
GPU de la serie RTX 3000 de NVIDIA: esto es lo nuevo
Publicado: 2022-01-29
El 1 de septiembre de 2020, NVIDIA reveló su nueva línea de GPU para juegos: la serie RTX 3000, basada en su arquitectura Ampere. Discutiremos las novedades, el software impulsado por IA que viene con él y todos los detalles que hacen que esta generación sea realmente increíble.
Conozca las GPU de la serie RTX 3000

El principal anuncio de NVIDIA fueron sus nuevas y brillantes GPU, todas basadas en un proceso de fabricación personalizado de 8 nm, y todas aportan importantes aceleraciones tanto en la rasterización como en el rendimiento del trazado de rayos.
En el extremo inferior de la alineación, está el RTX 3070, que cuesta $ 499. Es un poco costosa para la tarjeta más barata presentada por NVIDIA en el anuncio inicial, pero es un robo absoluto una vez que se entera de que supera a la RTX 2080 Ti existente, una tarjeta de primera línea que se vende regularmente por más de $ 1400. Sin embargo, después del anuncio de NVIDIA, el precio de venta de terceros cayó, y una gran cantidad de ellos se vendieron por pánico en eBay por menos de $ 600.
No hay puntos de referencia sólidos a partir del anuncio, por lo que no está claro si la tarjeta es realmente "mejor" objetivamente que una 2080 Ti, o si NVIDIA está modificando un poco el marketing. Los puntos de referencia que se ejecutaron fueron en 4K y probablemente tenían RTX activado, lo que puede hacer que la brecha parezca más grande de lo que será en juegos puramente rasterizados, ya que la serie 3000 basada en Ampere tendrá un rendimiento dos veces mejor en el trazado de rayos que Turing. Pero, dado que el trazado de rayos ahora es algo que no afecta mucho el rendimiento y es compatible con la última generación de consolas, es un punto de venta importante tenerlo funcionando tan rápido como el buque insignia de la última generación por casi un tercio del precio.
Tampoco está claro si el precio se mantendrá así. Los diseños de terceros agregan regularmente al menos $ 50 a la etiqueta de precio, y con la alta demanda que probablemente será, no será sorprendente que se venda por $ 600 en octubre de 2020.
Justo por encima de eso está el RTX 3080 a $ 699, que debería ser el doble de rápido que el RTX 2080 y llegar entre un 25 y un 30% más rápido que el 3080.
Luego, en el extremo superior, el nuevo buque insignia es el RTX 3090, que es cómicamente enorme. NVIDIA lo sabe muy bien y se refirió a él como "BFGPU", que según la compañía significa "GPU Big Ferocious".

NVIDIA no mostró ninguna métrica de rendimiento directa, pero la compañía mostró que ejecuta juegos de 8K a 60 FPS, lo cual es realmente impresionante. Por supuesto, es casi seguro que NVIDIA esté usando DLSS para alcanzar esa marca, pero los juegos de 8K son juegos de 8K.
Por supuesto, eventualmente habrá un 3060 y otras variaciones de tarjetas más orientadas al presupuesto, pero generalmente llegan más tarde.
Para enfriar realmente las cosas, NVIDIA necesitaba un diseño de enfriador renovado. La 3080 tiene una potencia nominal de 320 vatios, que es bastante alta, por lo que NVIDIA optó por un diseño de doble ventilador, pero en lugar de colocar ambos ventiladores en la parte inferior, NVIDIA colocó un ventilador en el extremo superior, donde suele ir la placa posterior. El ventilador dirige el aire hacia arriba, hacia el enfriador de la CPU y la parte superior de la carcasa.

A juzgar por cuánto puede verse afectado el rendimiento por un mal flujo de aire en un caso, esto tiene mucho sentido. Sin embargo, la placa de circuito está muy estrecha debido a esto, lo que probablemente afectará los precios de venta de terceros.
DLSS: una ventaja de software
El trazado de rayos no es el único beneficio de estas nuevas tarjetas. Realmente, todo es un truco: la serie RTX 2000 y la serie 3000 no son mucho mejores para hacer el trazado de rayos real, en comparación con las generaciones anteriores de tarjetas. El trazado de rayos de una escena completa en un software 3D como Blender suele tardar unos segundos o incluso minutos por cuadro, por lo que la fuerza bruta en menos de 10 milisegundos está fuera de discusión.
Por supuesto, hay hardware dedicado para ejecutar cálculos de rayos, llamados núcleos RT, pero en gran medida, NVIDIA optó por un enfoque diferente. NVIDIA mejoró los algoritmos de eliminación de ruido, que permiten a las GPU generar una sola pasada muy barata que se ve terrible y, de alguna manera, a través de la magia de la IA, convertir eso en algo que un jugador quiere ver. Cuando se combina con técnicas tradicionales basadas en la rasterización, se convierte en una experiencia agradable mejorada con efectos de trazado de rayos.

Sin embargo, para hacer esto rápido, NVIDIA ha agregado núcleos de procesamiento específicos de IA llamados núcleos Tensor. Estos procesan todas las matemáticas necesarias para ejecutar modelos de aprendizaje automático y lo hacen muy rápidamente. Son un cambio de juego total para la IA en el espacio del servidor en la nube, ya que muchas empresas utilizan ampliamente la IA.
Más allá de la eliminación de ruido, el uso principal de los núcleos Tensor para los jugadores se denomina DLSS, o supermuestreo de aprendizaje profundo. Toma un marco de baja calidad y lo mejora a calidad nativa completa. Básicamente, esto significa que puedes jugar con velocidades de fotogramas de 1080p mientras miras una imagen de 4K.

Esto también ayuda bastante con el rendimiento del trazado de rayos: los puntos de referencia de PCMag muestran un RTX 2080 Super Running Control con calidad ultra, con todas las configuraciones de trazado de rayos al máximo. En 4K, tiene problemas con solo 19 FPS, pero con DLSS activado, obtiene 54 FPS mucho mejores. DLSS es un rendimiento gratuito para NVIDIA, posible gracias a los núcleos Tensor en Turing y Ampere. Cualquier juego que lo admita y esté limitado por GPU puede ver aceleraciones importantes solo con el software.
DLSS no es nuevo y se anunció como una característica cuando se lanzó la serie RTX 2000 hace dos años. En ese momento, era compatible con muy pocos juegos, ya que requería que NVIDIA entrenara y ajustara un modelo de aprendizaje automático para cada juego individual.
Sin embargo, en ese momento, NVIDIA lo reescribió por completo y llamó a la nueva versión DLSS 2.0. Es una API de propósito general, lo que significa que cualquier desarrollador puede implementarla y ya está siendo implementada por la mayoría de las versiones principales. En lugar de trabajar en un cuadro, toma datos de vectores de movimiento del cuadro anterior, de manera similar a TAA. El resultado es mucho más nítido que DLSS 1.0 y, en algunos casos, se ve mejor y más nítido incluso que la resolución nativa, por lo que no hay muchas razones para no activarlo.
Hay un problema: cuando se cambia de escena por completo, como en las cinemáticas, DLSS 2.0 debe renderizar el primer fotograma con una calidad del 50 % mientras espera los datos del vector de movimiento. Esto puede resultar en una pequeña caída en la calidad durante unos pocos milisegundos. Sin embargo, el 99 % de todo lo que vea se representará correctamente, y la mayoría de la gente no lo nota en la práctica.
RELACIONADO: ¿Qué es NVIDIA DLSS y cómo hará que Ray Tracing sea más rápido?
Arquitectura Ampere: Construida para IA
El amperio es rápido. Seriamente rápido, especialmente en los cálculos de IA. El núcleo RT es 1,7 veces más rápido que Turing y el nuevo núcleo Tensor es 2,7 veces más rápido que Turing. La combinación de los dos es un verdadero salto generacional en el rendimiento del trazado de rayos.

A principios de mayo, NVIDIA lanzó la GPU Ampere A100, una GPU para centros de datos diseñada para ejecutar IA. Con él, detallaron mucho de lo que hace que Ampere sea mucho más rápido. Para cargas de trabajo informáticas de alto rendimiento y centros de datos, Ampere es, en general, alrededor de 1,7 veces más rápido que Turing. Para el entrenamiento de IA, es hasta 6 veces más rápido.
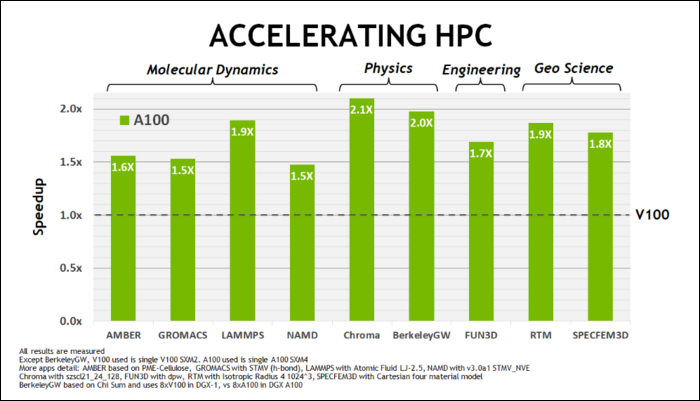
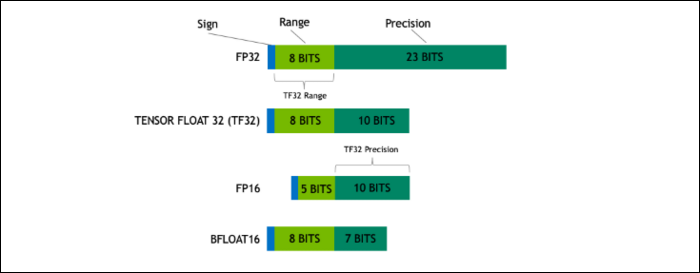
Con Ampere, NVIDIA está utilizando un nuevo formato de número diseñado para reemplazar el estándar de la industria "Floating-Point 32" o FP32, en algunas cargas de trabajo. Debajo del capó, cada número que procesa su computadora ocupa una cantidad predefinida de bits en la memoria, ya sea 8 bits, 16 bits, 32, 64 o incluso más. Los números que son más grandes son más difíciles de procesar, por lo que si puede usar un tamaño más pequeño, tendrá menos para procesar.
FP32 almacena un número decimal de 32 bits y usa 8 bits para el rango del número (cuán grande o pequeño puede ser) y 23 bits para la precisión. La afirmación de NVIDIA es que estos 23 bits de precisión no son del todo necesarios para muchas cargas de trabajo de IA, y puede obtener resultados similares y un rendimiento mucho mejor con solo 10 de ellos. Reducir el tamaño a solo 19 bits, en lugar de 32, marca una gran diferencia en muchos cálculos.
Este nuevo formato se llama Tensor Float 32, y los Tensor Cores en el A100 están optimizados para manejar el formato de tamaño extraño. Esto es, además de los encogimientos de dados y los aumentos en el recuento de núcleos, cómo obtienen la aceleración masiva 6x en el entrenamiento de IA.
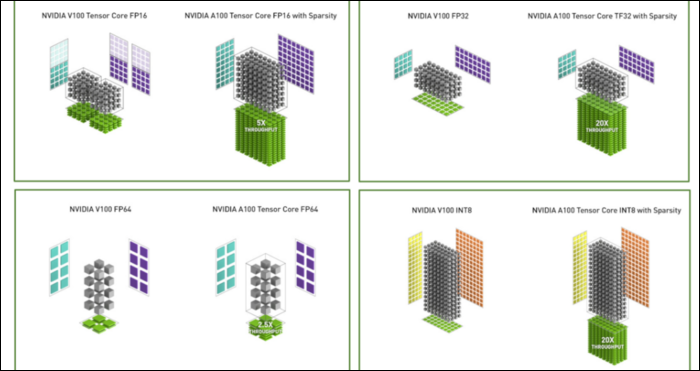
Además del nuevo formato de número, Ampere está experimentando importantes aceleraciones de rendimiento en cálculos específicos, como FP32 y FP64. Estos no se traducen directamente en más FPS para el profano, pero son parte de lo que hace que sea casi tres veces más rápido en general en las operaciones de Tensor.
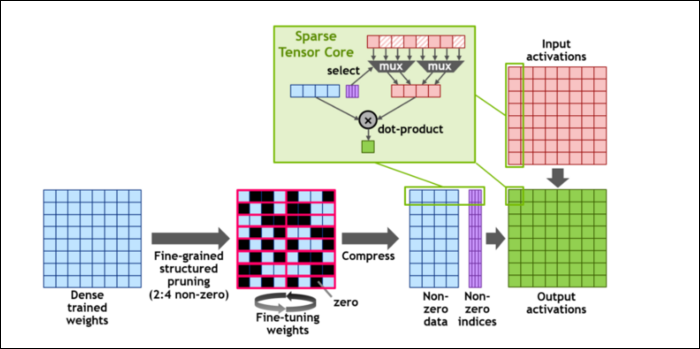
Luego, para acelerar aún más los cálculos, introdujeron el concepto de escasez estructurada de grano fino, que es una palabra muy elegante para un concepto bastante simple. Las redes neuronales funcionan con grandes listas de números, llamados pesos, que afectan la salida final. Cuantos más números haya que procesar, más lento será.
Sin embargo, no todos estos números son realmente útiles. Algunos de ellos son literalmente cero, y básicamente se pueden descartar, lo que conduce a aceleraciones masivas cuando puedes procesar más números al mismo tiempo. La dispersión esencialmente comprime los números, lo que requiere menos esfuerzo para hacer cálculos. El nuevo "Sparse Tensor Core" está diseñado para operar con datos comprimidos.
A pesar de los cambios, NVIDIA dice que esto no debería afectar en absoluto la precisión de los modelos entrenados.
Para los cálculos de Sparse INT8, uno de los formatos de números más pequeños, el rendimiento máximo de una sola GPU A100 supera los 1,25 PetaFLOP, una cifra asombrosamente alta. Por supuesto, eso es solo cuando se procesa un tipo específico de número, pero de todos modos es impresionante.