
cURL vs. wget en Linux: ¿Cuál es la diferencia?
Publicado: 2022-07-13
Si le preguntas a un grupo de usuarios de Linux con qué descargan archivos, algunos dirán wget y otros dirán cURL . ¿Cuál es la diferencia, y es uno mejor que el otro?
Comenzó con la conectividad
Los investigadores del gobierno comenzaron a conectar diferentes redes desde la década de 1960, dando lugar a redes interconectadas . Pero el nacimiento de Internet tal como lo conocemos se produjo el 1 de enero de 1983, cuando se implementó el protocolo TCP/IP. Este era el eslabón perdido. Permitió que computadoras y redes dispares se comunicaran usando un estándar común.
En 1991, CERN lanzó su software World Wide Web que habían estado usando internamente durante algunos años. El interés en esta superposición visual para Internet fue inmediato y generalizado. A finales de 1994 había 10.000 servidores web y 10 millones de usuarios.

Estos dos hitos, Internet y la web, representan caras muy diferentes de la conectividad. Pero también comparten muchas de las mismas funciones.
La conectividad significa precisamente eso. Te estás conectando a algún dispositivo remoto, como un servidor. Y te estás conectando porque hay algo en él que necesitas o quieres. Pero, ¿cómo recupera ese recurso alojado de forma remota en su computadora local, desde la línea de comandos de Linux?
En 1996, nacieron dos utilidades que le permiten descargar recursos alojados de forma remota. Son wget , que se lanzó en enero, y cURL , que se lanzó en diciembre. Ambos operan en la línea de comandos de Linux. Ambos se conectan a servidores remotos y ambos recuperan cosas para usted.
Pero este no es solo el caso habitual de Linux que proporciona dos o más herramientas para hacer el mismo trabajo. Estas utilidades tienen diferentes propósitos y diferentes especialidades. El problema es que son lo suficientemente similares como para causar confusión sobre cuál usar y cuándo.
Considere dos cirujanos. Probablemente no desee que un cirujano oftalmólogo realice su cirugía de derivación cardíaca, ni desea que el cirujano cardíaco realice su operación de cataratas. Sí, ambos son profesionales médicos altamente calificados, pero eso no significa que sean reemplazos directos el uno del otro.
Lo mismo es cierto para wget y cURL .
Propósitos diferentes, características diferentes, algunas superposiciones
La "w" en el comando wget es un indicador de su propósito previsto. Su objetivo principal es descargar páginas web, o incluso sitios web completos. Su página de man lo describe como una utilidad para descargar archivos de la Web utilizando los protocolos HTTP, HTTPS y FTP.
Por el contrario, cURL funciona con 26 protocolos, incluidos SCP, SFTP y SMSB, así como HTTPS. Su página de man dice que es una herramienta para transferir datos hacia o desde un servidor. No está diseñado para trabajar con sitios web, específicamente. Está diseñado para interactuar con servidores remotos, utilizando cualquiera de los muchos protocolos de Internet que admite.
Entonces, wget está predominantemente centrado en el sitio web, mientras que cURL es algo que opera en un nivel más profundo, en el nivel de Internet simple.
wget puede recuperar páginas web y puede navegar de forma recursiva por estructuras de directorios completas en servidores web para descargar sitios web completos. También puede ajustar los enlaces en las páginas recuperadas para que apunten correctamente a las páginas web en su computadora local y no a sus contrapartes en el servidor web remoto.
cURL le permite interactuar con el servidor remoto. Puede cargar archivos y recuperarlos. cURL funciona con proxies SOCKS4 y SOCKS5, y HTTPS para el proxy. Admite la descompresión automática de archivos comprimidos en los formatos GZIP, BROTLI y ZSTD. cURL también te permite descargar múltiples transferencias en paralelo.
La superposición entre ellos es que wget y cURL le permiten recuperar páginas web y usar servidores FTP.
Es solo una métrica aproximada, pero puede obtener una idea de los conjuntos de funciones relativas de las dos herramientas al observar la longitud de sus páginas de man . En nuestra máquina de prueba, la página del manual para wget tiene 1433 líneas. La página del man para cURL tiene 5296 líneas.

Un vistazo rápido a wget
Debido a que wget es parte del proyecto GNU, debería encontrarlo preinstalado en todas las distribuciones de Linux. Su uso es sencillo, sobre todo para sus usos más comunes: descargar páginas web o archivos.
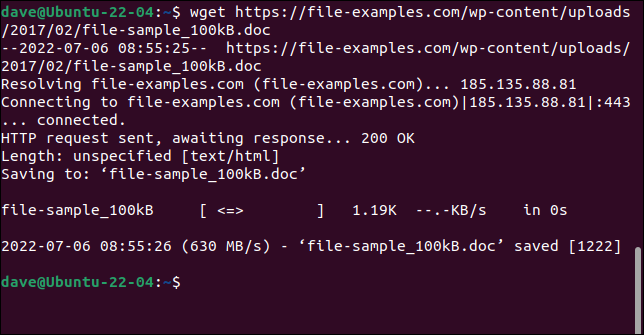
Simplemente use el comando wget con la URL de la página web o el archivo remoto.
wget https://file-examples.com/wp-content/uploads/2017/02/file-sample_100kB.doc

El archivo se recupera y se guarda en su computadora con su nombre original.
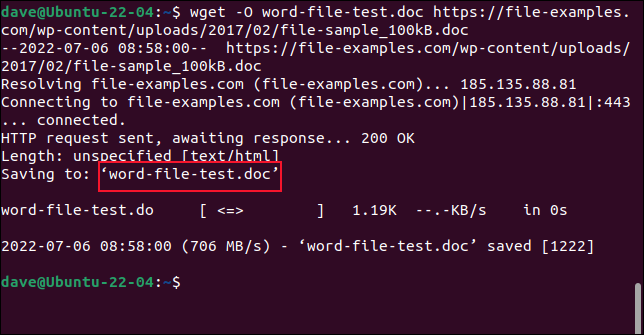
Para que el archivo se guarde con un nuevo nombre, utilice la opción -O (documento de salida).
wget -O word-file-test.doc https://file-examples.com/wp-content/uploads/2017/02/file-sample_100kB.doc

El archivo recuperado se guarda con nuestro nombre elegido.
No utilice la opción -O cuando esté recuperando sitios web. Si lo hace, todos los archivos recuperados se adjuntan en uno.
Para recuperar un sitio web completo, use la opción -m (espejo) y la URL de la página de inicio del sitio web. También querrá usar --page-requisites para asegurarse de que todos los archivos de soporte necesarios para representar correctamente las páginas web también se descarguen. La opción --convert-links ajusta los enlaces en el archivo recuperado para apuntar a los destinos correctos en su computadora local en lugar de ubicaciones externas en el sitio web.
RELACIONADO: Cómo usar wget, la herramienta de descarga de línea de comandos definitiva
Un vistazo rápido a cURL
cURL es un proyecto independiente de código abierto. Está preinstalado en Manjaro 21 y Fedora 36, pero tuvo que instalarse en Ubuntu 21.04.
Este es el comando para instalar cURL en Ubuntu.
sudo apt instalar rizo

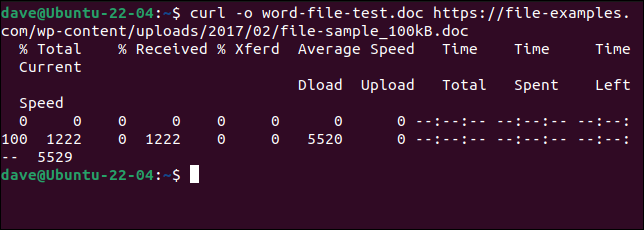
Para descargar el mismo archivo que hicimos con wget y guardarlo con el mismo nombre, necesitamos usar este comando. Tenga en cuenta que la opción -o (salida) está en minúsculas con cURL .
curl -o word-file-test.doc https://file-examples.com/wp-content/uploads/2017/02/file-sample_100kB.doc

El archivo se descarga para nosotros. Se muestra una barra de progreso ASCII durante la descarga.
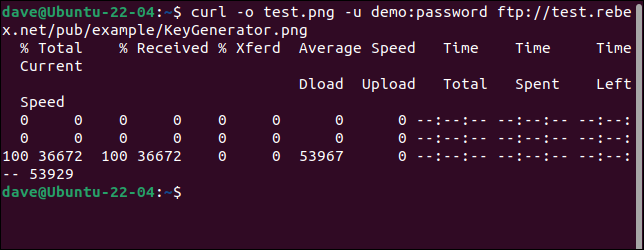
Para conectarse a un servidor FTP y descargar un archivo, use la opción -u (usuario) y proporcione un par de nombre de usuario y contraseña, como este:
curl -o test.png -u demostración:contraseña ftp://test.rebex.net/pub/example/KeyGenerator.png

Esto descarga y cambia el nombre de un archivo desde un servidor FTP de prueba.
RELACIONADO: Cómo usar curl para descargar archivos desde la línea de comandos de Linux
no hay mejor
Es imposible responder "¿Cuál debo usar?" sin preguntar "¿Qué estás tratando de hacer?"
Una vez que comprenda lo que hacen wget y cURL , se dará cuenta de que no están en competencia. No satisfacen el mismo requisito y no intentan proporcionar la misma funcionalidad.
La descarga de páginas web y sitios web es donde radica la superioridad de wget . Si eso es lo que estás haciendo, usa wget . Para cualquier otra cosa (cargar, por ejemplo, o usar cualquiera de la multitud de otros protocolos), use cURL .