
Bagaimana Mengurai Teks
Diterbitkan: 2022-10-15
Jika Anda telah mempelajari beberapa bahasa pemrograman komputer, Anda mungkin pernah mendengar istilah, mengurai teks. Ini digunakan untuk menyederhanakan nilai data kompleks dari file. Artikel ini membantu Anda mengetahui cara mengurai teks menggunakan bahasa tersebut. Selain itu, jika Anda menghadapi kesalahan dalam mengurai teks x, Anda akan tahu cara memperbaiki kesalahan penguraian di artikel.
Isi
- Bagaimana Mengurai Teks
- Apa itu Teks Parsing?
- NLP atau Pemrosesan Bahasa Alami
- Apa itu Teks Parsing?
- Apa Alasan untuk Mengurai Teks?
- Metode 1: Melalui Kelas DataFrame
- Metode 2: Melalui Tokenisasi Kata
- Metode 3: Melalui Kelas DocParser
- Metode 4: Melalui Alat Teks Parse
- Metode 5: Melalui TextFieldParser (Visual Basic)
- Kiat Pro: Cara Mengurai Teks Melalui MS Excel
- Cara Memperbaiki Kesalahan Parse
Bagaimana Mengurai Teks
Dalam artikel ini kami telah menunjukkan panduan lengkap untuk mengurai teks melalui berbagai cara dan juga secara singkat memberikan pengantar untuk mengurai teks.
Apa itu Teks Parsing?
Sebelum mempelajari untuk mempelajari konsep parsing teks menggunakan kode apa pun. Penting untuk mengetahui tentang dasar-dasar bahasa dan pengkodean.
NLP atau Pemrosesan Bahasa Alami
Untuk mengurai teks, Pemrosesan Bahasa Alami atau NLP, yang merupakan sub-bidang dari domain Kecerdasan Buatan digunakan. Bahasa python yang merupakan salah satu bahasa yang termasuk dalam kategori tersebut digunakan untuk mengurai teks.
Kode NLP memungkinkan komputer untuk memahami dan memproses bahasa manusia agar cocok untuk berbagai aplikasi. Untuk menerapkan teknik ML atau Machine Learning ke bahasa, data teks tidak terstruktur harus diubah menjadi data tabular terstruktur. Untuk menyelesaikan aktivitas parsing, bahasa Python digunakan untuk mengubah kode program.
Apa itu Teks Parsing?
Mengurai teks berarti mengonversi data dari satu format ke format lain. Format di mana file disimpan harus diuraikan atau dikonversi ke file dalam format yang berbeda untuk memungkinkan pengguna menggunakannya dalam berbagai aplikasi.
- Dengan kata lain, proses berarti menganalisis string atau teks dan mengubahnya menjadi komponen logis dengan mengubah format file.
- Beberapa aturan bahasa Python digunakan untuk menyelesaikan tugas pemrograman umum ini. Saat mengurai teks, rangkaian teks yang diberikan dipecah menjadi komponen yang lebih kecil.
Apa Alasan untuk Mengurai Teks?
Alasan mengapa teks harus diurai diberikan di bagian ini dan merupakan pengetahuan prasyarat sebelum mengetahui cara mengurai teks.
- Semua data yang terkomputerisasi tidak akan berada dalam format yang sama dan mungkin berbeda menurut berbagai aplikasi.
- Format data bervariasi untuk berbagai aplikasi dan kode yang tidak kompatibel akan menyebabkan kesalahan ini.
- Tidak ada program komputer universal individu untuk memilih data dari semua format data.
Metode 1: Melalui Kelas DataFrame
Kelas DataFrame dari bahasa Python memiliki semua fungsi yang diperlukan untuk mengurai teks. Pustaka bawaan ini menampung kode yang diperlukan untuk mengurai data dari format apa pun ke format lain.
Pengenalan Singkat Kelas DataFrame
DataFrame Class adalah struktur data yang kaya fitur, yang digunakan sebagai alat analisis data. Ini adalah alat analisis data yang kuat yang dapat digunakan untuk menganalisis data dengan sedikit usaha.
- Kode dibaca ke dalam panda DataFrame untuk melakukan analisis dalam bahasa Python.
- Kelas hadir dengan banyak paket yang disediakan oleh panda yang digunakan oleh analis data Python.
- Fitur kelas ini adalah abstraksi, kode di mana fungsi internal fungsi disembunyikan dari pengguna, perpustakaan NumPy. Pustaka NumPy adalah pustaka python yang mencakup perintah dan fungsi untuk bekerja dengan array.
- Kelas DataFrame dapat digunakan untuk merender array dua dimensi dengan beberapa indeks baris dan kolom. Indeks ini membantu dalam menyimpan data multi-dimensi, dan karenanya, disebut, MultiIndex. Ini harus diubah untuk mengetahui cara memperbaiki kesalahan parse.
Panda dari bahasa Python membantu dalam melakukan operasi SQL atau gaya database dengan sangat sempurna untuk menghindari kesalahan dalam mengurai teks x. Ini juga berisi beberapa alat IO yang membantu dalam menganalisis file CSV, MS Excel, JSON, HDF5, dan format data lainnya.
Baca Juga: Perbaiki Kesalahan Terjadi Saat Mencoba Permintaan Proksi
Proses Parsing Teks menggunakan Kelas DataFrame
Untuk mengetahui cara mengurai teks, Anda dapat menggunakan proses standar menggunakan Kelas DataFrame yang diberikan di bagian ini.
- Menguraikan format data dari data input.
- Tentukan data keluaran data seperti CSV atau Comma Separated Value .
- Tulis pada kode tipe data primitif seperti daftar atau dict.
Catatan: Menulis kode pada DataFrame kosong bisa jadi membosankan dan rumit. Panda memungkinkan dalam membuat data pada kelas DataFrame dari tipe data ini. Oleh karena itu, data dalam tipe data primitif dapat dengan mudah diuraikan ke format data yang diperlukan.
- Analisis data menggunakan alat analisis data, pandas DataFrame, dan cetak hasilnya.
Opsi I: Format Standar
Metode standar untuk memformat file apa pun dengan format data tertentu seperti CSV dijelaskan di sini.
- Simpan file dengan nilai data secara lokal di PC Anda. Misalnya, Anda dapat memberi nama file data.txt .
- Impor file dalam panda dengan nama tertentu dan impor data ke variabel lain. Misalnya, panda bahasa diimpor ke nama pd dalam kode yang diberikan.
- Impor harus memiliki kode lengkap dengan detail nama file input, fungsi, dan format file input.
Catatan: Di sini, variabel bernama res digunakan untuk menjalankan fungsi membaca data dalam file data.txt menggunakan panda yang diimpor dalam pd . Format data teks input ditentukan dalam format CSV .
- Panggil jenis file bernama dan analisis teks yang diuraikan pada hasil cetak. Misalnya, perintah res setelah eksekusi baris perintah akan membantu dalam mencetak teks yang diuraikan.
Contoh kode untuk proses yang dijelaskan di atas diberikan di bawah ini dan akan membantu dalam memahami cara mengurai teks.
impor panda sebagai pd
res = pd.read_csv('data.txt')
resDalam hal ini, jika Anda memasukkan nilai data dalam file data.txt seperti [1,2,3] , itu akan diuraikan dan ditampilkan sebagai 1 2 3 .
Opsi II: Metode String
Jika teks yang diberikan ke kode hanya berisi string atau karakter alfa, karakter khusus dalam string seperti koma, spasi, dll., dapat digunakan untuk memisahkan dan mengurai teks. Prosesnya mirip dengan operasi string internal yang umum. Untuk menemukan cara memperbaiki kesalahan parse, Anda harus mengikuti proses parsing teks menggunakan opsi yang dijelaskan di bawah ini.
- Data diekstraksi dari string dan semua karakter khusus yang memisahkan teks dicatat.
Misalnya, dalam kode yang diberikan di bawah ini, karakter khusus dalam string my_string , yaitu, ' , ' dan ' : ' diidentifikasi. Proses ini harus dilakukan dengan hati-hati untuk menghindari kesalahan dalam mengurai teks x.
- Teks dalam string dibagi satu per satu berdasarkan nilai dan posisi karakter khusus.
Misalnya, string dipecah menjadi nilai data teks berdasarkan karakter khusus yang diidentifikasi menggunakan perintah split.
- Nilai data string dicetak sendiri sebagai teks yang diurai. Di sini, pernyataan print digunakan untuk mencetak nilai data yang diurai dari teks.
Contoh kode untuk proses yang dijelaskan di atas diberikan di bawah ini.
my_string = 'Nama: Teknologi, komputer'
sfinal = [name.strip() untuk nama di my_string.split(':')[1].split(',')]
print(“Nama: {}”.format(akhir))Dalam hal ini, hasil dari string yang diurai akan ditampilkan seperti yang ditunjukkan di bawah ini.
Nama: ['Teknologi', 'komputer']
Untuk mendapatkan kejelasan yang lebih baik dan mengetahui cara mengurai teks saat menggunakan teks string, loop for digunakan dan kode dimodifikasi sebagai berikut.
my_string = 'Nama: Teknologi, komputer'
s1 = string_saya.split(':')
s2 = s1[1]
s3 = s2.split(',')
s4 = [name.strip() untuk nama di s3]
untuk idx, item dalam enumerate([s1, s2, s3, s4]):
print(“Langkah {}: {}”.format(idx, item)) 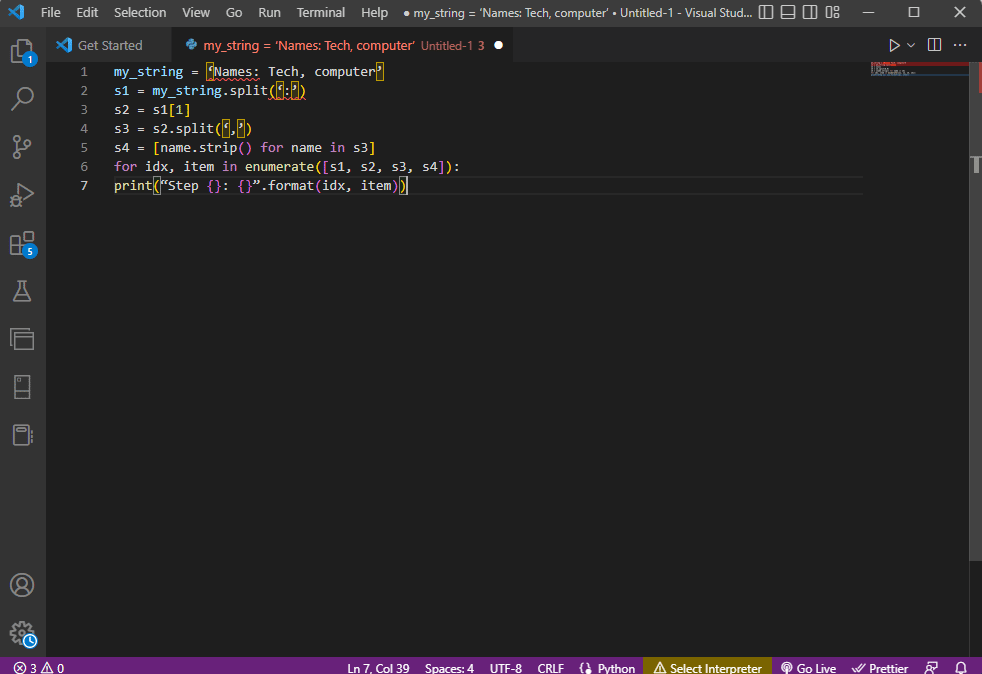
Hasil dari teks yang diurai untuk setiap langkah ini ditampilkan seperti di bawah ini. Anda dapat mencatat bahwa, pada Langkah 0, string dipisahkan berdasarkan karakter khusus : dan nilai data teks dipisahkan berdasarkan karakter pada langkah selanjutnya.
Langkah 0: ['Nama', 'Teknologi, komputer'] Langkah 1: Teknologi, komputer Langkah 2: ['Tek', ' komputer'] Langkah 3: ['Teknologi', 'komputer']
Opsi III: Mengurai File Kompleks
Dalam kebanyakan kasus, data file yang perlu diuraikan berisi berbagai tipe data dan nilai data. Dalam hal ini, mungkin sulit untuk mengurai file menggunakan metode yang dijelaskan sebelumnya.
Fitur penguraian data kompleks dalam file adalah membuat nilai data ditampilkan dalam format tabel.
- Judul atau Metadata nilai dicetak di bagian atas file,
- Variabel dan bidang dicetak dalam output dalam bentuk tabel, dan
- Nilai data membentuk kunci majemuk.
Sebelum mempelajari cara mengurai teks dalam metode ini, perlu mempelajari beberapa konsep dasar. Penguraian nilai data dilakukan berdasarkan ekspresi reguler atau Regex.
Pola Regex
Untuk mengetahui cara memperbaiki kesalahan parse, Anda harus memastikan bahwa pola regex dalam ekspresi sudah benar. Kode untuk mengurai nilai data string akan melibatkan pola Regex umum yang tercantum di bawah di bagian ini.
- '\d' : cocok dengan angka desimal dalam string,
- '\s' : cocok dengan karakter spasi,
- '\w' : cocok dengan karakter alfanumerik,
- '+' atau '*' : melakukan kecocokan serakah dengan mencocokkan satu atau lebih karakter dalam string,
- 'a-z' : cocok dengan grup huruf kecil dalam nilai data teks,
- 'A-Z' atau 'a-z' : cocok dengan kelompok huruf besar dan kecil dari string, dan
- '0-9' : cocok dengan nilai numerik.
Ekspresi Reguler
Modul ekspresi reguler adalah bagian utama dari paket pandas dalam bahasa Python dan pengulangan yang salah dapat menyebabkan kesalahan dalam teks parse x. Ini adalah bahasa kecil yang tertanam di dalam Python untuk menemukan pola string dalam ekspresi. Ekspresi Reguler atau Regex adalah string dengan sintaks khusus. Ini memungkinkan pengguna untuk mencocokkan pola dalam string lain berdasarkan nilai dalam string.
Regex dibuat berdasarkan tipe data dan persyaratan ekspresi dalam string, seperti 'String = (.*)\n . Regex digunakan sebelum pola dalam setiap ekspresi. Simbol yang digunakan dalam ekspresi reguler tercantum di bawah ini dan akan membantu mengetahui cara mengurai teks.
- . : untuk mengambil karakter apapun dari data,
- * : menggunakan nol atau lebih data dari ekspresi sebelumnya,
- (.*) : untuk mengelompokkan bagian dari ekspresi reguler di dalam tanda kurung,
- \n : Buat karakter baris baru di akhir baris dalam kode,
- \d : buat nilai integral pendek dalam rentang 0 hingga 9,
- + : menggunakan satu atau lebih data dari ekspresi sebelumnya, dan
- | : membuat pernyataan logis; digunakan untuk atau ekspresi.
Objek Regex
RegexObject adalah nilai kembalian untuk fungsi kompilasi dan digunakan untuk mengembalikan MatchObject jika ekspresi cocok dengan nilai kecocokan.
1. Obyek Pertandingan
Karena nilai Boolean dari MatchObject selalu Benar, Anda dapat menggunakan pernyataan if untuk mengidentifikasi kecocokan positif dalam objek. Dalam kasus penggunaan pernyataan if , grup yang dirujuk oleh indeks digunakan untuk mengetahui kecocokan objek dalam ekspresi.
- group() mengembalikan satu atau lebih subgrup yang cocok,
- group(0) mengembalikan seluruh pertandingan,
- group(1) mengembalikan subkelompok tanda kurung pertama, dan
- Saat merujuk ke beberapa grup, kita harus menggunakan ekstensi khusus python. Ekstensi ini digunakan untuk menentukan nama grup di mana kecocokan harus ditemukan. Ekstensi spesifik disediakan dalam grup yang dikurung. Misalnya, ekspresi, (?P<group1>regex1) akan merujuk ke grup tertentu dengan nama group1 dan memeriksa kecocokan dalam ekspresi reguler, regex1 . Untuk mempelajari cara memperbaiki kesalahan penguraian, Anda harus memeriksa apakah grup diarahkan dengan benar.
2. Metode MatchObject
Saat menemukan cara mengurai teks, penting untuk diketahui bahwa MatchObject memiliki dua metode dasar seperti yang tercantum di bawah ini. Jika MatchObject ditemukan dalam ekspresi yang ditentukan, itu akan mengembalikan instance-nya, jika tidak, itu akan mengembalikan None.
- Metode match(string) digunakan untuk menemukan kecocokan string di awal ekspresi reguler, dan
- Metode pencarian(string) digunakan untuk memindai string untuk menemukan lokasi kecocokan dalam ekspresi reguler.
Fungsi Ekspresi Reguler
Fungsi Regex adalah baris kode yang digunakan untuk melakukan fungsi tertentu seperti yang ditentukan oleh pengguna dari kumpulan nilai data yang diperoleh.
Catatan: Untuk menulis fungsi, string mentah digunakan untuk ekspresi reguler untuk menghindari kesalahan dalam mengurai teks x. Ini dilakukan dengan menambahkan subskrip r sebelum setiap pola dalam ekspresi.
Fungsi umum yang digunakan dalam ekspresi dijelaskan di bawah ini.
1. re.findall()
Fungsi ini mengembalikan semua pola dalam string jika kecocokan ditemukan dan mengembalikan daftar kosong jika tidak ada kecocokan yang ditemukan. Misalnya, fungsi, string = re.findall('[aeiou]', regex_filename) digunakan untuk menemukan kemunculan vokal dalam nama file.
2. re.split()
Fungsi ini digunakan untuk memisahkan string jika ada kecocokan dengan karakter yang ditentukan seperti spasi ditemukan. Jika tidak ditemukan kecocokan, ia mengembalikan string kosong.
3. re.sub()
Fungsi mengganti teks yang cocok dengan isi dari variabel ganti yang diberikan. Bertentangan dengan fungsi lain, jika tidak ada pola yang ditemukan, string asli dikembalikan.
4. pencarian ulang()
Salah satu fungsi dasar untuk membantu dalam mempelajari cara mengurai teks adalah fungsi pencarian. Ini membantu dalam mencari pola dalam string dan mengembalikan objek yang cocok. Jika pencarian gagal dalam mengidentifikasi kecocokan, tidak ada nilai yang dikembalikan.
5. kompilasi ulang (pola)
Fungsi ini digunakan untuk mengkompilasi pola ekspresi reguler ke dalam RegexObject, yang telah dibahas sebelumnya.
Persyaratan lainnya
Persyaratan yang tercantum adalah fitur tambahan yang digunakan oleh pemrogram tingkat lanjut dalam analisis data.
- Untuk memvisualisasikan ekspresi reguler, regexper digunakan, dan
- Untuk menguji ekspresi reguler, regex101 digunakan.
Baca Juga: Cara Install NumPy di Windows 10

Proses Parsing Teks
Metode untuk mengurai teks dalam opsi kompleks ini dijelaskan seperti yang diberikan di bawah ini.
- Langkah terpenting adalah memahami format input dengan membaca konten file. Misalnya, fungsi with open dan read() digunakan untuk membuka dan membaca konten file bernama sample . File sampel memiliki konten dari file file.txt ; untuk mempelajari cara memperbaiki kesalahan parse, file harus dibaca sepenuhnya.
- Isi file dicetak untuk menganalisis data secara manual untuk mengetahui metadata nilai. Di sini, fungsi print() digunakan untuk mencetak konten file sampel .
- Paket data yang diperlukan untuk mengurai teks diimpor ke kode dan nama diberikan ke kelas untuk pengkodean lebih lanjut. Di sini, ekspresi reguler dan panda diimpor.
- Ekspresi reguler yang diperlukan untuk kode didefinisikan dalam file dengan menyertakan pola regex dan fungsi regex. Hal ini memungkinkan objek teks atau corpus untuk mengambil kode untuk analisis data.
- Untuk mengetahui cara mengurai teks, Anda dapat merujuk ke contoh kode yang diberikan di sini. Fungsi compile() digunakan untuk mengkompilasi string dari grup stringname1 dari file filename . Fungsi untuk memeriksa kecocokan dalam regex digunakan oleh perintah ief_parse_line(line) ,
- Pengurai baris untuk kode ditulis menggunakan def_parse_file(filepath) , di mana fungsi yang ditentukan memeriksa semua kecocokan regex dalam fungsi yang ditentukan. Di sini, metode regex search() mencari kunci rx dalam nama file file dan mengembalikan kunci dan kecocokan dari regex pertama yang cocok. Masalah apa pun dengan langkah ini dapat menyebabkan kesalahan dalam mengurai teks x.
- Langkah selanjutnya adalah menulis File Parser menggunakan fungsi file parser yaitu def_parse_file(filepath) . Daftar kosong dibuat untuk mengumpulkan data kode, seperti data = [] , kecocokan diperiksa di setiap baris dengan match = _parse_line(line) , dan data nilai yang tepat dikembalikan berdasarkan tipe data.
- Untuk mengekstrak nomor dan nilai tabel, digunakan command line.strip().split(',') . Perintah row{} digunakan untuk membuat kamus dengan baris data. Perintah data.append(row) digunakan untuk memahami data dan menguraikannya ke format tabel.
Perintah data = pd.DataFrame(data) digunakan untuk membuat pandas DataFrame dari nilai dict. Atau, Anda dapat menggunakan perintah berikut untuk tujuan masing-masing seperti yang dinyatakan di bawah ini.
- data.set_index(['string', 'integer'], inplace=True) untuk mengatur indeks Tabel.
- data = data.groupby(level=data.index.names).first() untuk menggabungkan dan menghapus nans.
- data = data.apply(pd.to_numeric, errors='ignore') untuk mengupgrade skor dari nilai float ke integer.
Langkah terakhir untuk mengetahui cara mengurai teks adalah dengan menguji parser menggunakan pernyataan if dengan menetapkan nilai ke data variabel dan mencetaknya menggunakan perintah print(data) .
Contoh kode untuk penjelasan di atas diberikan di sini.
dengan open('file.txt') sebagai contoh:
sample_contents = sample.read()
cetak(konten_sampel)
impor ulang
impor panda sebagai pd
rx_namafile = {
'string1': re.compile(r 'string = (?<P<stringname1>,*)\n'),
}
ief_parse_line(baris):
untuk kunci, rx di rx_filename.items():
cocok = rx.search(baris)
jika cocok:
kunci kembali, cocokkan
kembali Tidak ada, Tidak ada
def parse_file(path file):
data = []
dengan open(filepath, 'r') sebagai file_object:
baris = file_object.readline()
sementara baris:
kunci, cocokkan = _parse_line(baris)
jika kunci == 'string1':
string = match.group('string1')
bilangan bulat = int(string1)
value_type = match.group('string1')
baris = file_object.readline()
sementara line.strip():
angka, nilai = line.strip().split(',')
nilai = nilai.strip()
baris = {
'Data1': string1,
'Data2': nomor,
nilai_tipe: nilai
}
data.tambahkan(baris)
baris = file_object.readline()
baris = file_object.readline()
data = pd.DataFrame(data)
kembalikan data
jika _ _nama_ _ = = '_ _main_ _':
filepath = 'contoh.txt'
data = parse(jalur file)
cetak (data) 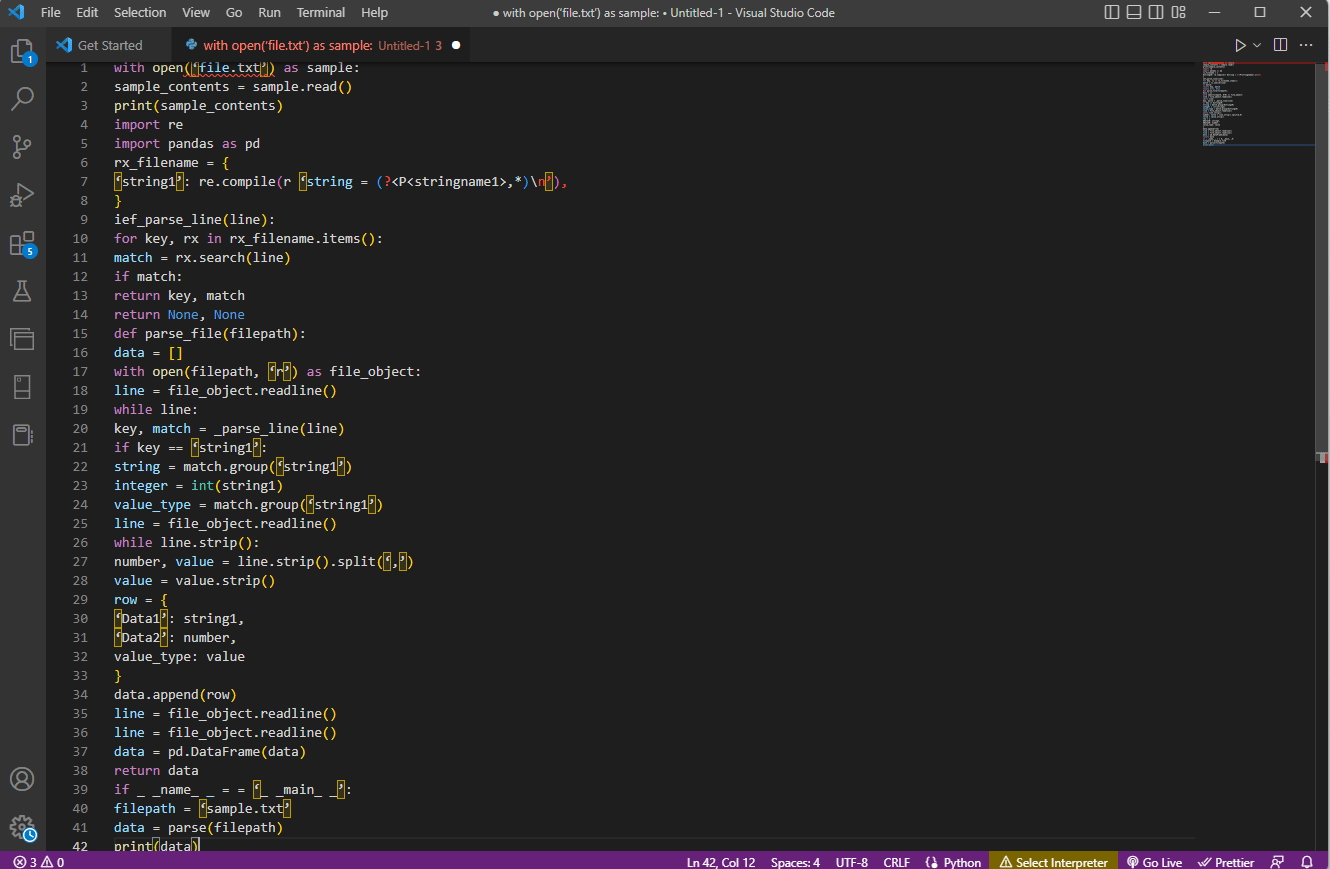
Metode 2: Melalui Tokenisasi Kata
Proses pengubahan teks atau corpus menjadi token atau potongan yang lebih kecil berdasarkan aturan tertentu disebut Tokenization. Untuk mempelajari cara memperbaiki kesalahan penguraian, penting untuk menganalisis perintah tokenisasi kata dalam kode. Mirip dengan regex, aturan sendiri dapat dibuat dalam metode ini dan ini membantu dalam tugas pra-pemrosesan teks seperti memetakan bagian ucapan. Selain itu, aktivitas seperti menemukan dan mencocokkan kata umum, membersihkan teks, dan menyiapkan data untuk teknik analisis teks lanjutan seperti analisis sentimen dilakukan dalam metode ini. Jika tokenisasi tidak tepat, kesalahan dalam teks parse x dapat terjadi.
Perpustakaan Ntlk
Prosesnya membutuhkan bantuan pustaka toolkit bahasa populer yang disebut nltk, yang memiliki serangkaian fungsi yang kaya untuk melakukan banyak pekerjaan NLP. Ini dapat diunduh melalui Paket Instal Pip atau Pip. Untuk mengetahui cara mengurai teks, Anda dapat menggunakan paket dasar distribusi Anaconda yang menyertakan pustaka secara default.
Bentuk Tokenisasi
Bentuk umum dari metode ini adalah tokenisasi kata dan tokenisasi kalimat. Karena token tingkat kata, yang pertama mencetak satu kata hanya sekali, sedangkan yang kedua mencetak kata pada tingkat kalimat.
Proses Parsing Teks
- Pustaka toolkit ntlk diimpor dan formulir tokenisasi diimpor dari pustaka.
- Sebuah string diberikan dan perintah untuk melakukan tokenization diberikan.
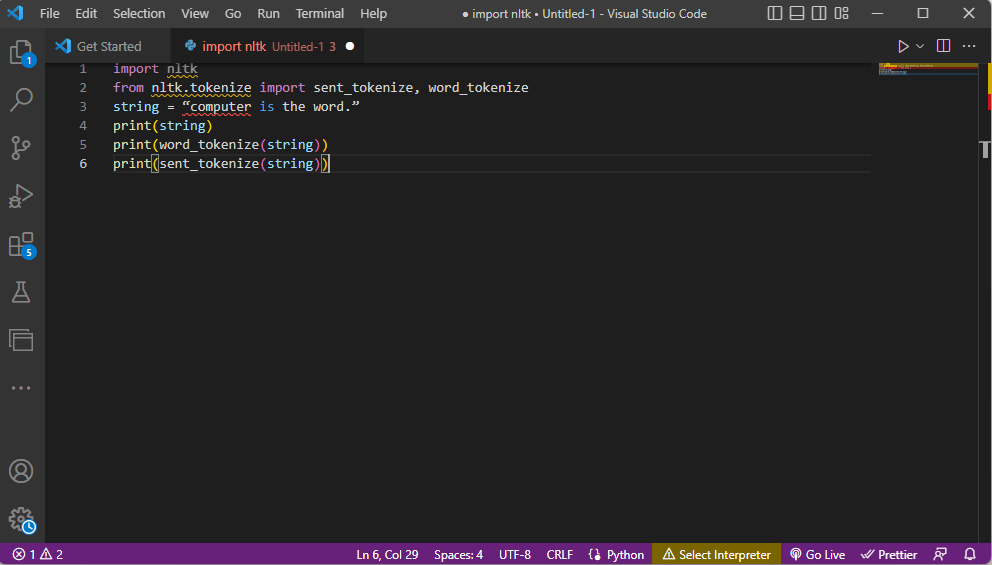
- Saat string dicetak, outputnya adalah komputer adalah kata.
- Dalam kasus tokenisasi kata atau word_tokenize() , setiap kata dalam kalimat dicetak satu per satu di dalam '' dan dipisahkan dengan koma . Output untuk perintah tersebut adalah 'computer', 'is', 'the', 'word', '.'
- Dalam kasus tokenization kalimat atau sent_tokenize() , masing-masing kalimat ditempatkan di dalam '' dan pengulangan kata diperbolehkan. Output untuk perintah tersebut adalah 'computer is the word'.
Kode yang menjelaskan langkah-langkah untuk tokenisasi di atas diberikan di sini.
impor nltk dari nltk.tokenize impor sent_tokenize, word_tokenize string = "komputer adalah kata." cetak (string) cetak(word_tokenize(string)) cetak(dikirim_tokenize(string))
Baca Juga: Cara Memperbaiki Kesalahan javascript:void(0)
Metode 3: Melalui Kelas DocParser
Mirip dengan Kelas DataFrame, Kelas DocParser dapat digunakan untuk mengurai teks dalam kode. Kelas memungkinkan Anda untuk memanggil fungsi parse dengan filepath.
Proses Parsing Teks
Untuk mengetahui cara mengurai teks menggunakan Kelas DocParser, ikuti petunjuk yang diberikan di bawah ini.
- Fungsi get_format(filename) digunakan untuk mengekstrak ekstensi file, mengembalikannya ke variabel yang ditetapkan untuk fungsi tersebut, dan meneruskannya ke fungsi berikutnya. Misalnya, p1 = get_format(filename) akan mengekstrak ekstensi file dari filename , mengaturnya ke variabel p1 , dan meneruskannya ke fungsi berikutnya.
- Struktur logis dengan fungsi lain dibangun menggunakan pernyataan dan fungsi if-elif-else .
- Jika ekstensi file valid dan strukturnya logis, fungsi get_parser digunakan untuk mengurai data di jalur file dan mengembalikan objek string ke pengguna.
Catatan: Untuk mengetahui cara memperbaiki kesalahan parse, fungsi ini harus diterapkan dengan benar.
- Penguraian nilai data dilakukan dengan ekstensi file file. Implementasi konkret dari kelas, yaitu parse_txt atau parse_docx digunakan untuk menghasilkan objek string dari bagian-bagian dari jenis file yang diberikan.
- Penguraian dapat dilakukan untuk file dari ekstensi lain yang dapat dibaca seperti parse_pdf , parse_html , dan parse_pptx .
- Nilai data dan antarmuka dapat diimpor ke aplikasi dengan pernyataan impor dan membuat instance objek DocParser. Ini dapat dilakukan dengan mem-parsing file dalam bahasa Python, seperti parse_file.py . Operasi ini harus dilakukan dengan hati-hati untuk menghindari kesalahan dalam mengurai teks x.
Metode 4: Melalui Alat Teks Parse
Alat teks Parse digunakan untuk mengekstrak data tertentu dari variabel dan memetakannya ke variabel lain. Ini tidak tergantung pada alat lain yang digunakan dalam tugas dan alat Platform BPA digunakan untuk mengkonsumsi dan mengeluarkan variabel. Gunakan tautan yang diberikan di sini untuk mengakses Alat Teks Parse online dan gunakan jawaban yang diberikan sebelumnya tentang cara mengurai teks.
Metode 5: Melalui TextFieldParser (Visual Basic)
TextFieldParser menggunakan objek untuk mengurai dan memproses file yang sangat besar yang terstruktur dan dibatasi. Lebar dan kolom teks seperti file log atau informasi database lama dapat digunakan dalam metode ini. Metode parsing mirip dengan iterasi kode di atas file teks dan terutama digunakan untuk mengekstrak bidang teks yang mirip dengan metode manipulasi string. Ini dilakukan untuk menandai string dan bidang yang dibatasi dengan berbagai lebar menggunakan pembatas yang ditentukan seperti koma atau spasi tab.
Fungsi untuk Mengurai Teks
Fungsi berikut dapat digunakan untuk mengurai teks dalam metode ini.
- Untuk mendefinisikan pembatas, SetDelimiters digunakan. Misalnya, perintah testReader.SetDelimiters (vbTab) digunakan untuk mengatur ruang tab sebagai pembatas.
- Untuk menyetel lebar bidang ke nilai bilangan bulat positif ke lebar bidang tetap dari file teks, Anda dapat menggunakan perintah testReader.SetFieldWidths (bilangan bulat) .
- Untuk menguji jenis bidang teks, Anda dapat menggunakan perintah berikut testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth .
Metode untuk Menemukan MatchObject
Ada dua metode dasar untuk menemukan MatchObject dalam kode atau teks yang diurai.
- Metode pertama adalah mendefinisikan format dan loop melalui file menggunakan metode ReadFields . Metode ini akan membantu dalam memproses setiap baris kode.
- Metode PeekChars digunakan untuk memeriksa setiap bidang secara individual sebelum membacanya, menentukan berbagai format, dan bereaksi.
Dalam kedua kasus tersebut, jika bidang tidak cocok dengan format yang ditentukan saat melakukan penguraian atau menemukan cara mengurai teks, pengecualian MalformedLineException dikembalikan.
Kiat Pro: Cara Mengurai Teks Melalui MS Excel
Sebagai metode terakhir dan sederhana untuk mengurai teks, Anda dapat menggunakan aplikasi MS Excel sebagai pengurai untuk membuat file yang dibatasi tab dan dipisahkan koma. Ini akan membantu dalam pemeriksaan silang dengan hasil parsing Anda dan membantu dalam menemukan cara memperbaiki kesalahan parse.
1. Pilih nilai data dalam file sumber dan tekan tombol Ctrl + C bersamaan untuk menyalin file.
2. Buka aplikasi Excel menggunakan bilah pencarian windows.
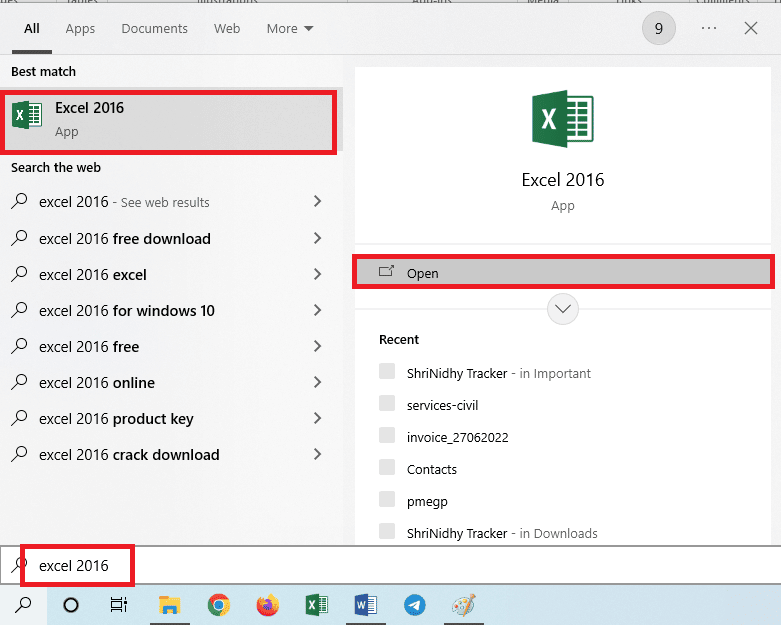
3. Klik pada sel A1 dan tekan tombol Ctrl + V secara bersamaan untuk menempelkan teks yang disalin.
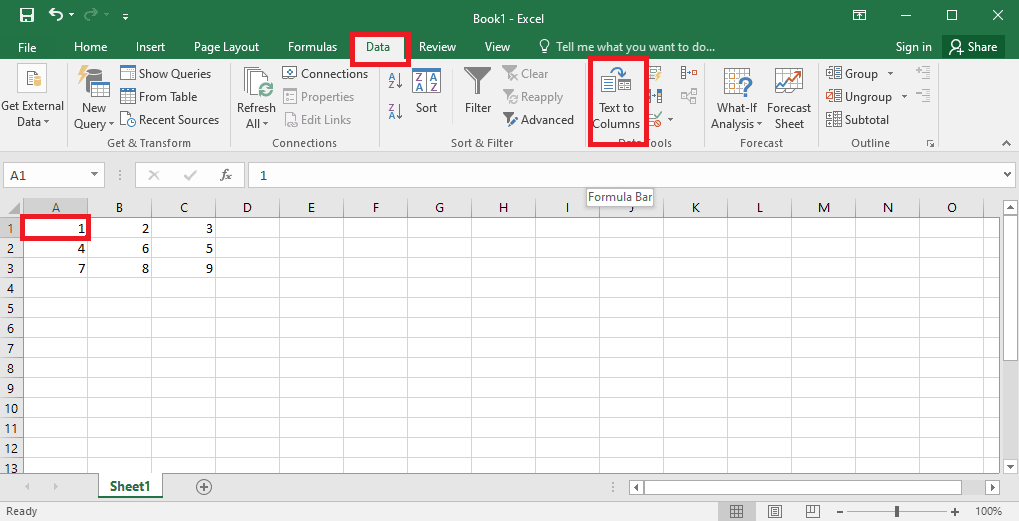
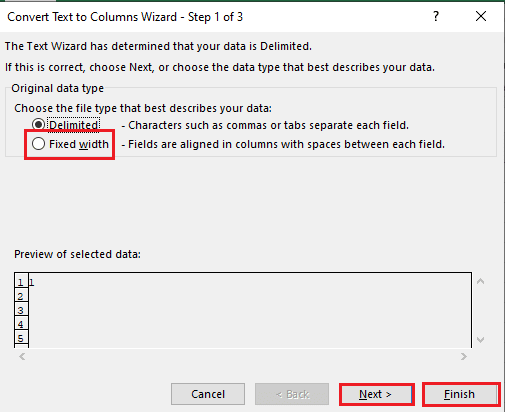
4. Pilih sel A1 , navigasikan ke tab Data , dan klik opsi Teks ke kolom di bagian Alat Data .
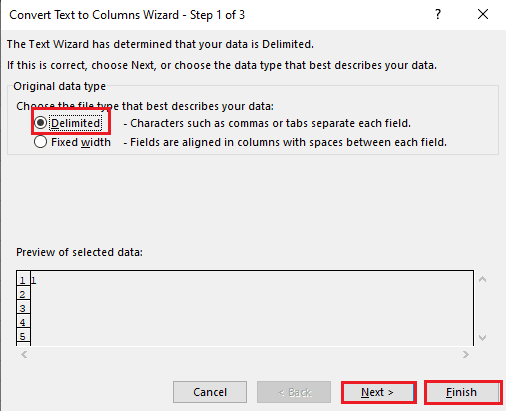
5A. Pilih opsi Dibatasi jika koma atau spasi tab digunakan sebagai pemisah, dan klik tombol Berikutnya dan Selesai .
5B. Pilih opsi Lebar tetap , tetapkan nilai untuk pemisah, dan klik tombol Berikutnya dan Selesai .
Baca Juga: Cara Memperbaiki Kesalahan Pindah Kolom Excel
Cara Memperbaiki Kesalahan Parse
Kesalahan dalam mengurai teks x dapat terjadi pada perangkat Android sebagai, Kesalahan Parse: Ada masalah saat menguraikan paket. Ini biasanya terjadi ketika aplikasi gagal dipasang dari Google Play Store atau saat menjalankan aplikasi pihak ketiga.
Teks kesalahan x dapat terjadi jika daftar vektor karakter dilingkarkan dan fungsi lain membentuk model linier untuk menghitung nilai data. Pesan kesalahannya adalah Error in parse(text = x, keep.source = FALSE):<text>:2.0:akhir input yang tidak terduga 1:OffenceAgainst ~ ^.
Anda dapat membaca artikel tentang cara memperbaiki kesalahan parse di Android untuk mempelajari penyebab dan metode untuk memperbaiki kesalahan.
Terlepas dari solusi dalam panduan ini, Anda dapat mencoba perbaikan berikut.
- Mengunduh ulang file .apk atau memulihkan nama file.
- Memulihkan perubahan dalam file Androidmanifest.xml , jika Anda memiliki keterampilan pemrograman tingkat ahli.
Direkomendasikan:
- Cara Menghapus Akun Facebook Orang Lain
- 10 Keterampilan Teratas yang Diperlukan untuk Menjadi Peretas Etis
- 21 Alternatif Pastebin Terbaik untuk Berbagi Kode dan Teks
- Perbaiki Perintah Gagal Dengan Kode Kesalahan 1 Info Telur Python
Artikel ini membantu dalam mengajarkan cara mengurai teks dan mempelajari cara memperbaiki kesalahan penguraian. Beri tahu kami metode mana yang membantu memperbaiki kesalahan dalam teks parse x dan metode penguraian mana yang lebih disukai. Silakan bagikan saran dan pertanyaan Anda di bagian komentar di bawah.