
Comment analyser les données CSV dans Bash
Publié: 2022-09-16
Les fichiers de valeurs séparées par des virgules (CSV) sont l'un des formats les plus courants pour les données exportées. Sous Linux, nous pouvons lire les fichiers CSV à l'aide des commandes Bash. Mais ça peut devenir très compliqué, très vite. Nous vous donnerons un coup de main.
Qu'est-ce qu'un fichier CSV ?
Un fichier de valeurs séparées par des virgules est un fichier texte contenant des données tabulées. CSV est un type de données délimitées. Comme son nom l'indique, une virgule " , " est utilisée pour séparer chaque champ de données (ou valeur ) de ses voisins.
CSV est partout. Si une application a des fonctions d'importation et d'exportation, elle prendra presque toujours en charge CSV. Les fichiers CSV sont lisibles par l'homme. Vous pouvez regarder à l'intérieur avec less, les ouvrir dans n'importe quel éditeur de texte et les déplacer d'un programme à l'autre. Par exemple, vous pouvez exporter les données d'une base de données SQLite et l'ouvrir dans LibreOffice Calc.
Cependant, même CSV peut devenir compliqué. Vous voulez avoir une virgule dans un champ de données ? Ce champ doit être entouré de guillemets « " ». Pour inclure des guillemets dans un champ, chaque guillemet doit être entré deux fois.
Bien sûr, si vous travaillez avec un CSV généré par un programme ou un script que vous avez écrit, le format CSV est susceptible d'être simple et direct. Si vous êtes obligé de travailler avec des formats CSV plus complexes, Linux étant Linux, il existe également des solutions que nous pouvons utiliser pour cela.
Quelques exemples de données
Vous pouvez facilement générer des exemples de données CSV en utilisant des sites comme Online Data Generator. Vous pouvez définir les champs souhaités et choisir le nombre de lignes de données souhaitées. Vos données sont générées à l'aide de valeurs fictives réalistes et téléchargées sur votre ordinateur.
Nous avons créé un fichier contenant 50 lignes d'informations sur les employés factices :
- id : Une simple valeur entière unique.
- firstname : Le prénom de la personne.
- lastname : Le nom de famille de la personne.
- job-title : Intitulé du poste de la personne.
- email-address : L'adresse email de la personne.
- branch : La branche de l'entreprise dans laquelle ils travaillent.
- state : L'état dans lequel se trouve la succursale.
Certains fichiers CSV ont une ligne d'en-tête qui répertorie les noms de champs. Notre exemple de fichier en contient un. Voici le haut de notre dossier :
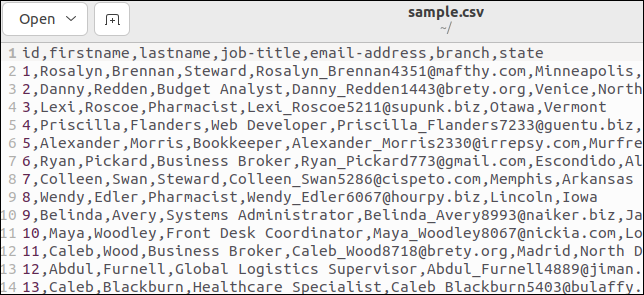
La première ligne contient les noms de champs sous forme de valeurs séparées par des virgules.
Analyser les données du fichier CSV
Écrivons un script qui lira le fichier CSV et extraira les champs de chaque enregistrement. Copiez ce script dans un éditeur et enregistrez-le dans un fichier appelé "field.sh".
# ! /bin/bash while IFS="," read -r id firstname lastname jobtitle email branch state fais echo "ID d'enregistrement : $id" echo "Prénom : $prénom" echo "Nom : $nom" echo "Titre du poste : $jobtitle" echo "Email ajouter : $email" echo " Branche : $branche" echo "Etat : $état" écho "" fait < <(tail -n +2 sample.csv)
Il y a pas mal de choses dans notre petit script. Décomposons-le.

Nous utilisons une boucle while . Tant que la condition de la boucle while est résolue sur true, le corps de la boucle while sera exécuté. Le corps de la boucle est assez simple. Une collection d'instructions echo est utilisée pour imprimer les valeurs de certaines variables dans la fenêtre du terminal.
La condition de la boucle while est plus intéressante que le corps de la boucle. Nous spécifions qu'une virgule doit être utilisée comme séparateur de champ interne, avec l'instruction IFS="," . L'IFS est une variable d'environnement. La commande de read fait référence à sa valeur lors de l'analyse de séquences de texte.
Nous utilisons l'option -r (conserver les barres obliques inverses) de la commande read pour ignorer les barres obliques inverses pouvant se trouver dans les données. Ils seront traités comme des personnages normaux.
Le texte analysé par la commande de read est stocké dans un ensemble de variables nommées d'après les champs CSV. Ils auraient tout aussi bien pu être nommés field1, field2, ... field7 , mais des noms significatifs facilitent la vie.
Les données sont obtenues en sortie de la commande tail . Nous utilisons tail car cela nous donne un moyen simple de sauter la ligne d'en-tête du fichier CSV. L'option -n +2 (numéro de ligne) indique à tail de commencer la lecture à la ligne numéro deux.
La construction <(...) est appelée substitution de processus. Cela amène Bash à accepter la sortie d'un processus comme si elle provenait d'un descripteur de fichier. Celui-ci est ensuite redirigé vers la boucle while , fournissant le texte que la commande de read analysera.
Rendez le script exécutable à l'aide de la commande chmod . Vous devrez le faire chaque fois que vous copierez un script de cet article. Remplacez le nom du script approprié dans chaque cas.
chmod +x champ.sh

Lorsque nous exécutons le script, les enregistrements sont correctement divisés en leurs champs constitutifs, chaque champ étant stocké dans une variable différente.
./champ.sh
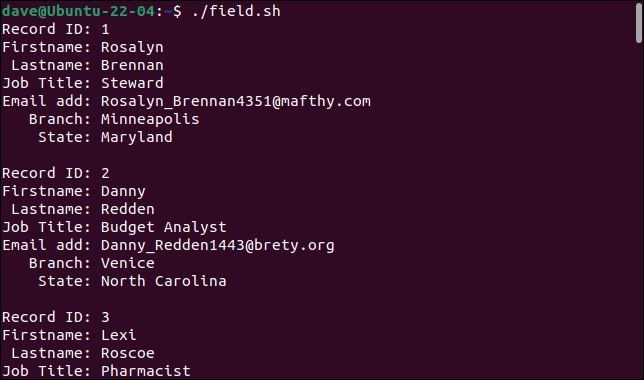
Chaque enregistrement est imprimé sous la forme d'un ensemble de champs.
Sélection des champs
Peut-être que nous ne voulons pas ou n'avons pas besoin de récupérer tous les champs. Nous pouvons obtenir une sélection de champs en incorporant la commande cut .
Ce script s'appelle "select.sh".
#!/bin/bash while IFS="," read -r id jobtitle branch state fais echo "ID d'enregistrement : $id" echo "Titre du poste : $jobtitle" echo " Branche : $branche" echo "Etat : $état" écho "" fait < <(cut -d "," -f1,4,6,7 sample.csv | tail -n +2)
Nous avons ajouté la commande cut dans la clause de substitution de processus. Nous utilisons l'option -d (délimiteur) pour dire à cut d'utiliser des virgules " , " comme délimiteur. L'option -f (champ) indique à cut que nous voulons les champs un, quatre, six et sept. Ces quatre champs sont lus dans quatre variables, qui sont imprimées dans le corps de la boucle while .
C'est ce que nous obtenons lorsque nous exécutons le script.
./select.sh
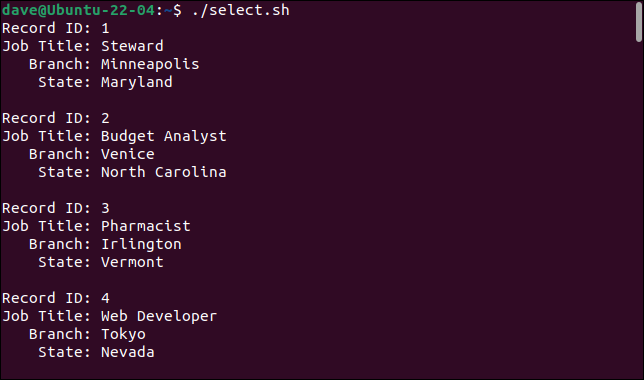
En ajoutant la commande cut , nous pouvons sélectionner les champs que nous voulons et ignorer ceux que nous ne voulons pas.
Jusqu'ici, tout va bien. Mais…
Si le CSV que vous traitez est simple, sans virgules ni guillemets dans les données de champ, ce que nous avons couvert répondra probablement à vos besoins d'analyse CSV. Pour montrer les problèmes que nous pouvons rencontrer, nous avons modifié un petit échantillon des données pour qu'elles ressemblent à ceci.
identifiant, prénom, nom de famille, fonction, adresse e-mail, succursale, état 1,Rosalyn,Brennan,"Intendante, Sénior",[email protected], Minneapolis, Maryland 2,Danny,Redden,"Analyste ""Budget""",[email protected],Venise, Caroline du Nord 3, Lexi, Roscoe, Pharmacien,, Irlington, Vermont
- L'enregistrement 1 contient une virgule dans le champ
job-title. Le champ doit donc être entouré de guillemets. - L'enregistrement 2 contient un mot entouré de deux ensembles de guillemets dans le champ "
jobs-title". - L'enregistrement trois ne contient aucune donnée dans le champ de l'
email-address.
Ces données ont été enregistrées sous "sample2.csv". Modifiez votre script "field.sh" pour appeler le "sample2.csv" et enregistrez-le sous "field2.sh".

# ! /bin/bash while IFS="," read -r id firstname lastname jobtitle email branch state fais echo "ID d'enregistrement : $id" echo "Prénom : $prénom" echo "Nom : $nom" echo "Titre du poste : $jobtitle" echo "Email ajouter : $email" echo " Branche : $branche" echo "Etat : $état" écho "" fait < <(tail -n +2 sample2.csv)
Lorsque nous exécutons ce script, nous pouvons voir des fissures apparaître dans nos simples analyseurs CSV.
./field2.sh

Le premier enregistrement divise le champ de l'intitulé du poste en deux champs, traitant la seconde partie comme l'adresse e-mail. Chaque champ après celui-ci est décalé d'une place vers la droite. Le dernier champ contient à la fois les valeurs de branch et state .
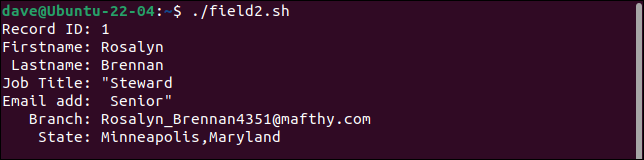
Le deuxième enregistrement conserve tous les guillemets. Il ne devrait y avoir qu'une seule paire de guillemets autour du mot "Budget".
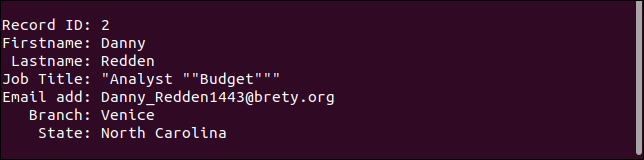
Le troisième enregistrement gère en fait le champ manquant comme il se doit. L'adresse e-mail est manquante, mais tout le reste est comme il se doit.

Contre-intuitivement, pour un format de données simple, il est très difficile d'écrire un analyseur CSV robuste pour le cas général. Des outils comme awk vous permettront de vous en approcher, mais il y a toujours des cas extrêmes et des exceptions qui se glissent.

Essayer d'écrire un analyseur CSV infaillible n'est probablement pas la meilleure voie à suivre. Une approche alternative, surtout si vous travaillez dans un délai quelconque, utilise deux stratégies différentes.
La première consiste à utiliser un outil spécialement conçu pour manipuler et extraire vos données. La seconde consiste à assainir vos données et à remplacer les scénarios problématiques tels que les virgules et les guillemets intégrés. Vos simples analyseurs Bash peuvent alors gérer le CSV compatible avec Bash.
La boîte à outils csvkit
La boîte à outils CSV csvkit est une collection d'utilitaires expressément créés pour aider à travailler avec des fichiers CSV. Vous devrez l'installer sur votre ordinateur.
Pour l'installer sur Ubuntu, utilisez cette commande :
sudo apt installer csvkit

Pour l'installer sur Fedora, vous devez taper :
sudo dnf installer python3-csvkit

Sur Manjaro la commande est :
sudo pacman -S csvkit

Si on lui passe le nom d'un fichier CSV, l'utilitaire csvlook affiche un tableau montrant le contenu de chaque champ. Le contenu du champ est affiché pour montrer ce que représente le contenu du champ, et non tel qu'il est stocké dans le fichier CSV.
Essayons csvlook avec notre fichier problématique "sample2.csv".
csvlook sample2.csv
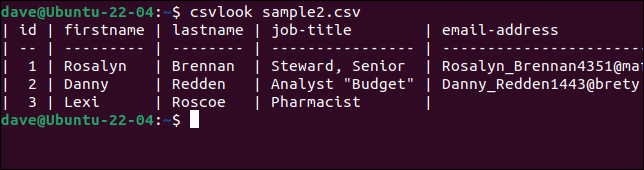
Tous les champs sont correctement affichés. Cela prouve que le problème n'est pas le CSV. Le problème est que nos scripts sont trop simplistes pour interpréter correctement le CSV.
Pour sélectionner des colonnes spécifiques, utilisez la commande csvcut . L'option -c (colonne) peut être utilisée avec des noms de champ ou des numéros de colonne, ou un mélange des deux.
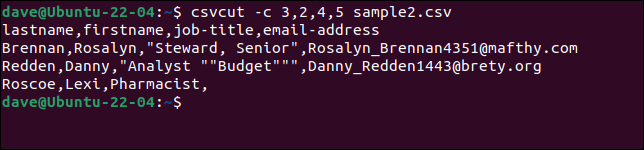
Supposons que nous ayons besoin d'extraire les noms et prénoms, les intitulés de poste et les adresses e-mail de chaque enregistrement, mais que nous souhaitions que l'ordre des noms soit "nom, prénom". Tout ce que nous avons à faire est de mettre les noms ou les numéros des champs dans l'ordre dans lequel nous les voulons.
Ces trois commandes sont toutes équivalentes.
csvcut -c nom, prénom, titre du poste, adresse e-mail sample2.csv
csvcut -c nom,prénom,4,5 sample2.csv
csvcut -c 3,2,4,5 sample2.csv
Nous pouvons ajouter la commande csvsort pour trier la sortie par un champ. Nous utilisons l'option -c (colonne) pour spécifier la colonne à trier et l'option -r (inverse) pour trier par ordre décroissant.
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r
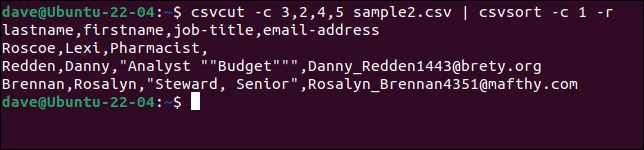
Pour rendre la sortie plus jolie, nous pouvons la faire passer par csvlook .
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r | csvlook
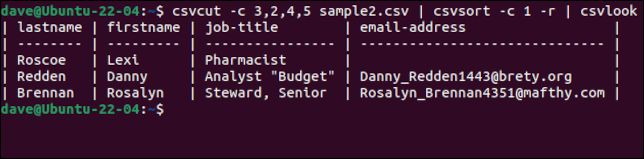
Une touche soignée est que, même si les enregistrements sont triés, la ligne d'en-tête avec les noms de champs est conservée comme première ligne. Une fois que nous sommes satisfaits d'avoir les données comme nous le voulons, nous pouvons supprimer le csvlook de la chaîne de commande et créer un nouveau fichier CSV en redirigeant la sortie dans un fichier.
Nous avons ajouté plus de données au "sample2.file", supprimé la commande csvsort et créé un nouveau fichier appelé "sample3.csv".
csvcut -c 3,2,4,5 exemple2.csv > exemple3.csv

Un moyen sûr de nettoyer les données CSV
Si vous ouvrez un fichier CSV dans LibreOffice Calc, chaque champ sera placé dans une cellule. Vous pouvez utiliser la fonction Rechercher et remplacer pour rechercher des virgules. Vous pouvez les remplacer par "rien" pour qu'ils disparaissent, ou par un caractère qui n'affectera pas l'analyse CSV, comme un point-virgule " ; " par exemple.
Vous ne verrez pas les guillemets autour des champs entre guillemets. Les seuls guillemets que vous verrez sont les guillemets intégrés à l' intérieur des données de champ. Ceux-ci sont affichés sous forme de guillemets simples. Les trouver et les remplacer par une seule apostrophe « ' » remplacera les guillemets doubles dans le fichier CSV.
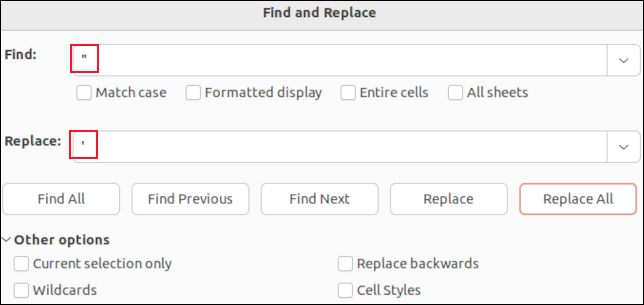
Faire la recherche et le remplacement dans une application comme LibreOffice Calc signifie que vous ne pouvez pas supprimer accidentellement les virgules de séparation de champ, ni supprimer les guillemets autour des champs entre guillemets. Vous ne modifierez que les valeurs de données des champs.
Nous avons changé toutes les virgules dans les champs avec des points-virgules et tous les guillemets intégrés avec des apostrophes et avons enregistré nos modifications.
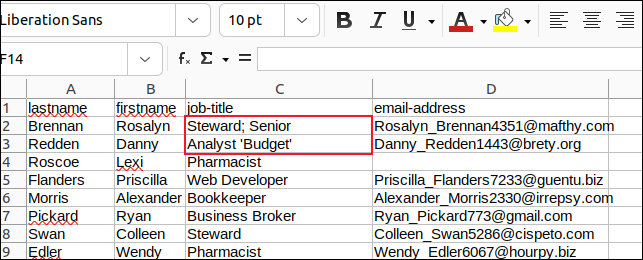
Nous avons ensuite créé un script appelé "field3.sh" pour analyser "sample3.csv".
# ! /bin/bash while IFS="," read -r lastname firstname jobtitle email fais echo "Nom : $nom" echo "Prénom : $prénom" echo "Titre du poste : $jobtitle" echo "Email ajouter : $email" écho "" fait < <(tail -n +2 sample3.csv)
Voyons ce que nous obtenons lorsque nous l'exécutons.
./field3.sh
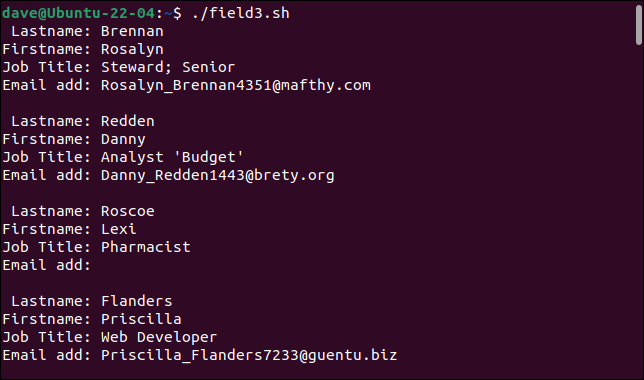
Notre analyseur simple peut maintenant gérer nos enregistrements auparavant problématiques.
Vous verrez beaucoup de CSV
CSV est sans doute la chose la plus proche d'une langue commune pour les données d'application. La plupart des applications qui gèrent une certaine forme de données prennent en charge l'importation et l'exportation de fichiers CSV. Savoir comment gérer le CSV de manière réaliste et pratique vous sera très utile.
CONNEXION: 9 exemples de scripts Bash pour démarrer sur Linux