
¿Qué es el intercambio en Linux? (y cómo cambiarlo)
Publicado: 2022-01-29
El valor de intercambio de Linux no tiene nada que ver con la cantidad de RAM que se usa antes de que comience el intercambio. Ese es un error ampliamente informado y ampliamente creído. Te explicamos qué es realmente.
Rompiendo mitos sobre el intercambio
El intercambio es una técnica en la que los datos de la memoria de acceso aleatorio (RAM) se escriben en una ubicación especial del disco duro, ya sea una partición de intercambio o un archivo de intercambio, para liberar RAM.
Linux tiene una configuración llamada valor de swappiness. Hay mucha confusión sobre lo que controla esta configuración. La descripción incorrecta más común de swappiness es que establece un umbral para el uso de RAM, y cuando la cantidad de RAM utilizada alcanza ese umbral, comienza el intercambio.
Este es un concepto erróneo que se ha repetido con tanta frecuencia que ahora es sabiduría recibida. Si (casi) todo el mundo te dice que así es exactamente como funciona el swappiness, ¿por qué deberías creernos cuando te decimos que no es así?
Simple. Vamos a demostrarlo.
Su RAM está dividida en zonas
Linux no piensa en su RAM como un gran grupo homogéneo de memoria. Considera que se divide en una serie de diferentes regiones llamadas zonas. Las zonas que están presentes en su computadora dependen de si es de 32 bits o de 64 bits. Aquí hay una descripción simplificada de las posibles zonas en una computadora con arquitectura x86.
- Acceso directo a la memoria (DMA) : estos son los 16 MB bajos de memoria. La zona recibe su nombre porque, hace mucho tiempo, había computadoras que solo podían acceder directamente a la memoria en esta área de la memoria física.
- Direct Memory Access 32 : a pesar de su nombre, Direct Memory Access 32 (DMA32) es una zona que solo se encuentra en Linux de 64 bits. Son los bajos 4 GB de memoria. Linux que se ejecuta en computadoras de 32 bits solo puede hacer DMA a esta cantidad de RAM (a menos que estén usando el kernel de extensión de dirección física (PAE)), que es como la zona obtuvo su nombre. Aunque, en equipos de 32 bits, se llama HighMem.
- Normal : en computadoras de 64 bits, la memoria normal es toda la RAM por encima de 4 GB (aproximadamente). En máquinas de 32 bits, es RAM entre 16 MB y 896 MB.
- HighMem : esto solo existe en computadoras Linux de 32 bits. Es toda la RAM superior a 896 MB, incluida la RAM superior a 4 GB en máquinas suficientemente grandes.
El valor de TAMAÑO DE PAGINA
La memoria RAM se asigna en páginas, que tienen un tamaño fijo. Ese tamaño lo determina el kernel en el momento del arranque al detectar la arquitectura de la computadora. Normalmente, el tamaño de página en una computadora con Linux es de 4 Kbytes.
Puede ver el tamaño de su página usando el comando getconf :
getconf TAMAÑO DE PAGINA

Las zonas se adjuntan a los nodos
Las zonas se adjuntan a los nodos. Los nodos están asociados con una Unidad Central de Procesamiento (CPU). El núcleo intentará asignar memoria para un proceso que se ejecuta en una CPU desde el nodo asociado con esa CPU.
El concepto de nodos vinculados a las CPU permite que se instalen tipos de memoria mixtos en computadoras especializadas con múltiples CPU, utilizando la arquitectura de acceso a memoria no uniforme.
Todo eso es de muy alta gama. La computadora Linux promedio tendrá un solo nodo, llamado nodo cero. Todas las zonas pertenecerán a ese nodo. Para ver los nodos y las zonas en su computadora, mire dentro del archivo /proc/buddyinfo . Usaremos less para hacerlo:
menos /proc/info de amigo

Esta es la salida de la computadora de 64 bits en la que se investigó este artículo:
Nodo 0, zona DMA 1 1 1 0 2 1 1 0 1 1 3 Nodo 0, zona DMA32 2 67 58 19 8 3 3 1 1 1 17
Hay un solo nodo, el nodo cero. Esta computadora solo tiene 2 GB de RAM, por lo que no hay una zona "Normal". Solo hay dos zonas, DMA y DMA32.
Cada columna representa el número de páginas disponibles de un determinado tamaño. Por ejemplo, para la zona DMA32, leyendo desde la izquierda:
- 2 : Hay 2 de 2^( 0 *PAGESIZE) fragmentos de memoria.
- 67 : Hay 67 de 2^( 1 *PAGE_SIZE) fragmentos de memoria.
- 58 : Hay 58 de 2^( 2 *PAGESIZE) fragmentos de memoria disponibles.
- Y así sucesivamente, hasta llegar a…
- 17 : Hay 17 de 2^( 512 *PAGESIZE) fragmentos.
Pero realmente, la única razón por la que estamos viendo esta información es para ver la relación entre los nodos y las zonas.
Páginas de archivo y páginas anónimas
El mapeo de memoria utiliza conjuntos de entradas de la tabla de páginas para registrar qué páginas de memoria se utilizan y para qué.
Las asignaciones de memoria pueden ser:
- Respaldado por archivo: las asignaciones respaldadas por archivo contienen datos que se han leído de un archivo. Puede ser cualquier tipo de archivo. Lo importante a tener en cuenta es que si el sistema liberó esta memoria y necesitaba obtener esos datos nuevamente, se pueden leer del archivo una vez más. Pero, si los datos se han cambiado en la memoria, esos cambios deberán escribirse en el archivo del disco duro antes de que se pueda liberar la memoria. Si eso no sucediera, los cambios se perderían.
- Anónimo : la memoria anónima es un mapeo de memoria sin ningún archivo o dispositivo que lo respalde. Estas páginas pueden contener memoria solicitada sobre la marcha por programas para contener datos, o para cosas como la pila y el montón. Debido a que no existe un archivo detrás de este tipo de datos, se debe reservar un lugar especial para el almacenamiento de datos anónimos. Ese lugar es la partición de intercambio o el archivo de intercambio. Los datos anónimos se escriben para intercambiar antes de que se liberen las páginas anónimas.
- Respaldado por dispositivo : los dispositivos se direccionan a través de archivos de dispositivo de bloque que se pueden tratar como si fueran archivos. Los datos se pueden leer y escribir en ellos. Una asignación de memoria respaldada por dispositivo tiene datos de un dispositivo almacenados en ella.
- Compartido : varias entradas de la tabla de páginas pueden asignarse a la misma página de RAM. Acceder a las ubicaciones de memoria a través de cualquiera de las asignaciones mostrará los mismos datos. Diferentes procesos pueden comunicarse entre sí de una manera muy eficiente al cambiar los datos en estas ubicaciones de memoria observadas conjuntamente. Las asignaciones de escritura compartidas son un medio común para lograr comunicaciones entre procesos de alto rendimiento.
- Copiar al escribir : Copiar al escribir es una técnica de asignación diferida. Si se solicita una copia de un recurso que ya está en la memoria, la solicitud se satisface devolviendo una asignación al recurso original. Si uno de los procesos que "comparte" el recurso intenta escribir en él, el recurso debe replicarse verdaderamente en la memoria para permitir que se realicen los cambios en la nueva copia. Entonces, la asignación de memoria solo tiene lugar en el primer comando de escritura.
Para swappiness, solo necesitamos preocuparnos por los dos primeros en la lista: páginas de archivos y páginas anónimas.
intercambio
Aquí está la descripción de swappiness de la documentación de Linux en GitHub:
"This control is used to define how aggressive (sic) the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60."
Eso suena como swappiness cambia hacia arriba o hacia abajo en intensidad. Curiosamente, establece que establecer swappiness en cero no desactiva el intercambio. Le indica al kernel que no cambie hasta que se cumplan ciertas condiciones. Pero el intercambio todavía puede ocurrir.
Profundicemos. Aquí está la definición y el valor predeterminado de vm_swappiness en el archivo de código fuente del kernel vmscan.c:
/*
* From 0 .. 100. Higher means more swappy.
*/
int vm_swappiness = 60;
El valor de swappiness puede variar de 0 a 100. Una vez más, el comentario ciertamente parece que el valor de swappiness tiene relación con la cantidad de intercambios que se realizan, con una cifra más alta que conduce a más intercambios.
Más adelante en el archivo de código fuente, podemos ver que a una nueva variable llamada swappiness se le asigna un valor que es devuelto por la función mem_cgroup_swappiness() . Un poco más de rastreo a través del código fuente mostrará que el valor devuelto por esta función es vm_swappiness . Así que ahora, la variable swappiness está configurada para igualar cualquier valor en el que se haya configurado vm_swappiness .
int swappiness = mem_cgroup_swappiness(memcg);
Y un poco más abajo en el mismo archivo de código fuente, vemos esto:
/*
* With swappiness at 100, anonymous and file have the same priority.
* This scanning priority is essentially the inverse of IO cost.
*/
anon_prio = swappiness;
file_prio = 200 - anon_prio;
Eso es interesante. Dos valores distintos se derivan de swappiness . Las variables anon_prio y file_prio contienen estos valores. A medida que uno aumenta, el otro disminuye, y viceversa .
El valor de intercambio de Linux en realidad establece la relación entre dos valores.
la proporción áurea
Las páginas de archivos contienen datos que se pueden recuperar fácilmente si se libera esa memoria. Linux puede simplemente leer el archivo de nuevo. Como hemos visto, si los datos del archivo se han cambiado en la RAM, esos cambios deben escribirse en el archivo antes de que se pueda liberar la página del archivo. Pero, de cualquier manera, la página del archivo en la RAM se puede volver a llenar leyendo los datos del archivo. Entonces, ¿por qué molestarse en agregar estas páginas a la partición de intercambio o al archivo de intercambio? Si necesita esos datos nuevamente, también puede volver a leerlos desde el archivo original en lugar de una copia redundante en el espacio de intercambio. Por lo tanto, las páginas de archivos no se almacenan en intercambio. Están "almacenados" en el archivo original.
Con páginas anónimas, no hay un archivo subyacente asociado con los valores en la memoria. Se ha llegado a los valores de esas páginas de forma dinámica. No puede simplemente volver a leerlos desde un archivo. La única forma en que se pueden recuperar los valores de la memoria de la página anónima es almacenar los datos en algún lugar antes de liberar la memoria. Y eso es lo que tiene el intercambio. Páginas anónimas a las que necesitará volver a hacer referencia.
Pero tenga en cuenta que tanto para las páginas de archivos como para las páginas anónimas, liberar la memoria puede requerir una escritura en el disco duro. Si los datos de la página del archivo o los datos de la página anónima han cambiado desde la última vez que se escribieron en el archivo o en el intercambio, se requiere una escritura del sistema de archivos. Para recuperar los datos se requerirá una lectura del sistema de archivos. Ambos tipos de recuperación de páginas son costosos. Intentar reducir la entrada y salida del disco duro minimizando el intercambio de páginas anónimas solo aumenta la cantidad de entrada y salida del disco duro que se requiere para manejar las páginas de archivos que se escriben y leen en los archivos.

Como puede ver en el último fragmento de código, hay dos variables. Uno llamado file_prio para "prioridad de archivo" y otro llamado anon_prio para "prioridad anónima".
- La variable
anon_priose establece en el valor de swappiness de Linux. - El valor de
file_priose establece en 200 menos el valor deanon_prio.
Estas variables tienen valores que funcionan en tándem. Si ambos se establecen en 100, son iguales. Para cualquier otro valor, anon_prio disminuirá de 100 a 0, y file_prio aumentará de 100 a 200. Los dos valores alimentan un algoritmo complicado que determina si el kernel de Linux se ejecuta con preferencia para reclamar (liberar) páginas de archivos o páginas anónimas. paginas
Puede pensar en file_prio como la voluntad del sistema de liberar páginas de archivos y anon_prio como la voluntad del sistema de liberar páginas anónimas. Lo que estos valores no hacen es establecer ningún tipo de desencadenante o umbral para cuándo se utilizará el intercambio. Eso se decide en otra parte.
Pero, cuando es necesario liberar memoria, los algoritmos de recuperación e intercambio tienen en cuenta estas dos variables, y la proporción entre ellas, para determinar qué tipos de página se consideran preferentemente para liberar. Y eso determina si la actividad del disco duro asociado procesará archivos para páginas de archivos o intercambiará espacio para páginas anónimas.
¿Cuándo se inicia realmente el intercambio?
Hemos establecido que el valor de swappiness de Linux establece una preferencia por el tipo de páginas de memoria que se escanearán para una posible recuperación. Eso está bien, pero algo debe decidir cuándo se activará el intercambio.
Cada zona de memoria tiene una marca de agua alta y una marca de agua baja. Estos son valores derivados del sistema. Son porcentajes de la RAM de cada zona. Son estos valores los que se utilizan como umbrales de activación de intercambio.
Para verificar cuáles son sus marcas de agua alta y baja, mire dentro del archivo /proc/zoneinfo con este comando:
menos /proc/zoneinfo

Cada una de las zonas tendrá un conjunto de valores de memoria medidos en páginas. Estos son los valores para la zona DMA32 en la máquina de prueba. La marca de agua baja es de 13966 páginas y la marca de agua alta es de 16759 páginas:
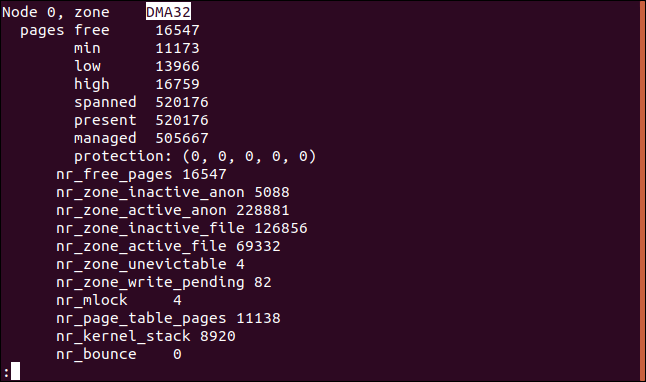
- En condiciones normales de funcionamiento, cuando la memoria libre en una zona cae por debajo de la marca de límite inferior de la zona, el algoritmo de intercambio comienza a escanear páginas de memoria en busca de memoria que pueda reclamar, teniendo en cuenta los valores relativos de
anon_prioyfile_prio. - Si el valor de intercambio de Linux se establece en cero, el intercambio se produce cuando el valor combinado de las páginas de archivo y las páginas libres es menor que la marca de límite superior.
Entonces puede ver que no puede usar el valor de intercambio de Linux para influir en el comportamiento del intercambio con respecto al uso de RAM. Simplemente no funciona así.
¿En qué se debe establecer Swapiness?
Esto depende del hardware, la carga de trabajo, el tipo de disco duro y si su computadora es una computadora de escritorio o un servidor. Obviamente, esto no va a ser una talla única para todo tipo de configuración.
Y debe tener en cuenta que el intercambio no solo se usa como un mecanismo para liberar RAM cuando se está quedando sin espacio de memoria. El intercambio es una parte importante de un buen funcionamiento del sistema, y sin él, la gestión de la memoria se vuelve muy difícil de lograr para Linux.
Cambiar el valor de swappiness de Linux tiene un efecto instantáneo; no necesitas reiniciar. Para que pueda hacer pequeños ajustes y monitorear los efectos. Idealmente, haría esto durante un período de días, con diferentes tipos de actividad en su computadora, para tratar de encontrar lo más cercano a una configuración ideal que pueda.
Estos son algunos puntos a considerar:
- Intentar "deshabilitar el intercambio" configurando el valor de intercambio de Linux en cero simplemente cambia la actividad del disco duro asociada al intercambio a la actividad del disco duro asociada al archivo.
- Si tiene discos duros mecánicos obsoletos, puede intentar reducir el valor de swappiness de Linux para evitar la recuperación de páginas anónimas y reducir la rotación de particiones de intercambio. Por supuesto, a medida que baja una configuración, la otra configuración aumenta. Es probable que la reducción de la rotación de intercambio aumente la rotación del sistema de archivos. Pero su computadora podría estar más feliz favoreciendo un método sobre el otro. Realmente, la única forma de saberlo con seguridad es probar y ver.
- Para los servidores de un solo propósito, como los servidores de bases de datos, puede obtener orientación de los proveedores del software de la base de datos. Muy a menudo, estas aplicaciones tienen sus propias rutinas de administración de memoria y caché de archivos especialmente diseñadas en las que es mejor confiar. Los proveedores de software pueden sugerir un valor de intercambio de Linux según la especificación de la máquina y la carga de trabajo.
- ¿Para el usuario de escritorio promedio con hardware razonablemente reciente? Déjalo así.
Cómo establecer el valor de intercambio de Linux
Antes de cambiar su valor de swappiness, necesita saber cuál es su valor actual. Si quieres reducirlo un poco, la pregunta es ¿un poco menos que qué? Puedes averiguarlo con este comando:
gato /proc/sys/vm/intercambio

Para configurar el valor de swappiness, use el comando sysctl :
sudo sysctl vm.swappiness=45

El nuevo valor se usa de inmediato, no es necesario reiniciar.
De hecho, si reinicia, el valor de swappiness volverá a su valor predeterminado de 60. Cuando haya terminado de experimentar y haya decidido el nuevo valor que desea usar, puede hacerlo persistente entre reinicios agregándolo a /etc/sysctl.conf archivo. Puedes usar el editor que prefieras. Use el siguiente comando para editar el archivo con el editor nano :
sudo nano /etc/sysctl.conf

Cuando se abra nano , desplácese hasta la parte inferior del archivo y agregue esta línea. Estamos usando 35 como el valor de intercambio permanente. Debe sustituir el valor que desea utilizar.
vm.intercambio=35
Para guardar sus cambios y salir de nano , presione "Ctrl+O", presione "Enter" y presione "Ctrl+Z".
La gestión de la memoria es compleja
La gestión de la memoria es complicada. Y es por eso que, para el usuario promedio, generalmente es mejor dejarlo en manos del kernel.
Es fácil pensar que estás usando más RAM de la que estás. Las utilidades como top y free pueden dar una impresión equivocada. Linux usará RAM libre para una variedad de sus propios propósitos, como el almacenamiento en caché del disco. Esto eleva artificialmente la cifra de memoria "usada" y reduce la cifra de memoria "libre". De hecho, la RAM utilizada como caché de disco se marca tanto como "usada" como "disponible" porque se puede recuperar en cualquier momento y muy rápidamente.
Para los no iniciados, puede parecer que el intercambio no funciona, o que el valor de intercambio debe cambiarse.
Como siempre, el diablo está en los detalles. O, en este caso, el demonio. El demonio de intercambio del kernel.
| Comandos Linux | ||
| archivos | tar · pv · cat · tac · chmod · grep · diff · sed · ar · man · pushd · popd · fsck · testdisk · seq · fd · pandoc · cd · $PATH · awk · join · jq · fold · uniq · journalctl · cola · stat · ls · fstab · eco · menos · chgrp · chown · rev · mirar · cadenas · tipo · renombrar · zip · descomprimir · montar · desmontar · instalar · fdisk · mkfs · rm · rmdir · rsync · df · gpg · vi · nano · mkdir · du · ln · parche · convertir · rclone · triturar · srm | |
| Procesos | alias · pantalla · top · agradable · renice · progreso · strace · systemd · tmux · chsh · historia · at · lote · gratis · cual · dmesg · chfn · usermod · ps · chroot · xargs · tty · pinky · lsof · vmstat · tiempo de espera · pared · sí · matar · dormir · sudo · su · hora · groupadd · usermod · grupos · lshw · apagar · reiniciar · detener · apagar · contraseña · lscpu · crontab · fecha · bg · fg | |
| Redes | netstat · ping · traceroute · ip · ss · whois · fail2ban · bmon · cavar · dedo · nmap · ftp · curl · wget · quién · whoami · w · iptables · ssh-keygen · ufw |
RELACIONADO: Las mejores computadoras portátiles Linux para desarrolladores y entusiastas