
Cómo usar el comando wc en Linux
Publicado: 2022-07-23
Contar el número de líneas, palabras y bytes en un archivo es útil, pero la verdadera flexibilidad del comando wc de Linux proviene de trabajar con otros comandos. Vamos a ver.
¿Qué es el comando wc?
El comando wc es una pequeña aplicación. Es una de las principales utilidades de Linux, por lo que no es necesario instalarla. Ya estará en su computadora Linux.
Puede describir lo que hace en muy pocas palabras. Cuenta las líneas, palabras y bytes en un archivo o selección de archivos e imprime el resultado en una ventana de terminal. También puede tomar su entrada de la secuencia STDIN, lo que significa que el texto que desea que procese se puede canalizar en él. Aquí es donde wc realmente comienza a agregar valor.

Es un gran ejemplo del mantra de Linux de "haz una cosa y hazla bien". Debido a que acepta entradas canalizadas, puede usarse en conjuros de múltiples comandos. Como veremos, esta pequeña utilidad independiente es en realidad un gran jugador de equipo.
Una forma en que uso wc es como marcador de posición en un comando complicado o alias que estoy preparando. Si el comando terminado tiene el potencial de ser destructivo y eliminar archivos, a menudo uso wc como sustituto del comando real y peligroso.
De esa forma, durante el desarrollo del comando, obtengo información visual de que cada archivo se está procesando como esperaba. No hay posibilidad de que suceda algo malo mientras lucho con la sintaxis.
Tan simple como es wc , todavía hay algunas pequeñas peculiaridades que debe conocer.
Primeros pasos con wc
La forma más sencilla de usar wc es pasar el nombre de un archivo de texto en la línea de comando.
wc lorem.txt

Esto hace que wc escanee el archivo y cuente las líneas, palabras y bytes, y los escriba en la ventana del terminal.
Las palabras se consideran cualquier cosa limitada por espacios en blanco. Si son palabras de un idioma real o no, es irrelevante. Si un archivo no contiene nada más que "frd g lkj", todavía cuenta como tres palabras.
Las líneas son secuencias de caracteres que terminan en un retorno de carro o al final del archivo. No importa si la línea se ajusta en su editor o en la ventana de la terminal, hasta que wc encuentra un retorno de carro o el final del archivo, sigue siendo la misma línea.
Nuestro primer ejemplo encontró una línea en todo el archivo. Aquí está el contenido del archivo “lorem.txt”.
gato lorem.txt
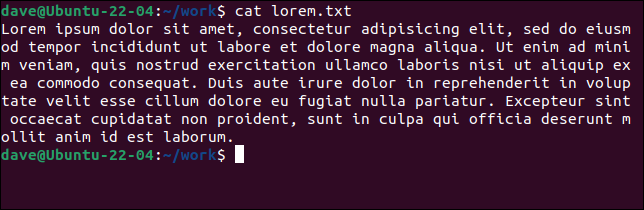
Todo eso cuenta como una sola línea porque no hay retornos de carro. Compare esto con otro archivo, "lorem2.txt", y cómo lo interpreta wc .
wc lorem2.txt
gato lorem2.txt
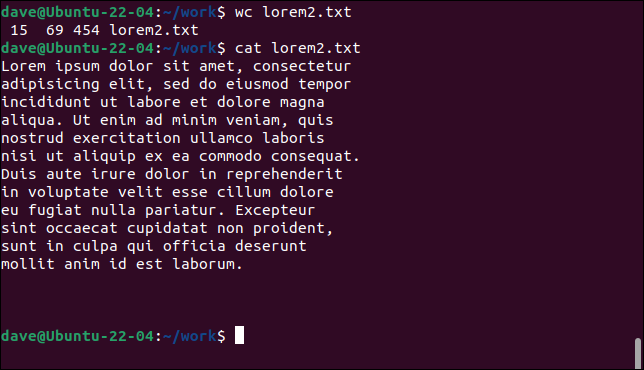
Esta vez, wc cuenta 15 líneas porque se han insertado retornos de carro en el texto para comenzar una nueva línea en puntos específicos. Sin embargo, si cuenta las líneas con texto, verá que solo hay 12.
Las otras tres líneas son líneas en blanco al final del archivo. Estos contienen sólo retornos de carro. Aunque no hay texto en estas líneas, se ha iniciado una nueva línea y las wc como tales.
Podemos pasar tantos archivos a wc como queramos.
wc lorem.txt lorem2.txt
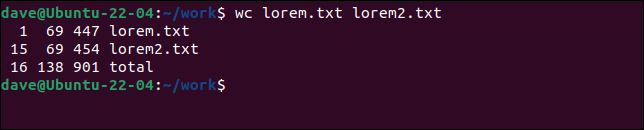
Obtenemos las estadísticas para cada archivo individual y un total para todos los archivos.
También podemos usar comodines para poder seleccionar archivos coincidentes en lugar de archivos con nombres explícitos.
wc *.txt *.?
Las opciones de la línea de comandos
Por defecto, wc mostrará las líneas, palabras y bytes en cada archivo. Es lo mismo que usar las opciones -l (líneas), -w (palabras) y -c (bytes).
wc lorem.txt
wc -l -w -c lorem.txt
Podemos especificar qué combinación de figuras queremos ver.
wc -l lorem.txt wc -w lorem.txt wc -c lorem.txt wc -l -c lorem.txt
Se debe prestar especial atención a la última cifra, generada por la opción -c (bytes). Muchas personas confunden esto con contar los caracteres. En realidad cuenta bytes . El número de caracteres y el número de bytes bien podrían ser los mismos. Pero no siempre.
Veamos el contenido de un archivo llamado "unicode.txt".
gato unicode.txt

Tiene tres palabras y un carácter del alfabeto no latino. Dejaremos que wc procese el archivo con su configuración predeterminada de bytes , y lo haremos de nuevo, pero solicitaremos caracteres con la opción -m (caracteres).
wc unicode.txt
wc -l -w -m unicode.txt
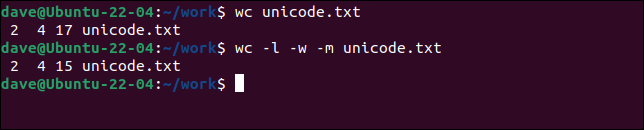
Hay más bytes que caracteres.
Echemos un vistazo al volcado hexadecimal del archivo y veamos qué está pasando. La opción -C (canónica) del comando hexdump muestra los bytes del archivo en líneas de 16, con su equivalente ASCII simple (si lo hay) al final de la línea. Si no hay ningún carácter ASCII correspondiente, un punto “ . ” se muestra en su lugar.

volcado hexadecimal -C unicode.txt
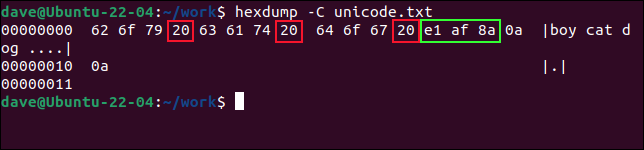
En ASCII, un valor hexadecimal de 0x20 representa un carácter de espacio. Si contamos tres valores desde la izquierda, vemos que el siguiente valor es un carácter de espacio. Entonces, esos primeros tres valores 0x62 , 0x6f y 0x79 representan las letras en "niño".
Saltando sobre el 0x20 , vemos otro conjunto de tres valores hexadecimales: 0x63 , 0x61 y 0x74 . Estos deletrean "gato". Saltando sobre el siguiente carácter de espacio, vemos tres valores más para las letras en "perro". Estos son 0x64 , 0x5f y 0x67 .
Justo detrás de la palabra "perro" podemos ver un carácter de espacio 0x20 y cinco valores hexadecimales más. Los dos últimos son retornos de carro, 0x0a .
Los otros tres bytes representan el carácter no latino, que hemos marcado en verde. Es un carácter Unicode y se necesitan tres bytes para codificarlo. Estos son 0xe1 , 0xaf y 0x8a .
Así que asegúrese de saber lo que está contando y de que los bytes y los caracteres no tienen por qué ser iguales. Por lo general, contar bytes es más útil porque le dice qué hay realmente dentro del archivo. Contar por caracteres le da la cantidad de cosas representadas por el contenido del archivo.
RELACIONADO: ¿Qué son las codificaciones de caracteres como ANSI y Unicode, y en qué se diferencian?
Tomar nombres de archivo de un archivo
Hay otra forma de proporcionar nombres de archivo a wc . Puede poner los nombres de archivo en un archivo y pasar el nombre de ese archivo a wc . Abre el archivo, extrae los nombres de archivo y los procesa como si se hubieran pasado en la línea de comandos. Esto le permite almacenar una colección arbitraria de nombres de archivo para su reutilización.
Pero hay un problema, y es uno grande. Los nombres de archivo deben terminar en nulo , no en retorno de carro . Es decir, después de cada nombre de archivo debe haber un byte nulo de 0x00 en lugar del byte de retorno de carro habitual 0x0a .
No puede abrir un editor y crear un archivo con este formato. Por lo general, los archivos como este son generados por otros programas. Pero, si tiene un archivo de este tipo, así es como lo usaría.
Aquí está nuestro archivo que contiene los nombres de archivo. Al abrirlo en less , se muestran los extraños caracteres " ^@ " que less usa para indicar bytes nulos.
menos fuente-archivos-list.txt

Para usar el archivo con wc , necesitamos usar --files0-from (leer entrada desde) y pasar el nombre del archivo que contiene los nombres de archivo.
wc ---files0-from=lista-de-archivos-fuente.txt
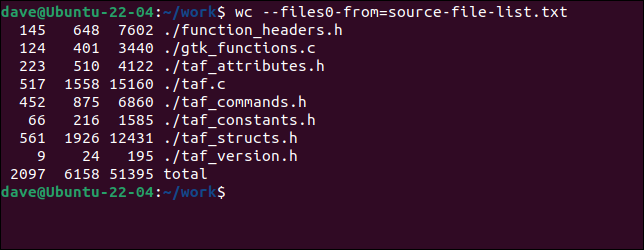
Los archivos se procesan exactamente como si se hubieran proporcionado en la línea de comandos.
Tubería Entrada al inodoro
Una forma mucho más común, flexible y productiva de enviar entradas a wc es canalizar la salida de otros comandos a wc . Podemos demostrar esto con el comando echo .
echo "Cuenta esto por mi" | WC
echo -e "Cuenta esto\npara mí" | WC
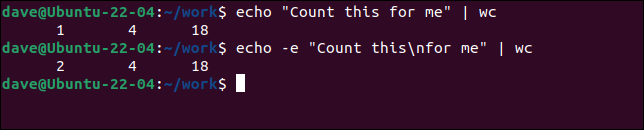
El segundo comando echo usa la opción -e (caracteres escapados) para permitir secuencias escapadas como el código de formato de nueva línea “ \n ”. Esto inyecta una nueva línea, lo que hace que wc vea la entrada como dos líneas.
Aquí hay una cascada de comandos que alimentan su entrada de uno a otro.
encontrar ./* -tipo f | revolución | corte -d'.' -f1 | revolución | ordenar | único
- find busca archivos (
type -f) recursivamente, comenzando en el directorio actual.revinvierte los nombres de archivo. - cut extrae el primer campo (
-f1) definiendo el delimitador de campo como un punto “.” y leyendo desde el “frente” del nombre de archivo invertido hasta el primer punto que encuentra. Ahora hemos extraído la extensión del archivo. - rev invierte el primer campo extraído.
- ordenar los ordena en orden alfabético ascendente.
- uniq enumera las entradas únicas en la ventana del terminal.
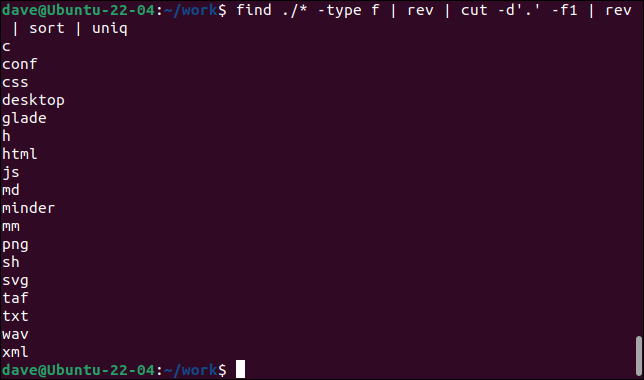
Este comando enumera todas las extensiones de archivo únicas en el directorio actual y cualquier subdirectorio.
Si agregamos la opción -c (contar) al comando uniq , contaría las ocurrencias de cada tipo de extensión. Pero si queremos saber cuántas extensiones de archivo diferentes y únicas hay, podemos colocar wc como el último comando en la línea y usar la opción -l (líneas).
encontrar ./* -tipo f | revolución | corte -d'.' -f1 | revolución | ordenar | único | wc-l

RELACIONADO: Cómo usar el comando de corte de Linux
Y finalmente
Aquí hay un último truco que wc puede hacer por ti. Le dirá la longitud de la línea más larga en un archivo. Lamentablemente, no te dice qué línea es. Solo te da la longitud.
wc -L taf.c

Sin embargo, tenga cuidado, las pestañas se cuentan como ocho espacios. Visto en mi editor, hay tres pestañas de dos espacios al comienzo de esa línea. Su longitud real es de 124 caracteres. Por lo que la cifra reportada se amplía artificialmente.
Trataría esta función con una gran pizca de sal. Y con eso quiero decir que no lo uses. Su salida es engañosa.
A pesar de sus peculiaridades, wc es una excelente herramienta para ingresar comandos canalizados cuando necesita contar todo tipo de valores, no solo las palabras en un archivo.
RELACIONADO: 37 comandos importantes de Linux que debe conocer