
Comment effectuer une OCR à partir de la ligne de commande Linux à l'aide de Tesseract
Publié: 2022-01-29
Vous pouvez extraire du texte à partir d'images sur la ligne de commande Linux à l'aide du moteur Tesseract OCR. Il est rapide, précis et fonctionne dans environ 100 langues. Voici comment l'utiliser.
Reconnaissance optique de caractères
La reconnaissance optique de caractères (OCR) est la capacité de regarder et de trouver des mots dans une image, puis de les extraire sous forme de texte modifiable. Cette tâche simple pour les humains est très difficile à réaliser pour les ordinateurs. Les premiers efforts étaient maladroits, c'est le moins qu'on puisse dire. Les ordinateurs étaient souvent confus si la police ou la taille n'étaient pas au goût du logiciel OCR.
Néanmoins, les pionniers dans ce domaine étaient toujours tenus en haute estime. Si vous avez perdu la copie électronique d'un document, mais que vous aviez toujours une version imprimée, l'OCR pourrait recréer une version électronique modifiable. Même si les résultats n'étaient pas précis à 100 %, c'était quand même un gain de temps considérable.
Avec un peu de rangement manuel, vous retrouverez votre document. Les gens pardonnaient les erreurs commises parce qu'ils comprenaient la complexité de la tâche à laquelle était confronté un package OCR. De plus, c'était mieux que de retaper tout le document.
Les choses se sont nettement améliorées depuis. L'application Tesseract OCR, écrite par Hewlett Packard, a débuté dans les années 1980 en tant qu'application commerciale. Il était open source en 2005 et est maintenant pris en charge par Google. Il a des capacités multilingues, est considéré comme l'un des systèmes OCR les plus précis disponibles et vous pouvez l'utiliser gratuitement.
Installation de Tesseract OCR
Pour installer Tesseract OCR sur Ubuntu, utilisez cette commande :
sudo apt-get install tesseract-ocr

Sur Fedora, la commande est :
sudo dnf installer tesseract

Sur Manjaro, il faut taper :
sudo pacman -Syu tesseract

Utilisation de Tesseract OCR
Nous allons poser un ensemble de défis à Tesseract OCR. Notre première image contenant du texte est un extrait du considérant 63 du Règlement général sur la protection des données. Voyons si OCR peut lire ceci (et rester éveillé).

C'est une image délicate car chaque phrase commence par un nombre en exposant faible, ce qui est typique dans les documents législatifs.
Nous devons donner à la commande tesseract quelques informations, notamment :
- Le nom du fichier image que nous voulons qu'il traite.
- Le nom du fichier texte qu'il créera pour contenir le texte extrait. Nous n'avons pas à fournir l'extension de fichier (ce sera toujours .txt). Si un fichier existe déjà avec le même nom, il sera écrasé.
- Nous pouvons utiliser l'option
--dpipour indiquer àtesseractquelle est la résolution en points par pouce (dpi) de l'image. Si nous ne fournissons pas de valeur dpi,tesseractessaiera de le comprendre.
Notre fichier image s'appelle « récital-63.png » et sa résolution est de 150 dpi. Nous allons créer un fichier texte à partir de celui-ci appelé « récital.txt ».
Notre commande ressemble à ceci :
tesseract récital-63.png récital --dpi 150

Les résultats sont très bons. Le seul problème, ce sont les exposants - ils étaient trop faibles pour être lus correctement. Une image de bonne qualité est essentielle pour obtenir de bons résultats.

tesseract a interprété les nombres en exposant comme des guillemets (") et des symboles de degré (°), mais le texte réel a été parfaitement extrait (le côté droit de l'image a dû être coupé pour tenir ici).
Le dernier caractère est un octet avec la valeur hexadécimale 0x0C, qui est un retour chariot.
Ci-dessous, une autre image avec du texte de différentes tailles, en gras et en italique.

Le nom de ce fichier est "bold-italic.png". Nous voulons créer un fichier texte appelé "bold.txt", donc notre commande est :
tesseract gras-italique.png gras --dpi 150

Celui-ci n'a posé aucun problème, et le texte a été parfaitement extrait.

Utiliser différentes langues
Tesseract OCR prend en charge environ 100 langues. Pour utiliser une langue, vous devez d'abord l'installer. Lorsque vous trouvez la langue que vous souhaitez utiliser dans la liste, notez son abréviation. Nous allons installer le support pour le gallois. Son abréviation est "cym", qui est l'abréviation de "Cymru", qui signifie gallois.
Le package d'installation s'appelle "tesseract-ocr-" avec l'abréviation de la langue étiquetée à la fin. Pour installer le fichier de langue galloise dans Ubuntu, nous utiliserons :
sudo apt-get install tesseract-ocr-cym


L'image avec le texte est ci-dessous. C'est le premier couplet de l'hymne national gallois.

Voyons si Tesseract OCR est à la hauteur du défi. Nous utiliserons l'option -l (langue) pour indiquer à tesseract la langue dans laquelle nous voulons travailler :
tesseract poule-wlad-fy-nhadau.png hymne -l cym --dpi 150

tesseract s'en sort parfaitement, comme le montre le texte extrait ci-dessous. Da iawn , Tesseract OCR.

Si votre document contient deux langues ou plus (comme un dictionnaire gallois-anglais, par exemple), vous pouvez utiliser un signe plus ( + ) pour indiquer à tesseract d'ajouter une autre langue, comme ceci :
tesseract image.png fichier texte -l eng+cym+fra
Utilisation de Tesseract OCR avec des PDF
La commande tesseract est conçue pour fonctionner avec des fichiers image, mais elle est incapable de lire les PDF. Cependant, si vous avez besoin d'extraire du texte d'un PDF, vous pouvez d'abord utiliser un autre utilitaire pour générer un ensemble d'images. Une seule image représentera une seule page du PDF.
L'utilitaire pdftppm dont vous avez besoin doit déjà être installé sur votre ordinateur Linux. Le PDF que nous utiliserons pour notre exemple est une copie de l'article fondateur d'Alan Turing sur l'intelligence artificielle, "Computing Machinery and Intelligence".

Nous utilisons l'option -png pour spécifier que nous voulons créer des fichiers PNG. Le nom de fichier de notre PDF est « turing.pdf ». Nous appellerons nos fichiers image « turing-01.png », « turing-02.png », etc. :
pdftoppm -png turing.pdf turing

Pour exécuter tesseract sur chaque fichier image à l'aide d'une seule commande, nous devons utiliser une boucle for. Pour chacun de nos fichiers « turing- nn .png », nous exécutons tesseract et créons un fichier texte appelé « text- » plus « turing- nn » dans le nom du fichier image :
pour moi dans turing-??.png; faire tesseract "$i" "texte-$i" -l eng ; Fini;

Pour combiner tous les fichiers texte en un seul, nous pouvons utiliser cat :
cat text-turing* > complete.txt

Alors, comment ça s'est passé ? Très bien, comme vous pouvez le voir ci-dessous. La première page semble assez difficile, cependant. Il a différents styles et tailles de texte, ainsi que des décorations. Il y a aussi un « filigrane » vertical sur le bord droit de la page.
Cependant, la sortie est proche de l'original. Évidemment, la mise en forme a été perdue, mais le texte est correct.
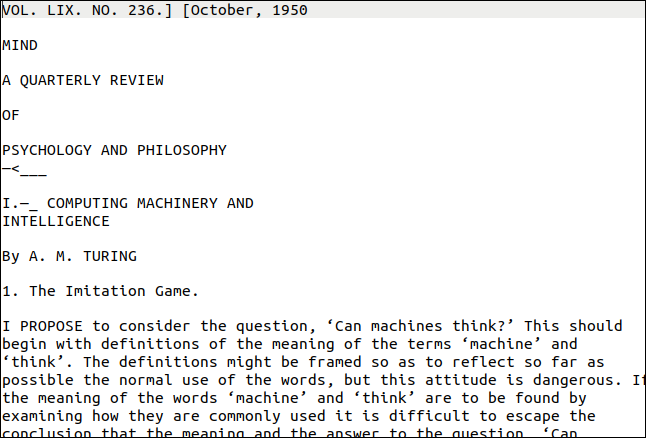
Le filigrane vertical a été retranscrit comme une ligne de charabia en bas de la page. Le texte était trop petit pour être lu avec précision par tesseract , mais il serait assez facile de le trouver et de le supprimer. Le pire résultat aurait été des caractères parasites à la fin de chaque ligne.
Curieusement, les lettres simples au début de la liste des questions et réponses à la page deux ont été ignorées. La section du PDF est illustrée ci-dessous.

Comme vous pouvez le voir ci-dessous, les questions demeurent, mais les « Q » et « A » au début de chaque ligne ont été perdus.

Les diagrammes ne seront pas non plus transcrits correctement. Regardons ce qui se passe lorsque nous essayons d'extraire celui présenté ci-dessous à partir du PDF de Turing.

Comme vous pouvez le voir dans notre résultat ci-dessous, les caractères ont été lus, mais le format du diagramme a été perdu.

Encore une fois, tesseract a eu du mal avec la petite taille des indices, et ils ont été rendus de manière incorrecte.
En toute honnêteté, cependant, c'était toujours un bon résultat. Nous n'avons pas été en mesure d'extraire un texte simple, mais cet exemple a été délibérément choisi car il présentait un défi.
Une bonne solution quand vous en avez besoin
L'OCR n'est pas quelque chose que vous devrez utiliser quotidiennement. Cependant, lorsque le besoin s'en fait sentir, il est bon de savoir que vous disposez de l'un des meilleurs moteurs OCR.