
Cómo analizar datos CSV en Bash
Publicado: 2022-09-16
Los archivos de valores separados por comas (CSV) son uno de los formatos más comunes para los datos exportados. En Linux, podemos leer archivos CSV usando comandos Bash. Pero puede volverse muy complicado, muy rápidamente. Echaremos una mano.
¿Qué es un archivo CSV?
Un archivo de valores separados por comas es un archivo de texto que contiene datos tabulados. CSV es un tipo de datos delimitados. Como sugiere el nombre, se usa una coma " , " para separar cada campo de datos, o valor , de sus vecinos.
CSV está en todas partes. Si una aplicación tiene funciones de importación y exportación, casi siempre admitirá CSV. Los archivos CSV son legibles por humanos. Puede mirar dentro de ellos con menos, abrirlos en cualquier editor de texto y moverlos de un programa a otro. Por ejemplo, puede exportar los datos de una base de datos SQLite y abrirlos en LibreOffice Calc.
Sin embargo, incluso CSV puede volverse complicado. ¿Quieres tener una coma en un campo de datos? Ese campo debe tener comillas “ " ” entre comillas. Para incluir comillas en un campo, cada comilla debe ingresarse dos veces.
Por supuesto, si está trabajando con CSV generado por un programa o secuencia de comandos que ha escrito, es probable que el formato CSV sea simple y directo. Si se ve obligado a trabajar con formatos CSV más complejos, siendo Linux Linux, también existen soluciones que podemos usar para eso.
Algunos datos de muestra
Puede generar fácilmente algunos datos CSV de muestra, utilizando sitios como Online Data Generator. Puede definir los campos que desea y elegir cuántas filas de datos desea. Sus datos se generan utilizando valores ficticios realistas y se descargan a su computadora.
Creamos un archivo que contiene 50 filas de información ficticia de empleados:
- id : Un valor entero único simple.
- firstname : El primer nombre de la persona.
- lastname : El apellido de la persona.
- job-title : Título del trabajo de la persona.
- dirección de correo electrónico : la dirección de correo electrónico de la persona.
- sucursal : La sucursal de la empresa en la que trabajan.
- estado : El estado en el que se encuentra la sucursal.
Algunos archivos CSV tienen una línea de encabezado que enumera los nombres de los campos. Nuestro archivo de muestra tiene uno. Aquí está la parte superior de nuestro archivo:
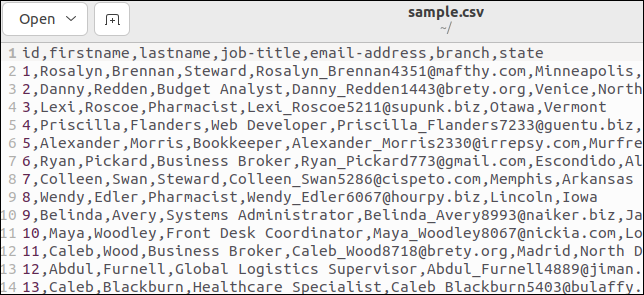
La primera línea contiene los nombres de los campos como valores separados por comas.
Análisis de datos desde el archivo CSV
Escribamos un script que lea el archivo CSV y extraiga los campos de cada registro. Copie este script en un editor y guárdelo en un archivo llamado "field.sh".
#! /bin/bash while IFS=”, read -r id nombre apellido puesto puesto correo electrónico sucursal estado hacer echo "ID de registro: $id" echo "Nombre: $nombre" echo "Apellido: $apellido" echo "Título del trabajo: $título del trabajo" echo "Correo electrónico agregar: $correo electrónico" echo "Sucursal: $sucursal" echo "Estado: $estado" eco "" hecho < <(cola -n +2 muestra.csv)
Hay bastante contenido en nuestro pequeño guión. Vamos a desglosarlo.

Estamos usando un bucle while . Siempre que la condición del bucle while se resuelva como verdadera, se ejecutará el cuerpo del bucle while . El cuerpo del bucle es bastante simple. Se utiliza una colección de declaraciones de echo para imprimir los valores de algunas variables en la ventana del terminal.
La condición del ciclo while es más interesante que el cuerpo del ciclo. Especificamos que debe usarse una coma como separador de campo interno, con la instrucción IFS="," . El IFS es una variable de entorno. El comando de read hace referencia a su valor al analizar secuencias de texto.
Estamos usando la opción -r (retener barras invertidas) del comando de read para ignorar cualquier barra invertida que pueda haber en los datos. Serán tratados como personajes normales.
El texto que analiza el comando de read se almacena en un conjunto de variables con el nombre de los campos CSV. Podrían haberse llamado field1, field2, ... field7 la misma facilidad, pero los nombres significativos facilitan la vida.
Los datos se obtienen como salida del comando tail . Usamos tail porque nos brinda una manera simple de saltar la línea de encabezado del archivo CSV. La opción -n +2 (número de línea) le dice a tail que comience a leer en la línea número dos.
La construcción <(...) se denomina sustitución de procesos. Hace que Bash acepte la salida de un proceso como si viniera de un descriptor de archivo. Esto luego se redirige al ciclo while , proporcionando el texto que analizará el comando de read .
Haga que el script sea ejecutable con el comando chmod . Deberá hacer esto cada vez que copie una secuencia de comandos de este artículo. Sustituya el nombre del script apropiado en cada caso.
chmod +x campo.sh

Cuando ejecutamos el script, los registros se dividen correctamente en sus campos constituyentes, con cada campo almacenado en una variable diferente.
./campo.sh
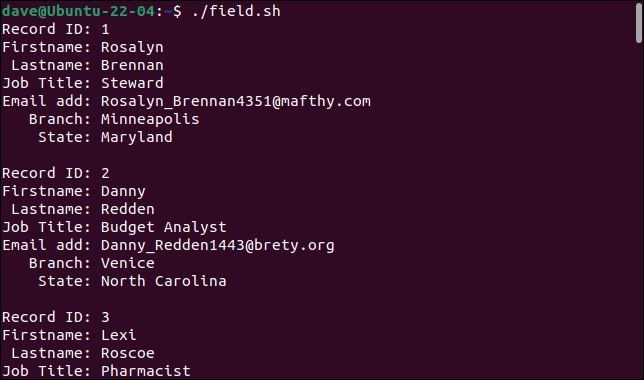
Cada registro se imprime como un conjunto de campos.
Selección de campos
Tal vez no queramos o necesitemos recuperar todos los campos. Podemos obtener una selección de campos incorporando el comando cut .
Este script se llama "select.sh".
#!/bin/bash while IFS=”, read -r id título del trabajo rama estado hacer echo "ID de registro: $id" echo "Título del trabajo: $título del trabajo" echo "Sucursal: $sucursal" echo "Estado: $estado" eco "" hecho < <(cortar -d "," -f1,4,6,7 muestra.csv | cola -n +2)
Hemos agregado el comando de cut en la cláusula de sustitución del proceso. Estamos usando la opción -d (delimitador) para decirle a cut que use comas “ , ” como delimitador. La opción -f (campo) le dice a cut que queremos los campos uno, cuatro, seis y siete. Esos cuatro campos se leen en cuatro variables, que se imprimen en el cuerpo del ciclo while .
Esto es lo que obtenemos cuando ejecutamos el script.
./select.sh
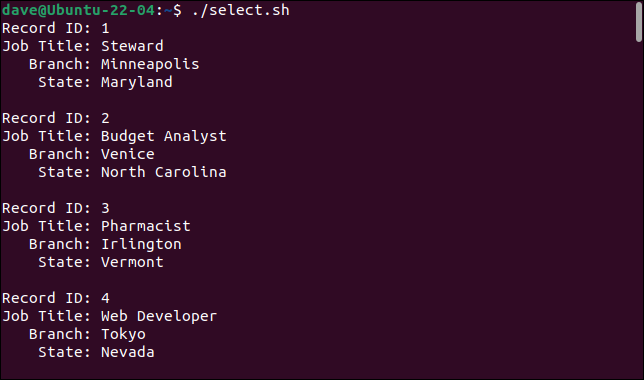
Al agregar el comando de cut , podemos seleccionar los campos que queremos e ignorar los que no.
Hasta ahora, todo bien. Pero…
Si el CSV con el que trabaja no tiene complicaciones ni comas ni comillas en los datos de campo, lo que hemos cubierto probablemente satisfaga sus necesidades de análisis de CSV. Para mostrar los problemas que podemos encontrar, modificamos una pequeña muestra de los datos para que se vean así.
id, nombre, apellido, cargo, dirección de correo electrónico, sucursal, estado 1, Rosalyn, Brennan, "Administrador, Sénior", [email protected], Minneapolis, Maryland 2,Danny,Redden,"Analista ""Presupuesto""",[email protected],Venice,Carolina del Norte 3, Lexi, Roscoe, farmacéutica, Irlington, Vermont
- El registro uno tiene una coma en el campo
job-title, por lo que el campo debe estar entre comillas. - El registro dos tiene una palabra entre dos conjuntos de comillas en el campo
jobs-title. - El registro tres no tiene datos en el campo
email-address.
Estos datos se guardaron como "sample2.csv". Modifique su script "field.sh" para llamar a "sample2.csv" y guárdelo como "field2.sh".
#! /bin/bash while IFS=”, read -r id nombre apellido puesto puesto correo electrónico sucursal estado hacer echo "ID de registro: $id" echo "Nombre: $nombre" echo "Apellido: $apellido" echo "Título del trabajo: $título del trabajo" echo "Correo electrónico agregar: $correo electrónico" echo "Sucursal: $sucursal" echo "Estado: $estado" eco "" hecho < <(cola -n +2 muestra2.csv)
Cuando ejecutamos este script, podemos ver grietas que aparecen en nuestros analizadores CSV simples.

./campo2.sh

El primer registro divide el campo del título del trabajo en dos campos y trata la segunda parte como la dirección de correo electrónico. Cada campo después de este se desplaza un lugar a la derecha. El último campo contiene tanto la branch como los valores de state .
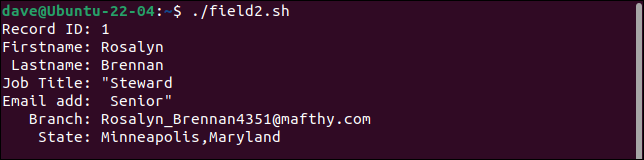
El segundo registro conserva todas las comillas. Solo debe tener un par de comillas alrededor de la palabra "Presupuesto".
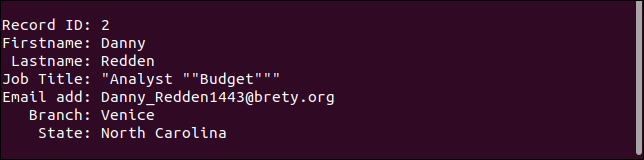
El tercer registro en realidad maneja el campo que falta como debería. Falta la dirección de correo electrónico, pero todo lo demás es como debería ser.

Contrariamente a la intuición, para un formato de datos simple, es muy difícil escribir un analizador CSV robusto de casos generales. Herramientas como awk le permitirán acercarse, pero siempre hay casos extremos y excepciones que se escapan.

Intentar escribir un analizador CSV infalible probablemente no sea la mejor manera de avanzar. Un enfoque alternativo, especialmente si está trabajando con una fecha límite de algún tipo, emplea dos estrategias diferentes.
Una es usar una herramienta diseñada específicamente para manipular y extraer sus datos. El segundo es desinfectar sus datos y reemplazar escenarios problemáticos como comas incrustadas y comillas. Sus analizadores simples de Bash pueden hacer frente al CSV compatible con Bash.
El kit de herramientas csvkit
El kit de herramientas CSV csvkit es una colección de utilidades creadas expresamente para ayudar a trabajar con archivos CSV. Deberá instalarlo en su computadora.
Para instalarlo en Ubuntu, use este comando:
sudo apt instalar csvkit

Para instalarlo en Fedora, debe escribir:
sudo dnf instalar python3-csvkit

En Manjaro el comando es:
sudo pacman -S csvkit

Si le pasamos el nombre de un archivo CSV, la utilidad csvlook muestra una tabla con el contenido de cada campo. El contenido del campo se muestra para mostrar lo que representan los contenidos del campo, no como están almacenados en el archivo CSV.
Probemos csvlook con nuestro archivo problemático "sample2.csv".
csvlook muestra2.csv
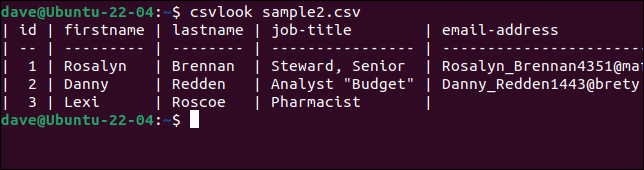
Todos los campos se muestran correctamente. Esto prueba que el problema no es el CSV. El problema es que nuestros scripts son demasiado simples para interpretar el CSV correctamente.
Para seleccionar columnas específicas, use el comando csvcut . La opción -c (columna) se puede usar con nombres de campo o números de columna, o una combinación de ambos.
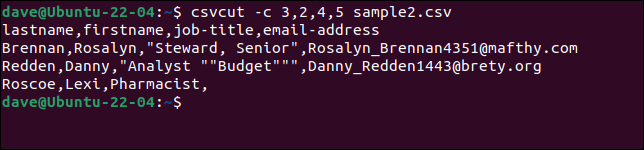
Supongamos que necesitamos extraer el nombre y apellido, los cargos y las direcciones de correo electrónico de cada registro, pero queremos que el orden de los nombres sea "apellido, nombre". Todo lo que tenemos que hacer es poner los nombres de los campos o números en el orden que los queremos.
Estos tres comandos son todos equivalentes.
csvcut -c apellido, nombre, puesto de trabajo, dirección de correo electrónico sample2.csv
csvcut -c apellido,nombre,4,5 muestra2.csv
csvcut -c 3,2,4,5 muestra2.csv
Podemos agregar el comando csvsort para ordenar la salida por un campo. Usamos la opción -c (columna) para especificar la columna por la que ordenar y la opción -r (inversa) para ordenar en orden descendente.
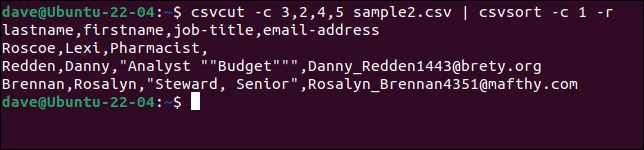
csvcut -c 3,2,4,5 muestra2.csv | csvordenar -c 1 -r
Para hacer que la salida sea más bonita, podemos alimentarla a través csvlook .
csvcut -c 3,2,4,5 muestra2.csv | csvordenar -c 1 -r | csvlook
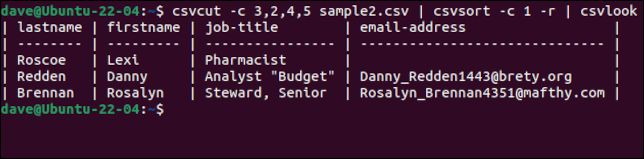
Un buen toque es que, aunque los registros están ordenados, la línea de encabezado con los nombres de los campos se mantiene como la primera línea. Una vez que estemos contentos de tener los datos como los queremos, podemos eliminar el csvlook de la cadena de comandos y crear un nuevo archivo CSV redirigiendo la salida a un archivo.
Agregamos más datos al "sample2.file", eliminamos el comando csvsort y creamos un nuevo archivo llamado "sample3.csv".
csvcut -c 3,2,4,5 muestra2.csv > muestra3.csv

Una forma segura de desinfectar datos CSV
Si abre un archivo CSV en LibreOffice Calc, cada campo se colocará en una celda. Puede usar la función de buscar y reemplazar para buscar comas. Puede reemplazarlos con "nada" para que desaparezcan, o con un carácter que no afecte el análisis de CSV, como un punto y coma " ; " por ejemplo.
No verá las comillas alrededor de los campos citados. Las únicas comillas que verá son las comillas incrustadas dentro de los datos de campo. Estos se muestran como comillas simples. Si los encuentra y los reemplaza con un solo apóstrofe “ ' ”, se reemplazarán las comillas dobles en el archivo CSV.
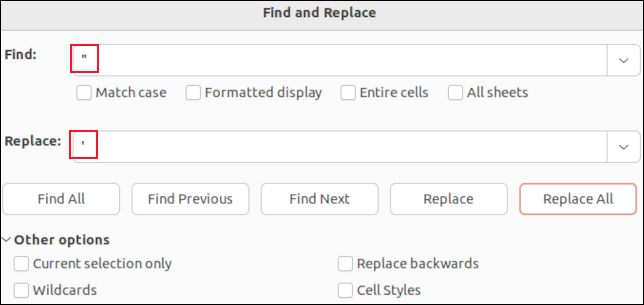
Hacer la búsqueda y el reemplazo en una aplicación como LibreOffice Calc significa que no puede eliminar accidentalmente ninguna de las comas separadoras de campo, ni eliminar las comillas alrededor de los campos citados. Solo cambiará los valores de datos de los campos.
Cambiamos todas las comas en los campos con punto y coma y todas las comillas incrustadas con apóstrofes y guardamos nuestros cambios.
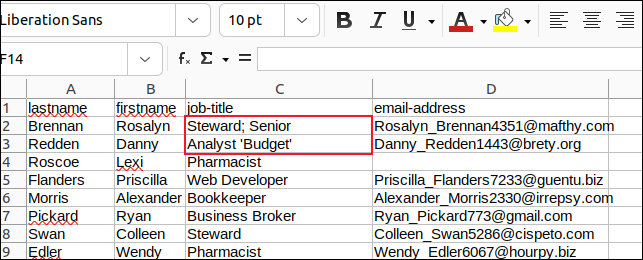
Luego creamos un script llamado "field3.sh" para analizar "sample3.csv".
#! /bin/bash while IFS=”, read -r apellido nombre puesto puesto correo electrónico hacer echo "Apellido: $apellido" echo "Nombre: $nombre" echo "Título del trabajo: $título del trabajo" echo "Correo electrónico agregar: $correo electrónico" eco "" hecho < <(cola -n +2 muestra3.csv)
Veamos qué obtenemos cuando lo ejecutamos.
./campo3.sh
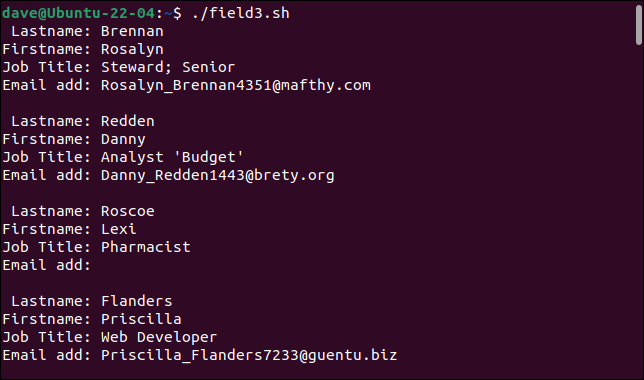
Nuestro analizador simple ahora puede manejar nuestros registros previamente problemáticos.
Verás mucho CSV
Podría decirse que CSV es lo más parecido a una lengua común para los datos de la aplicación. La mayoría de las aplicaciones que manejan algún tipo de datos admiten la importación y exportación de CSV. Saber cómo manejar CSV, de una manera realista y práctica, será muy útil.
RELACIONADO: 9 ejemplos de scripts de Bash para comenzar en Linux