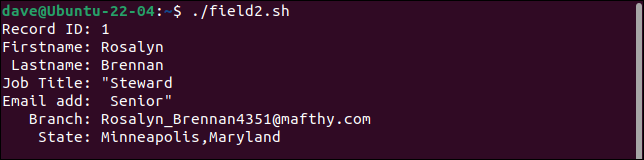
Catatan kedua mempertahankan semua tanda kutip. Seharusnya hanya memiliki sepasang tanda kutip tunggal di sekitar kata "Anggaran."
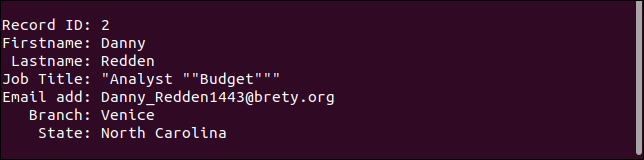
Catatan ketiga benar-benar menangani bidang yang hilang sebagaimana mestinya. Alamat email tidak ada, tetapi yang lainnya seperti yang seharusnya.

Sebaliknya, untuk format data sederhana, sangat sulit untuk menulis parser CSV kasus umum yang kuat. Alat seperti awk akan membuat Anda mendekat, tetapi selalu ada kasus tepi dan pengecualian yang lolos.

Mencoba menulis parser CSV yang sempurna mungkin bukan cara terbaik untuk maju. Pendekatan alternatif—terutama jika Anda bekerja dengan tenggat waktu tertentu—menggunakan dua strategi berbeda.
Salah satunya adalah dengan menggunakan alat yang dirancang khusus untuk memanipulasi dan mengekstrak data Anda. Yang kedua adalah membersihkan data Anda dan mengganti skenario masalah seperti koma yang disematkan dan tanda kutip. Parser Bash sederhana Anda kemudian dapat mengatasi CSV yang ramah Bash.
Perangkat csvkit
CSV toolkit csvkit adalah kumpulan utilitas yang dibuat secara jelas untuk membantu bekerja dengan file CSV. Anda harus menginstalnya di komputer Anda.
Untuk menginstalnya di Ubuntu, gunakan perintah ini:
sudo apt install csvkit

Untuk menginstalnya di Fedora, Anda perlu mengetik:
sudo dnf instal python3-csvkit

Di Manjaro perintahnya adalah:
sudo pacman -S csvkit

Jika kita meneruskan nama file CSV ke sana, utilitas csvlook menampilkan tabel yang menunjukkan konten setiap bidang. Konten bidang ditampilkan untuk menunjukkan apa yang diwakili oleh konten bidang, bukan seperti yang disimpan dalam file CSV.
Mari kita coba csvlook dengan file “sample2.csv” kita yang bermasalah.
csvlook sample2.csv
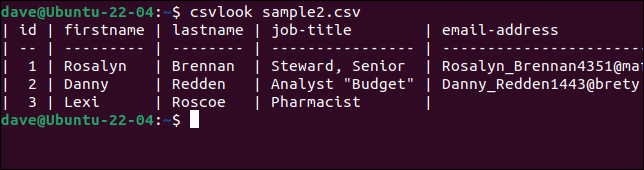
Semua bidang ditampilkan dengan benar. Ini membuktikan masalahnya bukan pada CSV. Masalahnya adalah skrip kami terlalu sederhana untuk menafsirkan CSV dengan benar.
Untuk memilih kolom tertentu, gunakan perintah csvcut . Opsi -c (kolom) dapat digunakan dengan nama bidang atau nomor kolom, atau campuran keduanya.
Misalkan kita perlu mengekstrak nama depan dan belakang, jabatan, dan alamat email dari setiap record, tetapi kita ingin memiliki urutan nama sebagai "nama belakang, nama depan." Yang perlu kita lakukan adalah meletakkan nama atau nomor bidang dalam urutan yang kita inginkan.
Ketiga perintah ini semuanya setara.
csvcut -c nama belakang, nama depan, jabatan, alamat email sample2.csv
csvcut -c nama belakang,nama depan,4,5 sample2.csv
csvcut -c 3,2,4,5 sample2.csv
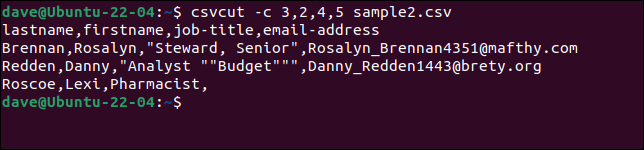
Kita dapat menambahkan perintah csvsort untuk mengurutkan output berdasarkan bidang. Kami menggunakan opsi -c (kolom) untuk menentukan kolom yang akan diurutkan, dan opsi -r (terbalik) untuk mengurutkan dalam urutan menurun.
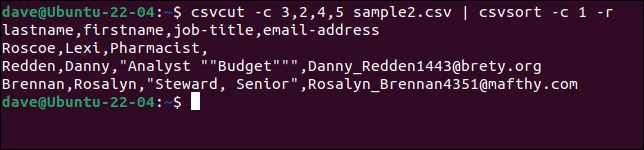
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r
Untuk membuat output lebih cantik, kita dapat memasukkannya melalui csvlook .
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r | csvlook
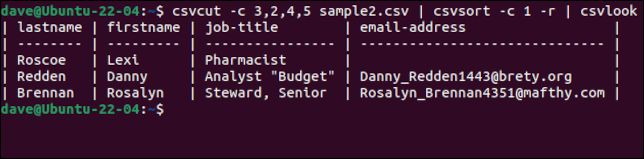
Sentuhan yang rapi adalah bahwa, meskipun catatan diurutkan, baris header dengan nama bidang disimpan sebagai baris pertama. Setelah kami senang kami memiliki data seperti yang kami inginkan, kami dapat menghapus csvlook dari rantai perintah, dan membuat file CSV baru dengan mengarahkan output ke file.
Kami menambahkan lebih banyak data ke "sample2.file", menghapus perintah csvsort , dan membuat file baru bernama "sample3.csv."
csvcut -c 3,2,4,5 sample2.csv > sample3.csv

Cara Aman untuk Membersihkan Data CSV
Jika Anda membuka file CSV di LibreOffice Calc, setiap bidang akan ditempatkan di sel. Anda dapat menggunakan fungsi temukan dan ganti untuk mencari koma. Anda bisa menggantinya dengan "tidak ada" sehingga mereka menghilang, atau dengan karakter yang tidak akan mempengaruhi penguraian CSV, seperti titik koma “ ; " Misalnya.
Anda tidak akan melihat tanda kutip di sekitar bidang yang dikutip. Satu-satunya tanda kutip yang akan Anda lihat adalah tanda kutip yang disematkan di dalam data bidang. Ini ditampilkan sebagai tanda kutip tunggal. Menemukan dan menggantinya dengan satu apostrof “ ' ” akan menggantikan tanda kutip ganda dalam file CSV.
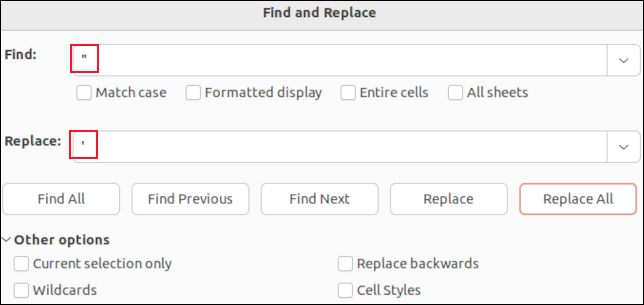
Melakukan pencarian dan penggantian dalam aplikasi seperti LibreOffice Calc berarti Anda tidak dapat secara tidak sengaja menghapus salah satu koma pemisah bidang, atau menghapus tanda kutip di sekitar bidang yang dikutip. Anda hanya akan mengubah nilai data bidang.
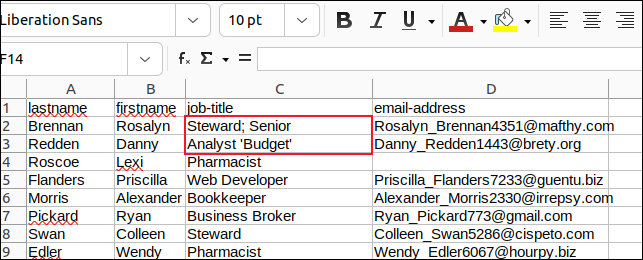
Kami mengubah semua koma di bidang dengan titik koma dan semua tanda kutip yang disematkan dengan apostrof dan menyimpan perubahan kami.
Kami kemudian membuat skrip yang disebut "field3.sh" untuk mengurai "sample3.csv."
#! /bin/bash sementara IFS="," baca -r nama belakang nama depan email jabatan pekerjaan melakukan echo "Nama belakang: $namabelakang" echo "Nama depan: $namadepan" echo "Judul Pekerjaan: $jobtitle" echo "Tambahkan email: $email" gema "" selesai < <(ekor -n +2 sample3.csv)
Mari kita lihat apa yang kita dapatkan ketika kita menjalankannya.
./field3.sh
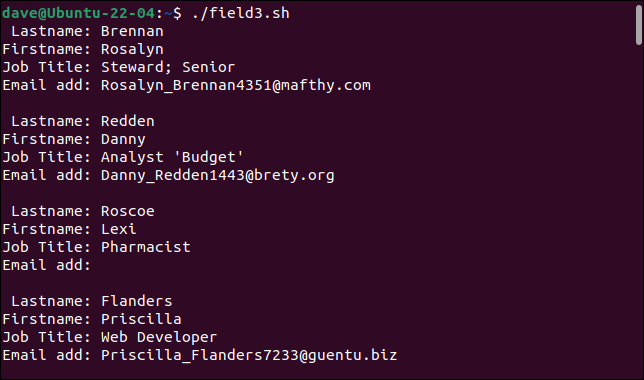
Pengurai sederhana kami sekarang dapat menangani catatan kami yang sebelumnya bermasalah.
Anda Akan Melihat Banyak CSV
CSV bisa dibilang hal yang paling dekat dengan bahasa umum untuk data aplikasi. Sebagian besar aplikasi yang menangani beberapa bentuk dukungan data mengimpor dan mengekspor CSV. Mengetahui cara menangani CSV—dengan cara yang realistis dan praktis—akan membantu Anda.
TERKAIT: 9 Contoh Skrip Bash untuk Memulai Anda di Linux