
GPU de la série RTX 3000 de NVIDIA : voici les nouveautés
Publié: 2022-01-29
Le 1er septembre 2020, NVIDIA a dévoilé sa nouvelle gamme de GPU de jeu : la série RTX 3000, basée sur leur architecture Ampere. Nous discuterons des nouveautés, du logiciel alimenté par l'IA qui l'accompagne et de tous les détails qui rendent cette génération vraiment géniale.
Découvrez les GPU de la série RTX 3000

L'annonce principale de NVIDIA était ses nouveaux GPU brillants, tous construits sur un processus de fabrication personnalisé de 8 nm, et apportant tous des accélérations majeures dans les performances de rastérisation et de lancer de rayons.
Au bas de la gamme, il y a le RTX 3070, qui coûte 499 $. C'est un peu cher pour la carte la moins chère dévoilée par NVIDIA lors de l'annonce initiale, mais c'est un vol absolu une fois que vous apprenez qu'elle bat la RTX 2080 Ti existante, une carte haut de gamme qui se vendait régulièrement à plus de 1400 $. Cependant, après l'annonce de NVIDIA, le prix de vente des tiers a chuté, un grand nombre d'entre eux étant vendus en panique sur eBay pour moins de 600 $.
Il n'y a pas de benchmarks solides au moment de l'annonce, il n'est donc pas clair si la carte est vraiment objectivement "meilleure" qu'une 2080 Ti, ou si NVIDIA tord un peu le marketing. Les références en cours d'exécution étaient à 4K et avaient probablement RTX activé, ce qui peut faire paraître l'écart plus grand qu'il ne le sera dans les jeux purement pixellisés, car la série 3000 basée sur Ampere fonctionnera plus de deux fois mieux au lancer de rayons que Turing. Mais, le lancer de rayons étant désormais quelque chose qui ne nuit pas beaucoup aux performances et étant pris en charge dans la dernière génération de consoles, c'est un argument de vente majeur de le faire fonctionner aussi vite que le produit phare de la dernière génération pour près d'un tiers du prix.
Il est également difficile de savoir si le prix restera ainsi. Les conceptions tierces ajoutent régulièrement au moins 50 $ au prix, et avec la forte demande probable, il ne sera pas surprenant de le voir se vendre 600 $ en octobre 2020.
Juste au-dessus se trouve le RTX 3080 à 699 $, qui devrait être deux fois plus rapide que le RTX 2080, et arriver environ 25 à 30 % plus vite que le 3080.
Ensuite, en haut de gamme, le nouveau produit phare est le RTX 3090, qui est comiquement énorme. NVIDIA en est bien conscient et l'a qualifié de "BFGPU", ce qui, selon la société, signifie "Big Ferocious GPU".

NVIDIA n'a montré aucune mesure de performance directe, mais la société a montré qu'elle exécutait des jeux 8K à 60 FPS, ce qui est vraiment impressionnant. Certes, NVIDIA utilise presque certainement DLSS pour atteindre ce niveau, mais le jeu 8K est un jeu 8K.
Bien sûr, il y aura éventuellement une 3060 et d'autres variantes de cartes plus économiques, mais celles-ci arrivent généralement plus tard.
Pour vraiment refroidir les choses, NVIDIA avait besoin d'une conception de refroidisseur remaniée. Le 3080 est évalué à 320 watts, ce qui est assez élevé, donc NVIDIA a opté pour une conception à double ventilateur, mais au lieu des deux ventilateurs vwinf placés en bas, NVIDIA a placé un ventilateur à l'extrémité supérieure où la plaque arrière va habituellement. Le ventilateur dirige l'air vers le haut vers le refroidisseur du processeur et le haut du boîtier.

À en juger par la quantité de performances qui peuvent être affectées par un mauvais flux d'air dans un boîtier, cela est parfaitement logique. Cependant, le circuit imprimé est très exigu à cause de cela, ce qui affectera probablement les prix de vente des tiers.
DLSS : un avantage logiciel
Le lancer de rayons n'est pas le seul avantage de ces nouvelles cartes. Vraiment, c'est un peu un hack - les séries RTX 2000 et 3000 ne sont pas tellement meilleures pour faire du traçage de rayons réel, par rapport aux anciennes générations de cartes. Le traçage de rayons d'une scène complète dans un logiciel 3D comme Blender prend généralement quelques secondes, voire quelques minutes par image, il est donc hors de question de le forcer brutalement en moins de 10 millisecondes.
Bien sûr, il existe un matériel dédié pour exécuter les calculs de rayons, appelés les cœurs RT, mais en grande partie, NVIDIA a opté pour une approche différente. NVIDIA a amélioré les algorithmes de débruitage, qui permettent aux GPU de rendre une seule passe très bon marché qui a l'air terrible, et d'une manière ou d'une autre, grâce à la magie de l'IA, de transformer cela en quelque chose qu'un joueur veut regarder. Lorsqu'il est combiné avec des techniques traditionnelles basées sur la rastérisation, il offre une expérience agréable renforcée par des effets de lancer de rayons.

Cependant, pour faire cela rapidement, NVIDIA a ajouté des cœurs de traitement spécifiques à l'IA appelés cœurs Tensor. Ceux-ci traitent tous les calculs nécessaires pour exécuter des modèles d'apprentissage automatique et le font très rapidement. Ils changent totalement la donne pour l'IA dans l'espace des serveurs cloud, car l'IA est largement utilisée par de nombreuses entreprises.
Au-delà du débruitage, l'utilisation principale des cœurs Tensor pour les joueurs s'appelle DLSS, ou super échantillonnage d'apprentissage en profondeur. Il prend un cadre de faible qualité et le met à l'échelle jusqu'à une qualité entièrement native. Cela signifie essentiellement que vous pouvez jouer avec des fréquences d'images de niveau 1080p, tout en regardant une image 4K.

Cela aide également un peu les performances de lancer de rayons – les références de PCMag montrent un RTX 2080 Super Running Control de qualité ultra, avec tous les paramètres de lancer de rayons poussés au maximum. À 4K, il se débat avec seulement 19 FPS, mais avec DLSS activé, il obtient un bien meilleur 54 FPS. DLSS est une performance gratuite pour NVIDIA, rendue possible par les cœurs Tensor sur Turing et Ampere. Tout jeu qui le prend en charge et qui est limité par le GPU peut voir de sérieuses accélérations uniquement à partir du logiciel.
DLSS n'est pas nouveau et a été annoncé comme une fonctionnalité lors du lancement de la série RTX 2000 il y a deux ans. À l'époque, il était pris en charge par très peu de jeux, car il fallait que NVIDIA forme et ajuste un modèle d'apprentissage automatique pour chaque jeu individuel.
Cependant, à cette époque, NVIDIA l'a complètement réécrit, appelant la nouvelle version DLSS 2.0. Il s'agit d'une API à usage général, ce qui signifie que n'importe quel développeur peut l'implémenter, et elle est déjà reprise par la plupart des versions majeures. Plutôt que de travailler sur une image, il prend en compte les données vectorielles de mouvement de l'image précédente, de la même manière que TAA. Le résultat est beaucoup plus net que DLSS 1.0 et, dans certains cas, semble en fait meilleur et plus net que même la résolution native, il n'y a donc pas beaucoup de raisons de ne pas l'activer.
Il y a un hic : lorsque vous changez complètement de scène, comme dans les cinématiques, DLSS 2.0 doit restituer la toute première image avec une qualité de 50 % en attendant les données vectorielles de mouvement. Cela peut entraîner une petite baisse de qualité pendant quelques millisecondes. Mais, 99% de tout ce que vous regardez sera rendu correctement, et la plupart des gens ne le remarquent pas dans la pratique.
CONNEXION: Qu'est-ce que NVIDIA DLSS et comment accélérera-t-il le traçage de rayons?
Architecture Ampère : conçue pour l'IA
Ampère est rapide. Sérieusement rapide, en particulier pour les calculs d'IA. Le noyau RT est 1,7 fois plus rapide que Turing et le nouveau noyau Tensor est 2,7 fois plus rapide que Turing. La combinaison des deux est un véritable saut générationnel dans les performances du raytracing.

Plus tôt en mai, NVIDIA a lancé le GPU Ampere A100, un GPU de centre de données conçu pour exécuter l'IA. Avec lui, ils ont détaillé beaucoup de ce qui rend Ampère tellement plus rapide. Pour les charges de travail de centre de données et de calcul haute performance, Ampère est en général environ 1,7 fois plus rapide que Turing. Pour l'entraînement à l'IA, c'est jusqu'à 6 fois plus rapide.
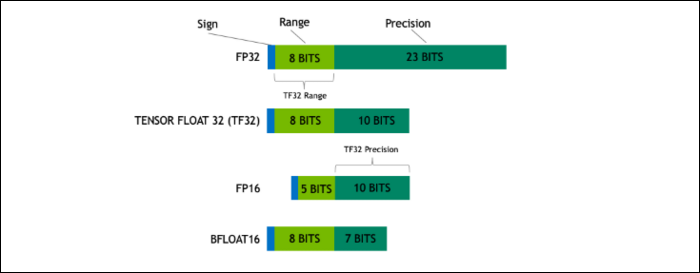
Avec Ampere, NVIDIA utilise un nouveau format numérique conçu pour remplacer le standard de l'industrie "Floating-Point 32", ou FP32, dans certaines charges de travail. Sous le capot, chaque nombre traité par votre ordinateur occupe un nombre prédéfini de bits en mémoire, que ce soit 8 bits, 16 bits, 32, 64 ou même plus. Les nombres plus grands sont plus difficiles à traiter, donc si vous pouvez utiliser une taille plus petite, vous aurez moins à croquer.
FP32 stocke un nombre décimal 32 bits et utilise 8 bits pour la plage du nombre (quelle qu'elle soit grande ou petite) et 23 bits pour la précision. L'affirmation de NVIDIA est que ces 23 bits de précision ne sont pas entièrement nécessaires pour de nombreuses charges de travail d'IA, et vous pouvez obtenir des résultats similaires et de bien meilleures performances avec seulement 10 d'entre eux. Réduire la taille à seulement 19 bits, au lieu de 32, fait une grande différence dans de nombreux calculs.
Ce nouveau format s'appelle Tensor Float 32 et les cœurs Tensor de l'A100 sont optimisés pour gérer le format de taille étrange. C'est, en plus de la réduction des matrices et de l'augmentation du nombre de cœurs, comment ils obtiennent l'accélération massive de 6x dans la formation à l'IA.
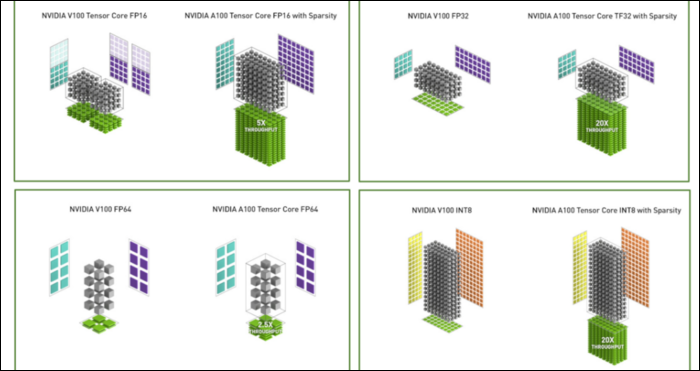
En plus du nouveau format de nombre, Ampere constate des accélérations majeures des performances dans des calculs spécifiques, comme FP32 et FP64. Ceux-ci ne se traduisent pas directement par plus de FPS pour le profane, mais ils font partie de ce qui le rend presque trois fois plus rapide dans l'ensemble des opérations Tensor.
Ensuite, pour accélérer encore plus les calculs, ils ont introduit le concept de parcimonie structurée à grain fin, qui est un mot très fantaisiste pour un concept assez simple. Les réseaux de neurones fonctionnent avec de grandes listes de nombres, appelées poids, qui affectent la sortie finale. Plus il y a de chiffres à croquer, plus ce sera lent.
Cependant, tous ces chiffres ne sont pas réellement utiles. Certains d'entre eux sont littéralement nuls et peuvent être rejetés, ce qui entraîne des accélérations massives lorsque vous pouvez calculer plus de chiffres en même temps. La parcimonie comprime essentiellement les nombres, ce qui nécessite moins d'efforts pour effectuer des calculs. Le nouveau "Sparse Tensor Core" est conçu pour fonctionner sur des données compressées.
Malgré les changements, NVIDIA affirme que cela ne devrait pas du tout affecter sensiblement la précision des modèles entraînés.
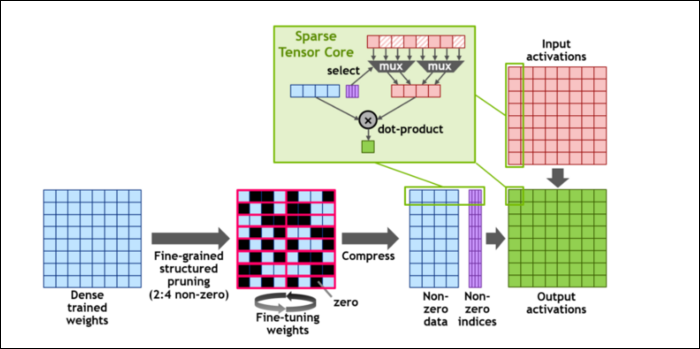
Pour les calculs Sparse INT8, l'un des formats les plus petits, les performances maximales d'un seul GPU A100 sont supérieures à 1,25 PetaFLOP, un nombre incroyablement élevé. Bien sûr, ce n'est que lorsque vous calculez un type spécifique de nombre, mais c'est néanmoins impressionnant.