
Comment utiliser la commande stat sous Linux
Publié: 2022-01-29
La commande Linux stat vous montre beaucoup plus de détails que ls . Jetez un coup d'œil derrière le rideau avec cet utilitaire informatif et configurable. Nous allons vous montrer comment l'utiliser.
stat vous emmène dans les coulisses
La commande ls est excellente dans ce qu'elle fait - et elle en fait beaucoup - mais avec Linux, il semble qu'il y ait toujours un moyen d'aller plus loin et de voir ce qui se cache sous la surface. Et souvent, il ne s'agit pas seulement de soulever le bord du tapis. Vous pouvez déchirer les lames de plancher puis creuser un trou. Vous pouvez peler Linux comme un oignon.

ls vous montrera de nombreuses informations sur un fichier, telles que les autorisations qui y sont définies, sa taille et s'il s'agit d'un fichier ou d'un lien symbolique. Pour afficher ces informations, ls les lit à partir d'une structure de système de fichiers appelée inode.
Chaque fichier et répertoire a un inode. L'inode contient des métadonnées sur le fichier, telles que les blocs de système de fichiers qu'il occupe et les horodatages associés au fichier. L'inode est comme une carte de bibliothèque pour le fichier. Mais ls ne vous montrera qu'une partie des informations. Pour tout voir, nous devons utiliser la commande stat .
Comme ls , la commande stat a beaucoup d'options. Cela en fait un excellent candidat pour l'utilisation d'alias. Une fois que vous avez découvert un ensemble particulier d'options qui permettent à stat de vous donner la sortie souhaitée, encapsulez-la dans un alias ou une fonction shell. Cela le rend beaucoup plus pratique à utiliser et vous n'avez pas à vous souvenir d'un ensemble mystérieux d'options de ligne de commande.
CONNEXION: Comment utiliser la commande ls pour répertorier les fichiers et les répertoires sous Linux
Une comparaison rapide
Utilisons ls pour nous donner une longue liste (option -l ) avec des tailles de fichiers lisibles par l'homme (option -h ) :
ls -lh ana.h

De gauche à droite, les informations fournies par ls sont :
- Le tout premier caractère est un trait d'union "-" et cela nous indique que le fichier est un fichier normal et non une socket, un lien symbolique ou un autre type d'objet.
- Le propriétaire, le groupe et les autres autorisations sont répertoriés au format octal.
- Le nombre de liens physiques pointant vers ce fichier. Dans ce cas, et dans la plupart des cas, ce sera un.
- Le propriétaire du fichier est dave.
- Le propriétaire du groupe est dave.
- La taille du fichier est de 802 octets.
- Le fichier a été modifié pour la dernière fois le vendredi 13 décembre 2015.
- Le nom du fichier est
ana.c.
Jetons un coup d'oeil avec stat :
stat ana.h
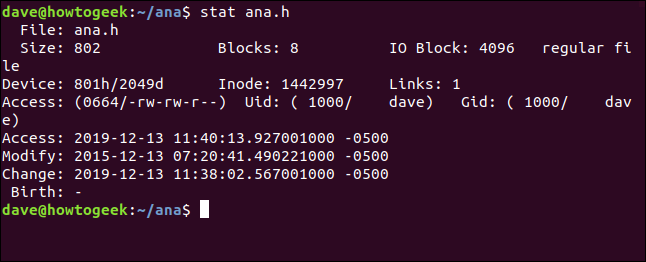
Les informations que nous obtenons de stat sont :
- Fichier : Le nom du fichier. Habituellement, c'est le même que le nom que nous avons passé à
statsur la ligne de commande, mais cela peut être différent si nous regardons un lien symbolique. - Taille : La taille du fichier en octets.
- Blocs : Le nombre de blocs de système de fichiers dont le fichier a besoin pour être stocké sur le disque dur.
- IO Block : La taille d'un bloc de système de fichiers.
- Type de fichier : type d'objet décrit par les métadonnées. Les types les plus courants sont les fichiers et les répertoires, mais ils peuvent également être des liens, des sockets ou des canaux nommés.
- Périphérique : Le numéro du périphérique en hexadécimal et décimal. Il s'agit de l'ID du disque dur sur lequel le fichier est stocké.
- Inode : Le numéro d'inode. C'est-à-dire le numéro d'identification de cet inode. Ensemble, le numéro d'inode et le numéro de périphérique identifient de manière unique un fichier.
- Liens : Ce nombre indique combien de liens physiques pointent vers ce fichier. Chaque lien dur a son propre inode. Donc, une autre façon de penser à ce chiffre est de savoir combien d'inodes pointent vers ce fichier. Chaque fois qu'un lien physique est créé ou supprimé, ce nombre sera ajusté à la hausse ou à la baisse. Lorsqu'il atteint zéro, le fichier lui-même a été supprimé et l'inode est supprimé. Si vous utilisez
statsur un répertoire, ce nombre représente le nombre de fichiers dans le répertoire, y compris le "." pour le répertoire courant et l'entrée ".." pour le répertoire parent. - Accès : Les permissions des fichiers sont affichées dans leurs formats octal et traditionnel
rwx(formats lecture, écriture, exécution). - Uid : ID utilisateur et nom de compte du propriétaire.
- Gid : ID de groupe et nom de compte du propriétaire.
- Accès : L'horodatage d'accès. Pas aussi simple que cela puisse paraître. Les distributions Linux modernes utilisent un schéma appelé
relatime, qui tente d'optimiser les écritures sur le disque dur nécessaires pour mettre à jour le temps d'accès. En termes simples, l'heure d'accès est mise à jour si elle est antérieure à l'heure modifiée. - Modifier : L'horodatage de la modification. Il s'agit de l'heure à laquelle le contenu du fichier a été modifié pour la dernière fois. (Par chance, le contenu de ce fichier a été modifié pour la dernière fois il y a quatre ans jour pour jour.)
- Changement : L'horodatage du changement. Il s'agit de l'heure à laquelle les attributs ou le contenu du fichier ont été modifiés pour la dernière fois. Si vous modifiez un fichier en définissant de nouvelles autorisations de fichier, l'horodatage de modification sera mis à jour (car les attributs du fichier ont changé), mais l'horodatage modifié ne sera pas mis à jour (car le contenu du fichier n'a pas été modifié).
- Naissance : Réservé pour afficher la date de création originale du fichier, mais cela n'est pas implémenté sous Linux.
Comprendre les horodatages
Les horodatages sont sensibles au fuseau horaire. Le -0500 à la fin de chaque ligne indique que ce fichier a été créé sur un ordinateur dans un fuseau horaire UTC (Coordinated Universal Time) qui est en avance de cinq heures sur le fuseau horaire de l'ordinateur actuel. Cet ordinateur a donc cinq heures de retard sur l'ordinateur qui a créé ce fichier. En fait, le fichier a été créé sur un ordinateur de fuseau horaire britannique, et nous le regardons ici sur un ordinateur dans le fuseau horaire US Eastern Standard.
Les horodatages de modification et de changement peuvent prêter à confusion car, pour les non-initiés, leurs noms sonnent comme s'ils signifiaient la même chose.
Utilisons chmod pour modifier les autorisations de fichier sur un fichier appelé ana.c . Nous allons le rendre inscriptible par tout le monde. Cela n'affectera pas le contenu du fichier, mais cela affectera les attributs du fichier.
chmod +w ana.c
Et puis nous utiliserons stat pour regarder les horodatages :
stat ana.c
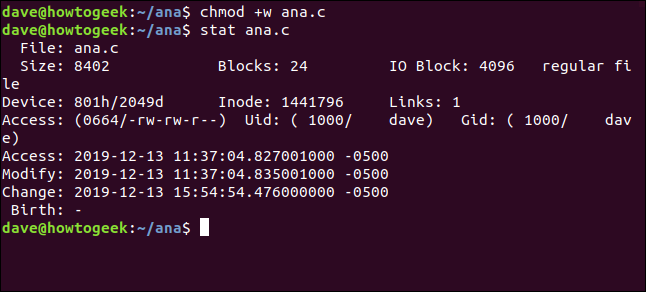
L'horodatage de modification a été mis à jour, mais pas celui modifié.
L'horodatage modifié ne sera mis à jour que si le contenu du fichier est modifié. L'horodatage de modification est mis à jour pour les modifications de contenu et les modifications d'attribut.
Utilisation de Stat avec plusieurs fichiers
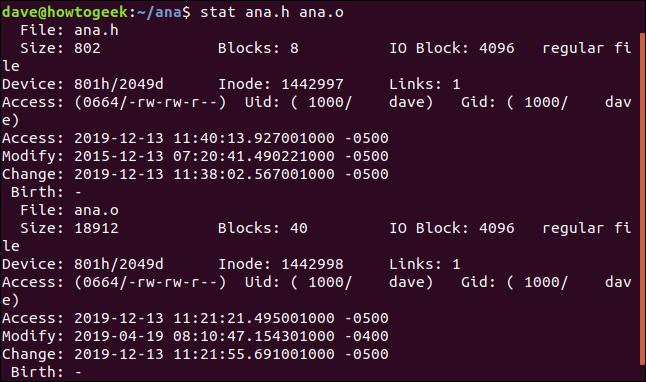
Pour avoir un rapport stat sur plusieurs fichiers à la fois, passez les noms de fichiers à stat sur la ligne de commande :
stat ana.h ana.o
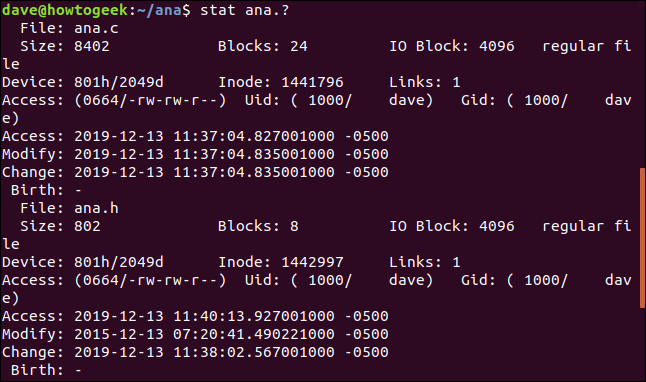
Pour utiliser stat sur un ensemble de fichiers, utilisez la correspondance de modèle. Le point d'interrogation "?" représente n'importe quel caractère unique et l'astérisque "*" représente n'importe quelle chaîne de caractères. Nous pouvons dire à stat de signaler n'importe quel fichier appelé "ana" avec une extension à une seule lettre, avec cette commande :
stat ana. ?
Utilisation de stat pour générer des rapports sur les systèmes de fichiers
stat peut signaler l'état des systèmes de fichiers, ainsi que l'état des fichiers. L'option -f (système de fichiers) indique à stat de signaler le système de fichiers sur lequel réside le fichier. Notez que nous pouvons également passer un répertoire tel que "/" à stat au lieu d'un nom de fichier.
stat -f ana.c
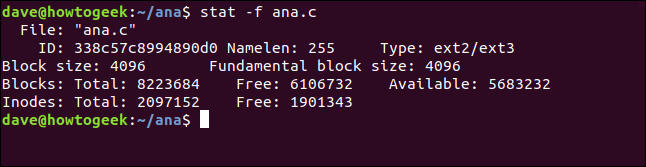
Les stat nous donnent les informations suivantes :
- Fichier : Le nom du fichier.
- ID : L'ID du système de fichiers en notation hexadécimale.
- Namelen : La longueur maximale autorisée pour les noms de fichiers.
- Type : Le type de système de fichiers.
- Taille de bloc : La quantité de données pour demander des requêtes de lecture pour des taux de transfert de données optimaux.
- Taille de bloc fondamentale : La taille de chaque bloc du système de fichiers.
Blocs :
- Total : Le nombre total de tous les blocs dans le système de fichiers.
- Free : Le nombre de blocs libres dans le système de fichiers.
- Disponible : Le nombre de blocs gratuits disponibles pour les utilisateurs réguliers (non root).
Inodes :
- Total : Le nombre total d'inodes dans le système de fichiers.
- Free : Le nombre d'inodes libres dans le système de fichiers.
Déréférencement des liens symboliques
Si vous utilisez stat sur un fichier qui est en fait un lien symbolique, il rapportera sur le lien. Si vous vouliez que stat signale le fichier vers lequel pointe le lien, utilisez l'option -L (déréférencement). Le fichier code.c est un lien symbolique vers ana.c . Regardons cela sans l'option -L :

code statistique.c
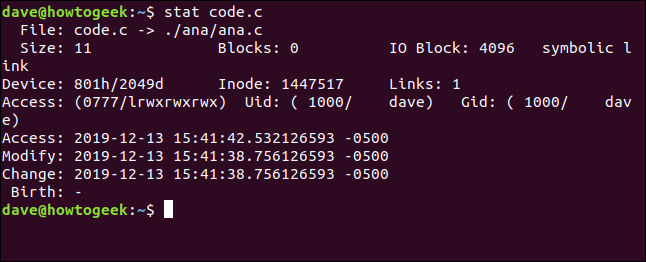
Le nom de fichier montre code.c pointant vers ( -> ) ana.c . La taille du fichier n'est que de 11 octets. Il n'y a aucun bloc consacré au stockage de ce lien. Le type de fichier est répertorié sous la forme d'un lien symbolique.
De toute évidence, nous ne regardons pas le fichier réel ici. Recommençons et ajoutons l'option -L :
stat -L code.c
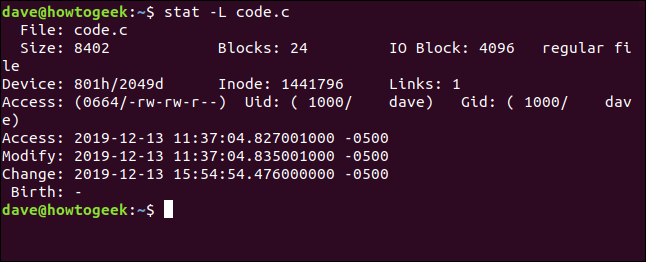
Ceci affiche maintenant les détails du fichier pour le fichier pointé par le lien symbolique. Mais notez que le nom de fichier est toujours donné sous code.c . Il s'agit du nom du lien, pas du fichier cible. Cela se produit parce que c'est le nom que nous avons passé à stat sur la ligne de commande.
Le rapport laconique
L'option -t (laconique) oblige stat à fournir un résumé condensé :
stat -t ana.c

Aucun indice n'est donné. Pour donner un sens à cela - jusqu'à ce que vous ayez mémorisé la séquence de champs - vous devez faire référence à cette sortie avec une sortie stat complète.
Formats de sortie personnalisés
Une meilleure façon d'obtenir un ensemble de données différent à partir de stat consiste à utiliser un format personnalisé. Il existe une longue liste de jetons appelés séquences de format. Chacun d'eux représente un élément de données. Sélectionnez ceux que vous souhaitez inclure dans la sortie et créez une chaîne de format. Lorsque nous appelons stat et lui transmettons la chaîne de format, la sortie n'inclura que les éléments de données que nous avons demandés.
Il existe différents ensembles de séquences de format pour les fichiers et les systèmes de fichiers. La liste des fichiers est :
- %a : Les droits d'accès en octal.
- %A : Les droits d'accès sous une forme lisible par l'homme (
rwx). - %b : Le nombre de blocs alloués.
- %B : La taille en octets de chaque bloc.
- %d : Le numéro de périphérique en décimal.
- %D : Le numéro de périphérique en hexadécimal.
- %f : Le mode brut en hexadécimal.
- %F Le type de fichier.
- %g : ID de groupe du propriétaire.
- %G : Le nom du groupe du propriétaire.
- %h : Le nombre de liens physiques.
- %i : Le numéro d'inode.
- %m : Le point de montage.
- %n : Le nom du fichier.
- %N : Le nom du fichier entre guillemets, avec le nom du fichier déréférencé s'il s'agit d'un lien symbolique.
- %o : l'indice de taille de transfert d'E/S optimal.
- %s : La taille totale, en octets.
- %t : le type de périphérique principal en hexadécimal, pour les fichiers spéciaux de périphérique de caractères/blocs.
- %T : Le type de périphérique mineur en hexadécimal, pour les fichiers spéciaux de périphérique caractère/bloc.
- %u : L'ID utilisateur du propriétaire.
- %U : Le nom d'utilisateur du propriétaire.
- %w : L'heure de naissance du fichier, lisible par l'homme, ou un trait d'union "-" si inconnu.
- %W : L'heure de création du fichier, en secondes depuis l'Epoch ; 0 si inconnu.
- %x : L'heure du dernier accès, lisible par l'homme.
- %X : L'heure du dernier accès, en secondes depuis l'Epoch.
- %y : L'heure de la dernière modification des données, lisible par l'homme.
- %Y : L'heure de la dernière modification des données, en secondes depuis l'Epoch.
- %z : L'heure du dernier changement d'état, lisible par l'homme.
- %Z : L'heure du dernier changement d'état, en secondes depuis l'époque.
L'"époque" est l'époque Unix, qui a eu lieu le 1970-01-01 00:00:00 +0000 (UTC).
Pour les systèmes de fichiers, les séquences de format sont :
- %a : Le nombre de blocs libres disponibles pour les utilisateurs réguliers (non root).
- %b : Le nombre total de blocs de données dans le système de fichiers.
- %c : Le nombre total d'inodes dans le système de fichiers.
- %d : Le nombre d'inodes libres dans le système de fichiers.
- %f : Le nombre de blocs libres dans le système de fichiers.
- %i : ID du système de fichiers en hexadécimal.
- %l : La longueur maximale des noms de fichiers.
- %n : Le nom du fichier.
- %s : La taille de bloc (la taille d'écriture optimale).
- %S : La taille des blocs du système de fichiers (pour le nombre de blocs).
- %t : Le type de système de fichiers en hexadécimal.
- %T : type de système de fichiers sous une forme lisible par l'homme.
Il existe deux options qui acceptent les chaînes de séquences de format. Ce sont --format et --printf . La différence entre eux est --printf interprète les séquences d'échappement de style C telles que newline \n et tab \t , et il n'ajoute pas automatiquement un caractère de nouvelle ligne à sa sortie.
Créons une chaîne de format et transmettons-la à stat . Les séquences de format qui allaient être utilisées sont %n pour le nom de fichier, %s pour la taille du fichier et %F pour le type de fichier. Nous allons ajouter la séquence d'échappement \n à la fin de la chaîne pour nous assurer que chaque fichier est géré sur une nouvelle ligne. Notre chaîne de format ressemble à ceci :
"Le fichier %n fait %s octets et est un %F\n"
Nous allons passer ceci à stat en utilisant l'option --printf . Nous allons demander à stat de faire un rapport sur un fichier appelé code.c et un ensemble de fichiers qui correspondent à ana.? . C'est la commande complète. Notez le signe égal " = " entre --printf et la chaîne de format :
stat --printf="Le fichier %n fait %s octets et est un code %F\n".c ana/ana. ?
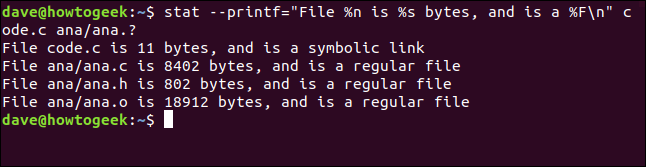
Le rapport de chaque dossier est répertorié sur une nouvelle ligne, ce que nous avons demandé. Le nom de fichier, la taille de fichier et le type de fichier nous sont fournis.
Les formats personnalisés vous donnent accès à encore plus d'éléments de données que ceux inclus dans la sortie stat standard.
Contrôle du grain fin
Comme vous pouvez le constater, il existe une marge énorme pour extraire les éléments de données particuliers qui vous intéressent. Vous pouvez probablement aussi voir pourquoi nous avons recommandé d'utiliser des alias pour les incantations plus longues et plus complexes.
| Commandes Linux | ||
| Des dossiers | tar · pv · chat · tac · chmod · grep · diff · sed · ar · man · pushd · popd · fsck · testdisk · seq · fd · pandoc · cd · $PATH · awk · join · jq · plier · uniq · journalctl · queue · stat · ls · fstab · echo · moins · chgrp · chown · rev · regarder · chaînes · type · renommer · zip · décompresser · monter · umount · installer · fdisk · mkfs · rm · rmdir · rsync · df · gpg · vi · nano · mkdir · du · ln · patch · convertir · rclone · déchiqueter · srm | |
| Processus | alias · écran · top · sympa · renice · progrès · strace · systemd · tmux · chsh · historique · at · batch · gratuit · lequel · dmesg · chfn · usermod · ps · chroot · xargs · tty · pinky · lsof · vmstat · timeout · mur · oui · kill · sleep · sudo · su · time · groupadd · usermod · groupes · lshw · shutdown · reboot · halt · poweroff · passwd · lscpu · crontab · date · bg · fg | |
| La mise en réseau | netstat · ping · traceroute · ip · ss · whois · fail2ban · bmon · creuser · doigt · nmap · ftp · curl · wget · qui · whoami · w · iptables · ssh-keygen · ufw |
CONNEXION: Meilleurs ordinateurs portables Linux pour les développeurs et les passionnés