
Cómo comparar archivos binarios en Linux
Publicado: 2022-08-20
¿Cómo puede verificar si dos binarios de Linux son iguales? Si son archivos ejecutables, cualquier diferencia podría significar un comportamiento no deseado o malicioso. Esta es la forma más fácil de verificar si difieren.
Comparando archivos binarios
Linux es rico en formas de comparar y analizar archivos de texto. El comando diff comparará dos archivos por usted y resaltará las diferencias. Incluso puede proporcionar algunas líneas a cada lado de los cambios para brindar algo de contexto en torno a las líneas modificadas. Y el comando colordiff agrega color para facilitar aún más el análisis visual de las diferencias.
Los desarrolladores y autores usan diff para resaltar las diferencias entre las diferentes versiones de los archivos de código fuente del programa o los borradores de texto. Es rápido y fácil, y no necesita conocimientos técnicos para ver las diferencias entre las cadenas de texto.
En el mundo de los archivos binarios, las cosas no son tan simples. Los archivos binarios no están compuestos de texto sin formato. Están formados por muchos bytes que contienen valores numéricos. Si se trata de un archivo comprimido, como un archivo TAR o un archivo ZIP, esos valores representan los archivos comprimidos que se almacenan dentro del archivo, junto con las tablas de símbolos que se requieren para la descompresión y extracción de los archivos.

Si el archivo binario es un archivo ejecutable, los valores numéricos de los bytes del archivo se interpretan como instrucciones de código de máquina para la CPU, metadatos, etiquetas o datos codificados. Es probable que los cambios en un archivo binario o un archivo de biblioteca produzcan diferencias en el comportamiento cuando el binario se ejecuta o es utilizado por otra aplicación.
Es fácil falsificar la fecha y hora de creación o modificación de un archivo. Eso significa que podría haber dos versiones de un archivo que tengan el mismo nombre, tamaño de archivo (si los cambios reemplazan el contenido existente byte por byte) y sellos de fecha. Y, sin embargo, uno de los archivos puede haber sido alterado.
Algoritmos hash seguros
Un algoritmo hash seguro es un algoritmo basado en matemáticas. Crea un valor de 64 bits escaneando todos los bytes en un archivo y aplicándoles una transformación matemática para generar el valor hash. En cualquier día, el mismo archivo siempre producirá el mismo hash. Incluso una diferencia de un byte dará como resultado un hash radicalmente diferente.
A menudo verá el hash de un archivo que se muestra en su página de descarga. Debe generar un hash para el archivo una vez que lo haya descargado. Si es diferente del hash que se muestra en la página web, sabrá que el archivo está comprometido. O bien ha sido manipulado y sustituido por el archivo original (para que las personas descarguen el archivo contaminado) o se ha corrompido en tránsito.
En nuestra computadora de prueba, tenemos dos copias del mismo archivo, una biblioteca compartida. Se ha cambiado el nombre de los archivos para que puedan estar en el mismo directorio. En teoría, estos archivos deberían ser iguales. Después de todo, se supone que son la misma versión de la biblioteca compartida.
ls -l *.so

Los archivos tienen el mismo tamaño, las mismas marcas de fecha y las mismas marcas de tiempo. Para el observador casual, parecerán ser iguales. Usemos el comando sha256sum y generemos un hash para cada archivo.
sha256sum archivo_binario1.so
sha256sum archivo_binario2.so
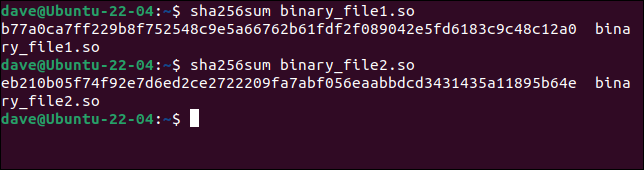
Los hashes son completamente diferentes, lo que indica claramente que existen diferencias entre los dos archivos. Si el sitio web muestra el hash del archivo original, puede descartar el archivo que no coincide.
Encontrar las diferencias
Si desea ver los cambios, también hay formas de hacerlo. No necesita poder descompilar el archivo, ni comprender el código ensamblador o máquina solo para ver las modificaciones. Comprender qué significan esos cambios y cuál es su propósito, por supuesto, requeriría un conocimiento técnico más profundo. Pero el simple hecho de saber cuán sustanciales son los cambios puede ser indicativo de lo que sucedió con el archivo.
Si usamos diff en los dos archivos binarios, obtendremos una respuesta un poco decepcionante.
diff archivo_binario1.so archivo_binario2.so

Ya sabíamos que los archivos eran diferentes. Probemos cmp .
cmp archivo_binario1.so archivo_binario2.so

Esto nos dice un poco más. El primer byte que difiere entre los dos archivos es el byte número 13451. Es decir, contado desde el inicio del archivo binario, el byte 13451 es diferente en los dos archivos binarios. Entonces 13451 es el desplazamiento de la primera diferencia, desde el inicio del archivo.
Por casualidad, a lo largo del archivo, habrá bytes que contengan el valor hexadecimal de 0x10. Este es el valor que utiliza Linux en los archivos de texto como carácter de fin de línea. El comando cmp encontró 131 bytes con este valor entre el inicio del archivo binario y la ubicación de la primera diferencia. Entonces cree que está en la línea 132. Realmente no significa nada en este contexto.
Si añadimos la opción -l (verbose) empezaremos a obtener información útil.
cmp -l archivo_binario1.so archivo_binario2.so
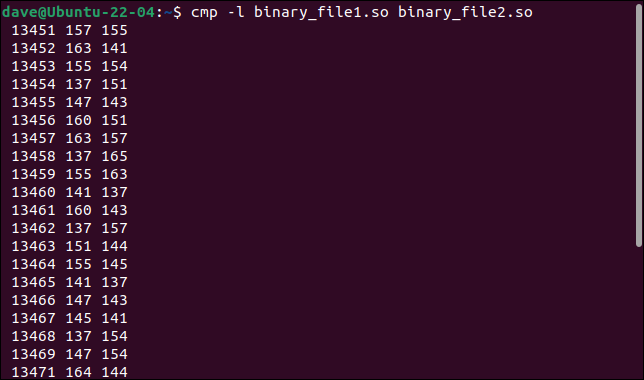

Se enumeran todos los bytes diferentes. Se muestran el número de byte o el desplazamiento, el valor del primer archivo y el valor del segundo archivo, con un byte por línea de salida.
Los valores de los bytes se muestran en octal, en lugar del formato hexadecimal habitual que se usa con los archivos binarios. No obstante, hemos aprendido algo más. Todos los bytes modificados están en una secuencia continua. Sus compensaciones se incrementan en uno por cada byte.
La herramienta hexdump un archivo binario en la ventana del terminal. Si usamos la opción -C (canónica), la salida mostrará en cada línea el desplazamiento, los valores de 16 bytes en ese desplazamiento y, si hay uno, la representación ASCII de los valores de byte.
hexdump -C archivo_binario1.so
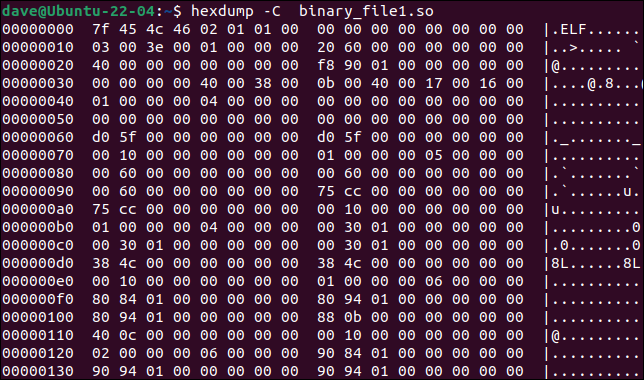
Podemos usar la salida de hexdump como entrada para diff , dejando que diff funcione como si estuviera leyendo dos archivos de texto.
diff <(hexdump archivo_binario1.so) <(hexdump archivo_binario2.so)
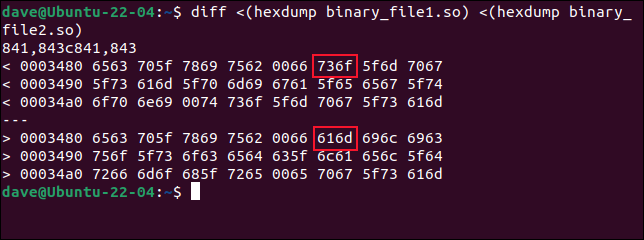
diff encuentra las líneas que son diferentes y muestra los valores de bytes hexadecimales del primer archivo sobre los valores del segundo archivo. El desplazamiento de la primera línea es 0x3480 o 13440 en decimal. Anteriormente, cmp nos dijo que el primer cambio ocurrió en el byte 13451, que es 0x348B. Eso realmente coincide con lo que vemos aquí.
La salida de diff está en bloques de dos bytes. El primer par de bytes son los bytes 0 y 1 del desplazamiento de 0x3480, el segundo bloque contiene los bytes 2 y 3 del desplazamiento. El bloque 6 contendrá los bytes 0xA y 0xB, o 10 y 11 en decimal. Esos son los bytes 13450 y 13451. Y podemos ver que son los primeros bytes que difieren. Los primeros cinco pares de bytes son iguales en ambos archivos.
Sin embargo, debido a que diff cuenta desde la base cero, lo que cmp llama 13451 será el byte 13540 para diff . Y para hacer las cosas aún más confusas, el orden de los bytes en cada bloque de dos bytes se invierte mediante diff . Los bytes se enumeran en este orden: 1 y 0, 3 y 2, 5 y 4, 7 y 6, y así sucesivamente.
El comando también es costoso desde el punto de vista computacional: dos hexdumps y una diff , todo a la vez, especialmente si los archivos que se comparan son grandes.
Pero si hexdump -C puede enviar una versión ASCII del archivo binario a la ventana del terminal, ¿por qué no redirigimos la salida a archivos de texto y luego comparamos esos dos archivos de texto con diff ?
hexdump -C archivo_binario1.so > binario1.txt
hexdump -C archivo_binario2.so > binario2.txt
diff binario1.txt binario2.txt
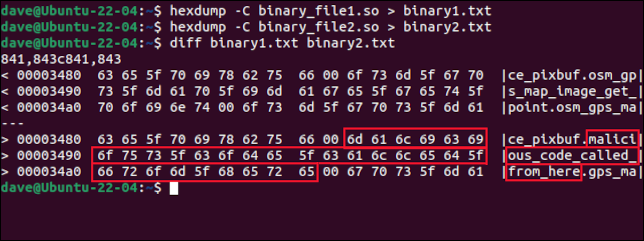
La diferencia entre los dos archivos se muestra en dos breves extractos. Hay una representación ASCII junto a ellos. Habrá un par de extractos para cada diferencia entre los archivos. En este ejemplo, solo hay una diferencia.
Eso está muy bien, pero ¿no sería genial si hubiera algo que hiciera todo eso por ti?
VBinDif
El programa VBinDiff se puede instalar desde los repositorios habituales de todas las distribuciones principales. Para instalarlo en Ubuntu, use este comando:
sudo apt install vbindiff

En Fedora, debe escribir:
sudo dnf instalar vbindiff

Los usuarios de Manjaro necesitan usar pacman .
sudo pacman -Sy vbindiff

Para usar el programa, pase el nombre de los dos archivos binarios en la línea de comando.
vbindiff archivo_binario1.so archivo_binario2.so

Se abre la aplicación basada en terminal, que muestra ambos archivos en una vista de desplazamiento.
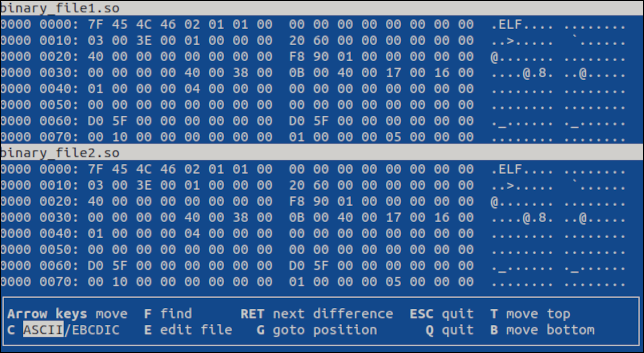
Puede usar la rueda de desplazamiento del mouse o las teclas "Flecha arriba", "Flecha abajo", "Inicio", "Fin", "Re Pág" y "Re Pág" para moverse por los archivos. Ambos archivos se desplazarán.
Presiona la tecla "Enter" para saltar a la primera diferencia. La diferencia se destaca en ambos archivos.
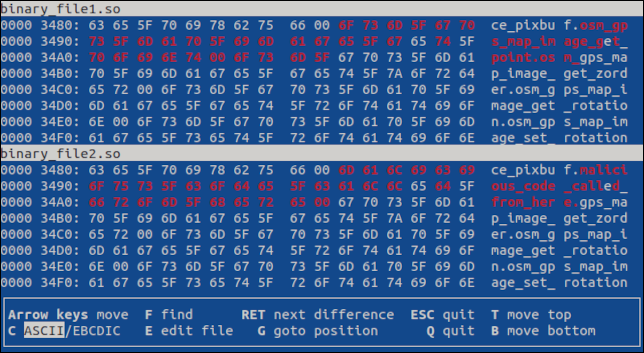
Si hubiera más diferencias, presionar "Enter" mostraría la siguiente diferencia. Presionando “q” o “Esc” saldrá del programa.
¿Cual es la diferencia?
Si está trabajando en una computadora que pertenece a otra persona y no puede instalar ningún paquete, puede usar cmp , diff y hexdump . Si necesita capturar la salida para su posterior procesamiento, estas son las herramientas que debe usar también.
Pero si tiene permiso para instalar paquetes, VBinDiff hace que su flujo de trabajo sea más fácil y rápido. Y, de hecho, usar VBinDiff con un solo archivo binario es una forma fácil y conveniente de navegar a través de archivos binarios, lo cual es una buena ventaja.
RELACIONADO: Cómo mirar dentro de los archivos binarios desde la línea de comandos de Linux