
Bagaimana Melakukan OCR dari Baris Perintah Linux Menggunakan Tesseract
Diterbitkan: 2022-01-29
Anda dapat mengekstrak teks dari gambar di baris perintah Linux menggunakan mesin Tesseract OCR. Ini cepat, akurat, dan berfungsi dalam sekitar 100 bahasa. Berikut cara menggunakannya.
Pengenalan Karakter Optik
Pengenalan karakter optik (OCR) adalah kemampuan untuk melihat dan menemukan kata-kata dalam gambar, dan kemudian mengekstraknya sebagai teks yang dapat diedit. Tugas sederhana bagi manusia ini sangat sulit dilakukan oleh komputer. Upaya awal yang kikuk, untuk sedikitnya. Komputer sering bingung jika jenis huruf atau ukurannya tidak sesuai dengan keinginan perangkat lunak OCR.
Meski demikian, para pionir di bidang ini tetap dijunjung tinggi. Jika Anda kehilangan salinan elektronik dokumen, tetapi masih memiliki versi cetak, OCR dapat membuat ulang versi elektronik yang dapat diedit. Bahkan jika hasilnya tidak 100 persen akurat, ini masih merupakan penghemat waktu yang hebat.
Dengan beberapa pembersihan manual, Anda akan mendapatkan kembali dokumen Anda. Orang-orang memaafkan kesalahan yang dibuat karena mereka memahami kompleksitas tugas yang dihadapi paket OCR. Plus, itu lebih baik daripada mengetik ulang seluruh dokumen.
Hal-hal telah meningkat secara signifikan sejak saat itu. Aplikasi Tesseract OCR, yang ditulis oleh Hewlett Packard, dimulai pada 1980-an sebagai aplikasi komersial. Itu open-source pada tahun 2005, dan sekarang didukung oleh Google. Ini memiliki kemampuan multi-bahasa, dianggap sebagai salah satu sistem OCR paling akurat yang tersedia, dan Anda dapat menggunakannya secara gratis.
Menginstal Tesseract OCR
Untuk menginstal Tesseract OCR di Ubuntu, gunakan perintah ini:
sudo apt-get install tesseract-ocr

Di Fedora, perintahnya adalah:
sudo dnf instal tesseract

Di Manjaro, Anda perlu mengetik:
sudo pacman -Syu tesseract

Menggunakan Tesseract OCR
Kami akan mengajukan serangkaian tantangan untuk Tesseract OCR. Gambar pertama kami yang berisi teks adalah ekstrak dari Recital 63 dari Peraturan Perlindungan Data Umum. Mari kita lihat apakah OCR dapat membaca ini (dan tetap terjaga).

Ini gambar yang rumit karena setiap kalimat dimulai dengan nomor superskrip yang samar, yang merupakan ciri khas dalam dokumen legislatif.
Kita perlu memberikan perintah tesseract beberapa informasi, termasuk:
- Nama file gambar yang ingin kita proses.
- Nama file teks yang akan dibuat untuk menampung teks yang diekstraksi. Kami tidak harus memberikan ekstensi file (akan selalu .txt). Jika file sudah ada dengan nama yang sama, itu akan ditimpa.
- Kita dapat menggunakan opsi
--dpiuntuk memberi tahutesseracttentang resolusi titik per inci (dpi) gambar. Jika kami tidak memberikan nilai dpi,tesseractakan mencoba mencari tahu.
File gambar kami bernama "recital-63.png," dan resolusinya adalah 150 dpi. Kami akan membuat file teks darinya yang disebut "recital.txt."
Perintah kami terlihat seperti ini:
resital tesseract-63.png resital --dpi 150

Hasilnya sangat bagus. Satu-satunya masalah adalah superskrip—terlalu redup untuk dibaca dengan benar. Kualitas gambar yang baik sangat penting untuk mendapatkan hasil yang baik.

tesseract telah menafsirkan angka superskrip sebagai tanda kutip (“) dan simbol derajat (°), tetapi teks sebenarnya telah diekstraksi dengan sempurna (sisi kanan gambar harus dipangkas agar pas di sini).
Karakter terakhir adalah byte dengan nilai heksadesimal 0x0C, yang merupakan carriage return.
Di bawah ini adalah gambar lain dengan teks dalam ukuran berbeda, dan dicetak tebal dan miring.

Nama file ini adalah “bold-italic.png.” Kami ingin membuat file teks bernama “bold.txt”, jadi perintah kami adalah:
tesseract bold-italic.png bold --dpi 150

Yang ini tidak menimbulkan masalah, dan teksnya diekstraksi dengan sempurna.

Menggunakan Bahasa yang Berbeda
Tesseract OCR mendukung sekitar 100 bahasa. Untuk menggunakan bahasa, Anda harus menginstalnya terlebih dahulu. Saat Anda menemukan bahasa yang ingin Anda gunakan dalam daftar, catat singkatannya. Kami akan memasang dukungan untuk Welsh. Singkatannya adalah "cym," yang merupakan kependekan dari "Cymru," yang berarti Welsh.
Paket instalasi disebut "tesseract-ocr-" dengan singkatan bahasa yang ditandai di bagian akhir. Untuk menginstal file bahasa Welsh di Ubuntu, kami akan menggunakan:

sudo apt-get install tesseract-ocr-cym

Gambar dengan teks di bawah ini. Ini adalah bait pertama dari lagu kebangsaan Welsh.

Mari kita lihat apakah Tesseract OCR siap menghadapi tantangan. Kami akan menggunakan opsi -l (bahasa) untuk memberi tahu tesseract bahasa yang ingin kami gunakan:
tesseract hen-wlad-fy-nhadau.png anthem -l cym --dpi 150

tesseract mengatasi dengan sempurna, seperti yang ditunjukkan pada teks yang diekstraksi di bawah ini. Diawn , Tesseract OCR.

Jika dokumen Anda berisi dua bahasa atau lebih (seperti kamus Welsh-ke-Inggris, misalnya), Anda dapat menggunakan tanda plus ( + ) untuk memberi tahu tesseract agar menambahkan bahasa lain, seperti:
tesseract image.png file teks -l eng+cym+fra
Menggunakan Tesseract OCR dengan PDF
Perintah tesseract dirancang untuk bekerja dengan file gambar, tetapi tidak dapat membaca PDF. Namun, jika Anda perlu mengekstrak teks dari PDF, Anda dapat menggunakan utilitas lain terlebih dahulu untuk menghasilkan satu set gambar. Satu gambar akan mewakili satu halaman PDF.
Utilitas pdftppm yang Anda butuhkan seharusnya sudah diinstal di komputer Linux Anda. PDF yang akan kita gunakan sebagai contoh adalah salinan makalah Alan Turing tentang kecerdasan buatan, “Mesin Komputer dan Kecerdasan.”

Kami menggunakan opsi -png untuk menentukan bahwa kami ingin membuat file PNG. Nama file PDF kami adalah “turing.pdf.” Kami akan memanggil file gambar kami "turing-01.png," "turing-02.png," dan seterusnya:
pdftoppm -png turing.pdf turing

Untuk menjalankan tesseract pada setiap file gambar menggunakan satu perintah, kita perlu menggunakan for loop. Untuk setiap file “turing- nn .png”, kami menjalankan tesseract , dan membuat file teks bernama “text-” plus “turing- nn ” sebagai bagian dari nama file gambar:
untuk saya di turing-??.png; lakukan tesseract "$i" "text-$i" -l eng; selesai;

Untuk menggabungkan semua file teks menjadi satu, kita dapat menggunakan cat :
cat text-turing* > complete.txt

Jadi, bagaimana melakukannya? Sangat baik, seperti yang Anda lihat di bawah ini. Halaman pertama terlihat cukup menantang. Ini memiliki gaya dan ukuran teks yang berbeda, dan dekorasi. Ada juga "tanda air" vertikal di tepi kanan halaman.
Namun, outputnya mendekati aslinya. Jelas, formatnya hilang, tetapi teksnya benar.
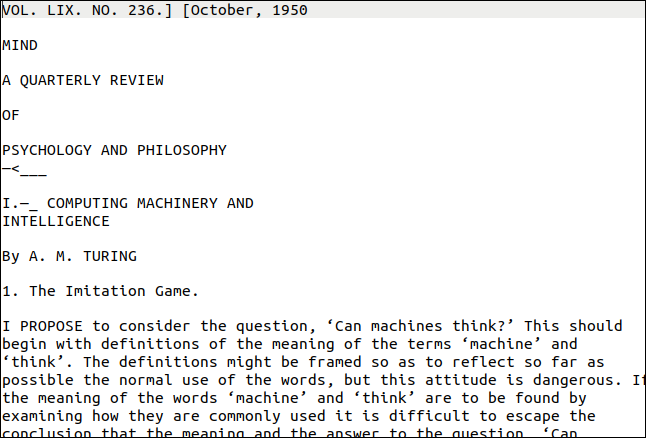
Tanda air vertikal ditranskripsikan sebagai garis omong kosong di bagian bawah halaman. Teks itu terlalu kecil untuk dibaca oleh tesseract secara akurat, tetapi akan cukup mudah untuk menemukan dan menghapusnya. Hasil terburuk adalah karakter tersesat di akhir setiap baris.
Anehnya, satu huruf di awal daftar pertanyaan dan jawaban di halaman dua diabaikan. Bagian dari PDF ditunjukkan di bawah ini.

Seperti yang Anda lihat di bawah, pertanyaan tetap ada, tetapi "Q" dan "A" di awal setiap baris hilang.

Diagram juga tidak akan ditranskripsi dengan benar. Mari kita lihat apa yang terjadi ketika kita mencoba mengekstrak yang ditunjukkan di bawah ini dari Turing PDF.

Seperti yang Anda lihat di hasil kami di bawah, karakter telah dibaca, tetapi format diagramnya hilang.

Sekali lagi, tesseract berjuang dengan ukuran kecil dari subskrip, dan mereka dirender dengan tidak benar.
Dalam keadilan, meskipun, itu masih hasil yang baik. Kami tidak dapat mengekstrak teks langsung, tetapi kemudian, contoh ini sengaja dipilih karena menghadirkan tantangan.
Solusi Bagus Saat Anda Membutuhkannya
OCR bukanlah sesuatu yang harus Anda gunakan setiap hari. Namun, ketika dibutuhkan, ada baiknya mengetahui bahwa Anda memiliki salah satu mesin OCR terbaik yang Anda inginkan.