
Linuxでwcコマンドを使用する方法
公開: 2022-07-23
ファイル内の行数、単語数、およびバイト数を数えることは便利ですが、Linux wcコマンドの真の柔軟性は、他のコマンドを操作することから得られます。 見てみましょう。
wcコマンドとは何ですか?
wcコマンドは小さなアプリケーションです。 これはLinuxのコアユーティリティの1つであるため、インストールする必要はありません。 それはすでにあなたのLinuxコンピュータにあります。
あなたはそれが何をするのかをほんの少しの言葉で説明することができます。 ファイルまたは選択したファイルの行、単語、バイトをカウントし、その結果をターミナルウィンドウに出力します。 また、STDINストリームから入力を受け取ることもできます。つまり、処理するテキストをパイプで送ることができます。 これは、 wcが実際に価値を付加し始めるところです。

これは、「1つのことを実行してそれをうまく実行する」というLinuxのマントラの良い例です。 パイプ入力を受け入れるため、マルチコマンドの呪文で使用できます。 後で説明するように、この小さなスタンドアロンユーティリティは、実際には優れたチームプレーヤーです。
私がwcを使用する1つの方法は、私が作成している複雑なコマンドまたはエイリアスのプレースホルダーとして使用することです。 完成したコマンドが破壊的でファイルを削除する可能性がある場合、私はしばしばwcを実際の危険なコマンドの代用として使用します。
そうすることで、コマンドの開発中に、各ファイルが期待どおりに処理されているという視覚的なフィードバックを得ることができます。 構文に取り組んでいる間、何か悪いことが起こる可能性はありません。
wcと同じくらい単純ですが、知っておく必要のある小さな癖がまだいくつかあります。
wc入門
wcを使用する最も簡単な方法は、コマンドラインでテキストファイルの名前を渡すことです。
wc lorem.txt

これにより、 wcはファイルをスキャンし、行、ワード、およびバイトをカウントして、ターミナルウィンドウに書き込みます。
単語は空白で囲まれたものと見なされます。 それらが実際の言語からの単語であるかどうかは関係ありません。 ファイルに「frdglkj」しか含まれていない場合でも、3ワードとしてカウントされます。
行は、キャリッジリターンまたはファイルの終わりのいずれかで終了する文字のシーケンスです。 行がエディタまたはターミナルウィンドウで折り返されるかどうかは関係ありませんwcがキャリッジリターンまたはファイルの終わりに遭遇するまで、それは同じ行のままです。
最初の例では、ファイル全体で1行が見つかりました。 「lorem.txt」ファイルの内容は次のとおりです。
cat lorem.txt
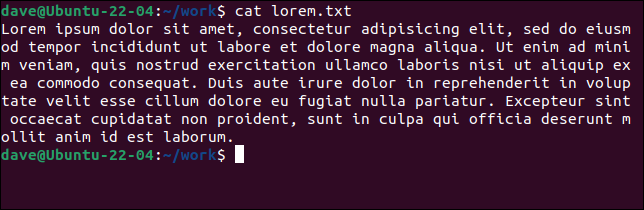
キャリッジリターンがないため、これらすべてが1行としてカウントされます。 これを別のファイル「lorem2.txt」と比較し、 wcがそれをどのように解釈するかを確認してください。
wc lorem2.txt
猫lorem2.txt
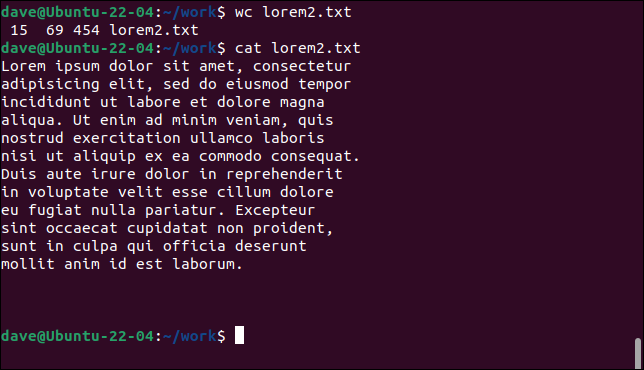
今回は、特定のポイントで新しい行を開始するためにキャリッジリターンがテキストに挿入されているため、 wcは15行をカウントします。 ただし、テキストを含む行を数えると、12行しかないことがわかります。
他の3行は、ファイルの最後の空白行です。 これらにはキャリッジリターンのみが含まれます。 これらの行にテキストがない場合でも、新しい行が開始されたため、 wcはそれらをそのようにカウントします。
必要な数のファイルをwcに渡すことができます。
wc lorem.txt lorem2.txt
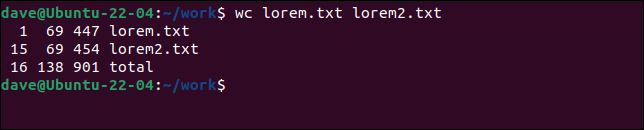
個々のファイルの統計とすべてのファイルの合計を取得します。
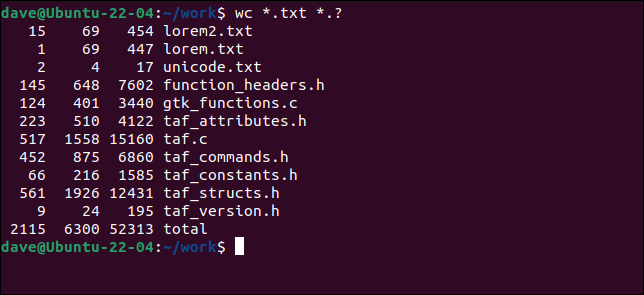
ワイルドカードを使用して、明示的に名前が付けられたファイルの代わりに一致するファイルを選択することもできます。
wc * .txt *。?
コマンドラインオプション
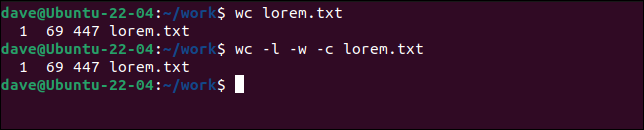
デフォルトでは、 wcは各ファイルの行、単語、およびバイトを表示します。 これは、 -l (行) -w (ワード)および-c (バイト)オプションを使用するのと同じです。
wc lorem.txt
wc -l -w -c lorem.txt
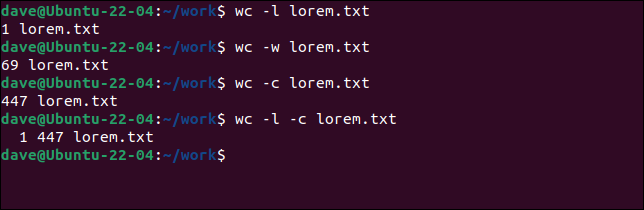
見たい図の組み合わせを指定できます。
wc -l lorem.txt wc -w lorem.txt wc -c lorem.txt wc -l -c lorem.txt
-c (バイト)オプションによって生成された最後の数字に特別な注意を払う必要があります。 多くの人がこれを文字数と間違えます。 実際にはバイトをカウントします。 文字数とバイト数は同じかもしれません。 しかしいつもではない。
「unicode.txt」というファイルの内容を見てみましょう。
cat unicode.txt

3つの単語と非ラテンアルファベット文字があります。 wcにデフォルト設定のbytesでファイルを処理させ、再度処理しますが、 -m (文字)オプションを使用して文字を要求します。
wc unicode.txt
wc -l -w -m unicode.txt
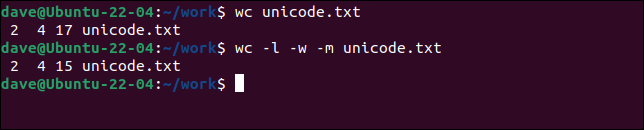
文字よりもバイト数が多い。
ファイルの16進ダンプを見て、何が起こっているのかを見てみましょう。 hexdumpコマンドの-C (正規)オプションは、ファイル内のバイトを16行で表示し、対応するプレーンASCII(存在する場合)を行の最後に表示します。 対応するASCII文字がない場合は、ピリオド「 . 代わりに」が表示されます。

hexdump -C unicode.txt
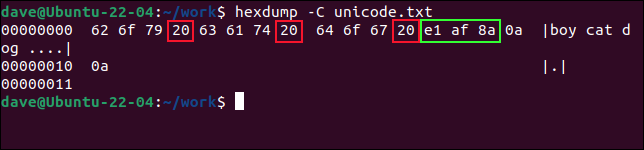
ASCIIでは、16進値0x20はスペース文字を表します。 左から3つの値を数えると、次の値はスペース文字であることがわかります。 したがって、これらの最初の3つの値0x62 、および0x6fは、「男の子」の文字を0x79ます。
0x20を0x61 0x63および0x74 )が表示されます。 これらは「猫」を綴っています。 次のスペース文字を飛び越えると、「犬」の文字にさらに3つの値が表示されます。 これらは、 0x64 、および0x5f 0x67 。
「犬」という単語のすぐ後ろに、スペース文字0x20と、さらに5つの16進値が表示されます。 最後の2つは、キャリッジリターン0x0aです。
他の3バイトは、緑色で鳴らした非ラテン文字を表します。 これはUnicode文字であり、エンコードには3バイトかかります。 これらは、 0xe1 、および0x8a 0xaf 。
したがって、何を数えているのかを確認し、バイトと文字が同じである必要はないことを確認してください。 通常、バイト数を数えると、ファイル内に実際に何があるかがわかるため、より便利です。 文字で数えると、ファイルの内容で表されるものの数がわかります。
関連: ANSIやUnicodeのような文字エンコードとは何ですか?また、それらはどのように異なりますか?
ファイルからファイル名を取得する
wcにファイル名を提供する別の方法があります。 ファイル名をファイルに入れて、そのファイルの名前をwcに渡すことができます。 ファイルを開き、ファイル名を抽出して、コマンドラインで渡されたかのように処理します。 これにより、ファイル名の任意のコレクションを保存して再利用できます。
しかし、落とし穴があり、それは大きな問題です。 ファイル名は、キャリッジリターンで終了するのではなく、 nullで終了する必要があります。 つまり、各ファイル名の後に、通常のキャリッジリターンバイト0x0aではなく、 0x00のヌルバイトが必要です。
エディタを開いて、この形式のファイルを作成することはできません。 通常、このようなファイルは他のプログラムによって生成されます。 しかし、あなたがそのようなファイルを持っているなら、これはあなたがそれを使う方法です。
これがファイル名を含むファイルです。 lessで開くと、nullバイトを示すためにlessが使用する奇妙な「 ^@ 」文字が表示されます。
少ないsource-files-list.txt

wcでファイルを使用するには、 --files0-from (入力の読み取り)オプションを使用して、ファイル名を含むファイルの名前を渡す必要があります。
wc --- files0-from = source-files-list.txt
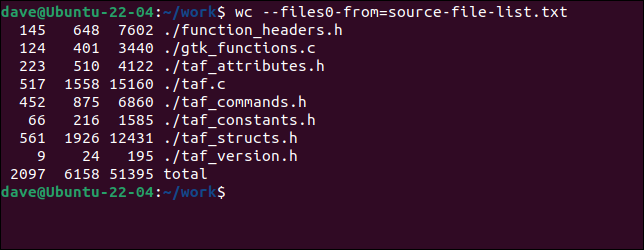
ファイルは、コマンドラインで提供された場合とまったく同じように処理されます。
wcへの配管入力
入力をwcに送信するための、はるかに一般的で柔軟性があり、生産的な方法は、他のコマンドからの出力をwcにパイプすることです。 これはechoコマンドで実証できます。
エコー「私のためにこれを数えなさい」| トイレ
echo-e"これを数えます\n私のために"| トイレ
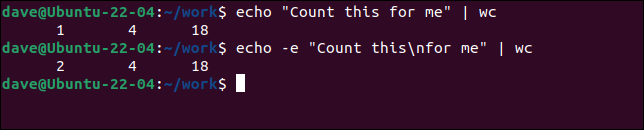
2番目のechoコマンドは、 -e (エスケープ文字)オプションを使用して、「 \n 」改行フォーマットコードのようなエスケープされたシーケンスを許可します。 これにより、新しい行が挿入され、 wcは入力を2行として認識します。
これは、入力を一方から他方に送るコマンドのカスケードです。
検索./*-typef | rev | カット-d'。' -f1 | rev | 並べ替え| uniq
- findは、現在のディレクトリから開始して、ファイル(
type -f)を再帰的に検索します。revはファイル名を逆にします。 - cutは、フィールド区切り文字をピリオド「」として定義することにより、最初のフィールド(
-f1)を抽出し.」と、反転したファイル名の「先頭」から最初のピリオドまで読み取ります。 これでファイル拡張子が抽出されました。 - revは、抽出された最初のフィールドを反転します。
- sortは、アルファベットの昇順でそれらをソートします。
- uniqは、ターミナルウィンドウへの一意のエントリを一覧表示します。
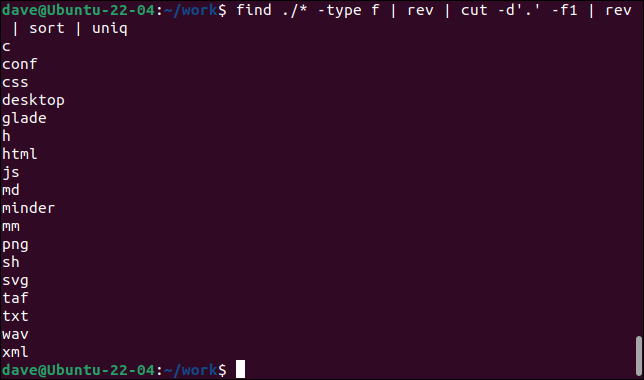
このコマンドは、現在のディレクトリとサブディレクトリにあるすべての一意のファイル拡張子を一覧表示します。
uniqコマンドに-c (count)オプションを追加すると、各拡張タイプの出現回数がカウントされます。 ただし、異なる一意のファイル拡張子がいくつあるかを知りたい場合は、行の最後のコマンドとしてwcを削除し、 -l (行)オプションを使用できます。
検索./*-typef | rev | カット-d'。' -f1 | rev | 並べ替え| uniq | wc -l

関連: Linuxのcutコマンドの使用方法
そして最後に
これがwcがあなたのためにできる最後のトリックです。 ファイル内の最長行の長さがわかります。 悲しいことに、それはそれがどの行であるかを教えてくれません。 それはあなたに長さを与えるだけです。
wc -L taf.c

ただし、タブは8つのスペースとしてカウントされることに注意してください。 私のエディターで見ると、その行の先頭に3つの2スペースタブがあります。 実際の長さは124文字です。 そのため、報告された数値は人為的に拡大されています。
私はこの機能を塩の大きなピンチで扱います。 そしてそれは私がそれを使用しないことを意味します。 その出力は誤解を招く可能性があります。
その癖にもかかわらず、 wcは、ファイル内の単語だけでなく、あらゆる種類の値をカウントする必要があるときに、パイプされたコマンドにドロップするための優れたツールです。
関連:知っておくべき37の重要なLinuxコマンド