
Comment fonctionne le moteur de recherche et vous facilite la vie ?
Publié: 2015-11-06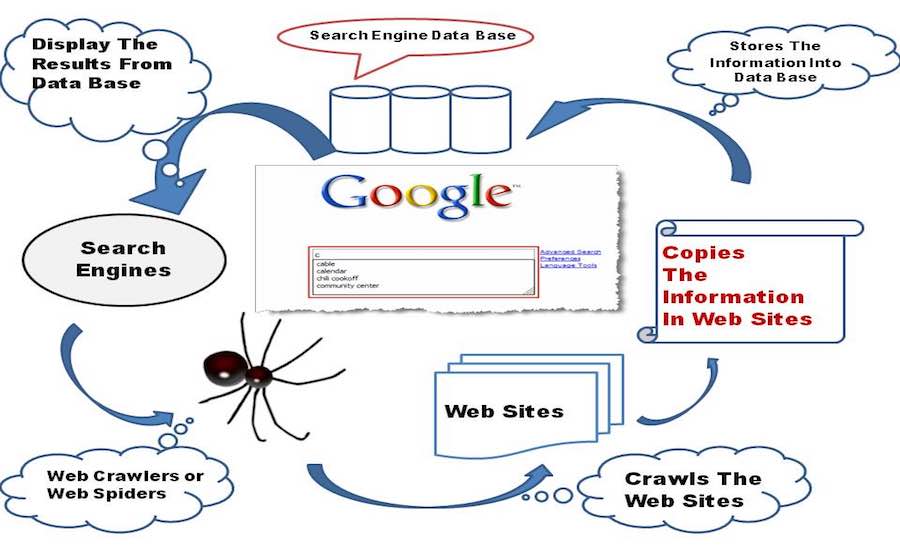 Short Bytes : Search Engine est un logiciel qui permet d'afficher des résultats de pages Web pertinents en fonction de la requête de recherche saisie par l'utilisation de Web Crawling et Web Indexing, de formules grasses et d'algorithmes intelligents afin de collecter les données appropriées.
Short Bytes : Search Engine est un logiciel qui permet d'afficher des résultats de pages Web pertinents en fonction de la requête de recherche saisie par l'utilisation de Web Crawling et Web Indexing, de formules grasses et d'algorithmes intelligents afin de collecter les données appropriées.
Comment Google vous sert les meilleurs résultats en un clin d'œil ? En fait, cela n'a pas d'importance jusqu'à ce que Google, Bing soient là. Le scénario aurait été très différent s'il n'y avait pas eu Google, Bing ou Yahoo. Plongeons-nous dans le monde des moteurs de recherche et voyons comment fonctionne un moteur de recherche.
Regardant dans l'histoire
Le conte de fées des moteurs de recherche a commencé dans les années 1990 lorsque Tim Berners-Lee avait l'habitude d'inscrire chaque nouveau serveur Web mis en ligne sur la liste maintenue par le serveur Web du CERN. Jusqu'en septembre 93, aucun moteur de recherche n'existait sur Internet mais seulement quelques outils capables de maintenir une base de données de noms de fichiers. Archie, Veronica, Jughead ont été les tout premiers entrants dans cette catégorie.
Oscar Nierstrasz de l'Université de Genève est accrédité pour le tout premier moteur de recherche qui a vu le jour, nommé W3Catalog. Il a fait quelques scripts Perl sérieux et est finalement sorti avec le premier moteur de recherche au monde le 3 septembre 1993. De plus, l'année 1993 a vu l'avènement de nombreux autres moteurs de recherche. JumpStation par Jonathon Fletcher, AliWeb, ver WWW, etc. Yahoo! a été lancé en 1995 en tant que répertoire Web, mais il a commencé à utiliser le moteur de recherche d'Inktomi à partir de 2000, puis est passé à Bing de Microsoft en 2009.
Maintenant, en parlant du nom qui est le principal synonyme du terme moteur de recherche, Google Search, était un projet de recherche pour deux diplômés de Stanford, Larry Page et Sergy Brin, ayant ses premières empreintes en mars 1995. Le travail de Google a été initialement inspiré par la méthode de back-linking de Page qui a effectué des calculs basés sur le nombre de backlinks provenant d'une page Web, afin de mesurer l'importance de cette page dans le World Wide Web. "Le meilleur conseil que j'aie jamais reçu", a déclaré Page, tout en se rappelant comment son superviseur Terry Winograd avait soutenu son idée. Et depuis lors, Google n'a jamais regardé en arrière.
Tout commence par un crawl
Un bébé moteur de recherche à ses débuts commence à explorer le World Wide Web, avec ses petites mains et ses genoux, il explore tous les autres liens qu'il trouve sur une page Web et les stocke dans sa base de données.
Maintenant, concentrons-nous sur quelques réflexions techniques en coulisses, un moteur de recherche intègre un logiciel Web Crawler qui est essentiellement un bot Internet chargé d'ouvrir tous les hyperliens présents sur une page Web et de créer une base de données de texte et de métadonnées à partir de tous les liens . Cela commence par un premier ensemble de liens à visiter, appelés Seeds. Dès qu'il procède à la visite de ces liens, ajoute de nouveaux liens dans la liste existante des URL à visiter, connue sous le nom de Crawl Frontier.
Au fur et à mesure que le Crawler parcourt les liens, il télécharge les informations de ces pages Web pour les consulter plus tard sous forme d'instantanés, car le téléchargement de la page Web entière nécessiterait beaucoup de données, et cela coûte cher, du moins dans des pays comme l'Inde. Et je peux parier que si Google était fondé en Inde, tout leur argent serait utilisé pour payer les factures Internet. Espérons que ce ne soit pas un sujet de préoccupation pour le moment.
Le robot d'exploration Web explore les pages Web en fonction de certaines politiques :
Politique de sélection : le robot d'exploration décide des pages qu'il doit télécharger et de celles qu'il ne doit pas télécharger. La politique de sélection se concentre sur le téléchargement du contenu le plus pertinent d'une page Web plutôt que sur certaines données sans importance.
Politique de nouvelle visite : le robot d'exploration planifie l'heure à laquelle il doit rouvrir les pages Web et modifier les modifications dans sa base de données, grâce à la nature dynamique d'Internet, ce qui rend très difficile pour les robots d'exploration de rester à jour avec les dernières versions de les pages Web.
Politique de parallélisation : les robots d'exploration utilisent plusieurs processus à la fois pour explorer les liens connus sous le nom d'exploration distribuée, mais il est parfois possible que différents processus téléchargent la même page Web, de sorte que le robot d'exploration maintient une coordination entre tous les processus pour éliminer tout risque de duplicité.
Politique de politesse : lorsqu'un robot parcourt un site Web, il télécharge simultanément des pages Web à partir de celui-ci, augmentant ainsi la charge sur le serveur Web hébergeant le site Web. Par conséquent, un terme "Crawl-Delay" est implémenté dans lequel le crawler doit attendre quelques secondes après avoir téléchargé des données à partir d'un serveur Web, et est régi par la politique de politesse.
A lire également : Comment créer un robot d'indexation Web de base en Python
Architecture de haut niveau d'un Web Crawler standard :
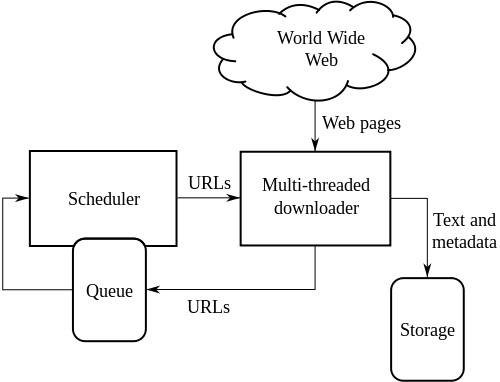
L'illustration ci-dessus décrit le fonctionnement d'un robot d'indexation Web. Il ouvre la liste initiale des liens, puis les liens à l'intérieur de ces liens et ainsi de suite.
Wikipedia écrit, les chercheurs en informatique Vladislav Shkapenyuk et Torsten Suel ont noté que :
Bien qu'il soit assez facile de construire un robot d'exploration lent qui télécharge quelques pages par seconde pendant une courte période, la construction d'un système haute performance capable de télécharger des centaines de millions de pages sur plusieurs semaines présente un certain nombre de défis dans la conception du système, Efficacité des E/S et du réseau, robustesse et gérabilité.
Indexer les crawls
Une fois que le bébé moteur de recherche a parcouru Internet, il crée un index de toutes les pages Web qu'il trouve sur son chemin. Avoir un index est bien mieux que de perdre du temps à trouver la requête de recherche à partir d'un tas de documents de grande taille, cela vous fera gagner du temps et des ressources.
De nombreux facteurs contribuent à créer un système d'indexation efficace pour un moteur de recherche. Les techniques de stockage utilisées par les indexeurs, la taille de l'index, la possibilité de retrouver rapidement les documents contenant les mots clés recherchés, etc. sont les facteurs responsables de l'efficacité et de la fiabilité d'un index.
L'un des principaux obstacles sur la voie de la création d'index Web réussis est la collision entre deux processus. Supposons qu'un processus souhaite rechercher un document et qu'un autre processus souhaite en même temps ajouter un document dans l'index, ce qui crée en quelque sorte un conflit entre les deux processus. Le problème est encore aggravé par la mise en œuvre de l'informatique distribuée par les moteurs de recherche afin de traiter plus de données.
Types d'indices
Avant : Dans ce type d'index, tous les mots-clés présents dans un document sont stockés dans une liste. L'index avant est facile à créer dans la phase de démarrage de l'indexation car il permet aux indexeurs asynchrones de collaborer les uns avec les autres.
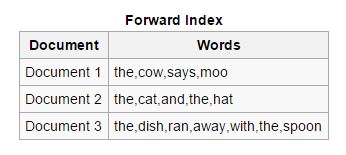
Inverse : les index avant sont triés et convertis en index inversés, dans lesquels chaque document contenant un mot-clé spécifique est regroupé avec d'autres documents contenant ce mot-clé. Les index inversés facilitent le processus de recherche de documents pertinents pour une requête de recherche donnée, ce qui n'est pas le cas des index avancés.

Lire aussi : Qu'est-ce que le DNS (Domain Name System) et comment ça marche ?
Analyse de documents
Également appelée Tokenisation, fait référence à la répartition des composants d'un document tels que les mots-clés (appelés jetons), les images et autres médias, afin qu'ils puissent être insérés ultérieurement dans des index. La méthode se concentre essentiellement sur la compréhension de la langue maternelle et la prédiction des mots-clés qu'un utilisateur pourrait rechercher, qui servent de base à la création d'un système d'indexation Web efficace.
Les principaux défis incluent la recherche des limites de mots des mots-clés à extraire, car nous pouvons voir que des langues comme le chinois et le japonais n'ont généralement pas d'espaces blancs dans leurs scripts de langue. Comprendre l'ambiguïté d'une langue est également un sujet de préoccupation, car certaines langues commencent à différer légèrement, voire considérablement, avec les changements géographiques. De plus, l'inefficacité de certaines pages Web à ne pas mentionner clairement la langue utilisée est également un sujet de préoccupation et augmente la charge de travail des indexeurs.
Les moteurs de recherche ont la capacité de reconnaître divers formats de fichiers et d'en extraire avec succès des données, et il est nécessaire que le plus grand soin soit pris dans ces cas.
Les balises Meta sont également très utiles pour créer les index très rapidement, elles réduisent les efforts de l'indexeur Web et facilitent l'analyse complète de l'ensemble du document. Vous trouverez les balises Meta jointes au bas de cet article.
Recherche dans l'index
Maintenant, le bébé moteur de recherche n'est plus un bébé, il a appris à ramper et à saisir les choses rapidement et efficacement, et à organiser ses affaires systématiquement. Supposons que son ami lui demande de trouver quelque chose dans son arrangement, que fera-t-il ? Il existe quatre types de requêtes de recherche en cours d'utilisation, bien qu'elles ne soient pas formellement dérivées, mais elles ont évolué au fil du temps et se sont avérées valables en termes de requêtes réelles effectuées par les utilisateurs.
Navigation : ce terme est utilisé pour les requêtes dans lesquelles l'utilisateur souhaite accéder à une page Web spécifique ou à un site Web existant sur Internet. Par exemple, lorsque vous recherchez fossBytes sur Google, vous lancez une requête de navigation.
Informationnel : Ce type de requêtes a des milliers de résultats et couvre des sujets généraux qui améliorent les connaissances de l'utilisateur. Par exemple, lorsque vous recherchez, disons, Steve Jobs, tous les liens pertinents à Steve Jobs s'affichent.
Transactionnel : les requêtes axées sur l'intention de l'utilisateur d'effectuer une action particulière peuvent impliquer un ensemble prédéfini d'instructions. Par exemple, comment retrouver votre ordinateur portable perdu/volé ?
Connectivité : ces types de requêtes ne sont pas fréquemment utilisés, ils se concentrent sur le degré de connexion de l'index créé à partir d'un site Web. Par exemple, si vous recherchez, combien de pages y a-t-il sur Wikipédia ?
Google et Bing ont créé des algorithmes sérieux qui sont suffisamment capables de déterminer les résultats les plus pertinents pour votre requête. Google prétend calculer vos résultats de recherche en fonction de plus de 200 facteurs tels que la qualité du contenu, nouveau ou ancien, la sécurité de la page Web et bien d'autres. Ils ont nommé les plus grands esprits du monde dans leurs laboratoires de recherche, qui effectuent des calculs difficiles et traitent des formules époustouflantes, uniquement pour rendre la recherche plus simple et plus rapide pour vous.
Autres caractéristiques notables*
Recherche d'images : vous serez surpris de connaître l'inspiration de Google derrière son célèbre outil de recherche d'images. J.Lo, ouais vous avez bien entendu, J.Lo et sa robe verte Versace (ver-sah-chay) aux Grammy Awards, 2000, étaient la vraie raison pour laquelle Google a lancé sa recherche d'images, alors que les gens étaient occupés à chercher sur Google son.
Dit Eric Schmidt dans son écrit intitulé « The Tinkerer's Apprentice », publié le 19 janvier 2015.
Recherche vocale : Google a été le premier à introduire la recherche vocale sur son moteur de recherche après beaucoup de travail acharné et par la suite, d'autres moteurs de recherche l'ont également implémentée.
Lutte anti-spam : les moteurs de recherche déploient des algorithmes sérieux, afin de vous protéger des attaques de spam . Un spam est essentiellement un message ou un fichier qui se propage partout sur Internet, peut-être à des fins publicitaires ou pour transmettre des virus. Dans cette affaire également, les gars de Google informent manuellement le site Web qu'ils trouvent responsable de la diffusion de messages de spam sur Internet.
Optimisation de la localisation : les moteurs de recherche sont désormais capables d'afficher des résultats en fonction de la localisation de l'utilisateur. Si la recherche, quel temps fait-il à Bangalore, les statistiques météorologiques seront en référence avec Bangalore.
Vous comprend mieux : les moteurs de recherche modernes sont capables de comprendre le sens de la requête de l'utilisateur plutôt que de trouver les mots clés saisis par l'utilisateur.
Saisie semi-automatique : la possibilité de prédire votre requête de recherche au fur et à mesure que vous tapez en fonction de vos recherches précédentes et des recherches effectuées par d'autres utilisateurs.
Knowledge Graph : Cette fonctionnalité, fournie par Google Search, montre sa capacité à fournir des résultats de recherche basés sur des personnes, des lieux et des événements réels.
Contrôle parental : les moteurs de recherche permettent aux parents de petits groupes de contrôler ce que leur enfant a fait sur Internet.
* Il est difficile de couvrir la vaste liste de fonctionnalités fournies par ces puissants moteurs de recherche.
Liquidation
Les moteurs de recherche ont contribué à nous simplifier la vie et le travail acharné qu'ils ont accompli pour exploiter toutes les informations sur Internet n'a pas de prix. Mais cette exploration a conduit à l'exposition de notre espace personnel sur une plateforme publique, et je dois dire qu'il est grand temps que nous nous agitions sur le chemin que nous avons parcouru tout ce temps, à moins qu'il ne soit trop tard pour que nous rétrospections nos actions. et notre vie ne sera qu'une biennale d'embarras. Nous ne pouvons pas nier le fait que les moteurs de recherche sont désormais une partie essentielle de notre double personnalité numérique. Nous devons seulement utiliser la technologie qui nous a été donnée, ne pas lui permettre de nous asservir dans les chaînes de nos propres méfaits.
D'accord, plus de discussions émotionnelles, adorez simplement la gentillesse et les talents de ce bébé moteur de recherche qui est maintenant devenu un adolescent et qui vous comprend beaucoup mieux. Google a été là pour tout rechercher pour nous, c'est Internet pour beaucoup d'entre nous, et nous devons chérir ces bonnes expériences que nous avons gagnées en utilisant la recherche Google. Oh! J'ai oublié de mentionner Bing, tu es génial aussi. Restez vigilant, restez en sécurité et Googlez-le.
Regardez cette vidéo et apprenez-en plus sur les moteurs de recherche :
Avez-vous déjà cliqué sur le bouton J'ai de la chance dans la recherche Google. Ouvrez-le et dites-nous quel doodle vous avez le plus aimé dans la section des commentaires ci-dessous.