
NVIDIAのRTX3000シリーズGPU:最新情報
公開: 2022-01-29
2020年9月1日、NVIDIAはゲーム用GPUの新しいラインナップであるRTX3000シリーズをAmpereアーキテクチャに基づいて発表しました。 何が新しく、それに付属するAIを利用したソフトウェア、そしてこの世代を本当に素晴らしいものにするすべての詳細について説明します。
RTX3000シリーズGPUに対応

NVIDIAの主な発表は、すべてカスタム8 nm製造プロセスに基づいて構築され、ラスタライズとレイトレーシングの両方のパフォーマンスを大幅に高速化した、光沢のある新しいGPUでした。
ラインナップのローエンドには、499ドルのRTX3070があります。 最初の発表でNVIDIAが発表した最も安価なカードとしては少し高価ですが、定期的に1400ドル以上で販売されている最上位のカードである既存のRTX 2080 Tiを打ち負かすことを知ったら、絶対に盗みます。 しかし、NVIDIAの発表後、サードパーティの販売価格は下落し、その多くがeBayで600ドル未満でパニックになりました。
発表の時点で確固たるベンチマークはないため、カードが2080 Tiよりも客観的に「優れている」のか、それともNVIDIAがマーケティングを少しひねっているのかは不明です。 実行されているベンチマークは4Kであり、RTXがオンになっている可能性があります。これにより、Ampereベースの3000シリーズはレイトレーシングでTuringの2倍以上のパフォーマンスを発揮するため、純粋にラスタライズされたゲームよりもギャップが大きく見える可能性があります。 しかし、レイトレーシングはパフォーマンスをそれほど損なうものではなく、最新世代のコンソールでサポートされているため、前世代の主力製品とほぼ3分の1の価格で実行できることが大きなセールスポイントです。
価格がそのようにとどまるかどうかも不明です。 サードパーティの設計では、定期的に少なくとも50ドルが値札に追加されます。需要が非常に高くなる可能性があるため、2020年10月に600ドルで販売されるのは当然のことです。
そのすぐ上に699ドルのRTX3080があります。これはRTX2080の2倍の速度で、3080よりも約25〜30%高速です。
そして、トップエンドでは、新しいフラッグシップはコミカルに巨大なRTX3090です。 NVIDIAはよく知っており、これを「BFGPU」と呼んでいます。これは、「BigFerociousGPU」の略であると同社は言います。

NVIDIAは直接的なパフォーマンス指標を披露しませんでしたが、同社は60FPSで8Kゲームを実行していることを示しました。これは非常に印象的です。 確かに、NVIDIAはほぼ確実にDLSSを使用してその目標を達成していますが、8Kゲームは8Kゲームです。
もちろん、最終的には3060やその他の予算重視のカードのバリエーションがありますが、通常は後で登場します。
実際に物事を冷やすために、NVIDIAは改良されたクーラーデザインを必要としていました。 3080の定格は320ワットで、かなり高いため、NVIDIAはデュアルファン設計を選択しましたが、両方のファンvwinfを下部に配置する代わりに、NVIDIAはバックプレートが通常配置される上部にファンを配置しました。 ファンは空気を上向きにCPUクーラーとケースの上部に向けます。

ケース内の空気の流れが悪いとパフォーマンスがどの程度影響を受けるかを判断すると、これは完全に理にかなっています。 ただし、このため回路基板は非常に窮屈であり、サードパーティの販売価格に影響を与える可能性があります。
DLSS:ソフトウェアの利点
これらの新しいカードの利点はレイトレーシングだけではありません。 実際、これはちょっとしたハックです。RTX2000シリーズと3000シリーズは、旧世代のカードと比較して、実際のレイトレーシングを行うのにそれほど優れていません。 Blenderのような3Dソフトウェアでシーン全体をレイトレーシングするには、通常、フレームごとに数秒または数分かかるため、10ミリ秒未満でブルートフォースすることは問題外です。
もちろん、RTコアと呼ばれる光線計算を実行するための専用ハードウェアがありますが、主にNVIDIAは別のアプローチを選択しました。 NVIDIAは、ノイズ除去アルゴリズムを改善しました。これにより、GPUは、ひどく見える非常に安価なシングルパスをレンダリングし、どういうわけか、AIマジックを通じて、ゲーマーが見たいものに変えることができます。 従来のラスタライズベースの手法と組み合わせると、レイトレーシング効果によって強化された快適なエクスペリエンスが実現します。

ただし、これを高速に行うために、NVIDIAはTensorコアと呼ばれるAI固有の処理コアを追加しました。 これらは、機械学習モデルを実行するために必要なすべての数学を処理し、それを非常に迅速に実行します。 AIは多くの企業で広く使用されているため、これらはクラウドサーバースペースにおけるAIの完全なゲームチェンジャーです。
ノイズ除去以外に、ゲーマー向けのTensorコアの主な用途は、DLSSまたはディープラーニングスーパーサンプリングと呼ばれます。 低品質のフレームを取り込み、フルネイティブ品質にアップスケールします。 これは基本的に、4K画像を見ながら1080pレベルのフレームレートでゲームできることを意味します。

これは、レイトレーシングのパフォーマンスにもかなり役立ちます。PCMagのベンチマークは、すべてのレイトレーシング設定が最大に調整された、RTX2080スーパーランニングコントロールを超高品質で示しています。 4Kでは、わずか19 FPSで苦労しますが、DLSSをオンにすると、54FPSがはるかに向上します。 DLSSはNVIDIAの無料パフォーマンスであり、TuringとAmpereのTensorコアによって可能になりました。 それをサポートし、GPUに制限されているゲームは、ソフトウェアだけで深刻なスピードアップを見ることができます。
DLSSは新しいものではなく、2年前にRTX2000シリーズが発売されたときに機能として発表されました。 当時、NVIDIAは個々のゲームごとに機械学習モデルをトレーニングおよび調整する必要があったため、サポートされていたゲームはごくわずかでした。
しかし、その時、NVIDIAはそれを完全に書き直し、新しいバージョンのDLSS2.0を呼び出しました。 これは汎用APIです。つまり、すべての開発者が実装でき、ほとんどのメジャーリリースですでに採用されています。 TAAと同様に、1つのフレームで作業するのではなく、前のフレームから動きベクトルデータを取り込みます。 結果はDLSS1.0よりもはるかにシャープであり、場合によっては、ネイティブ解像度よりも実際に見栄えが良く、シャープに見えるため、オンにしない理由はあまりありません。
1つの落とし穴があります。カットシーンのようにシーンを完全に切り替える場合、DLSS 2.0は、モーションベクトルデータを待機している間、最初のフレームを50%の品質でレンダリングする必要があります。 これにより、数ミリ秒の間、品質がわずかに低下する可能性があります。 しかし、あなたが見るすべての99%は適切にレンダリングされ、ほとんどの人は実際にはそれに気づいていません。
関連: NVIDIA DLSSとは何ですか?レイトレーシングをどのように高速化しますか?
アンペールアーキテクチャ:AI向けに構築
アンペアは速いです。 特にAI計算では、非常に高速です。 RTコアはチューリングより1.7倍高速であり、新しいTensorコアはチューリングより2.7倍高速です。 この2つの組み合わせは、レイトレーシングパフォーマンスの真の世代間の飛躍です。

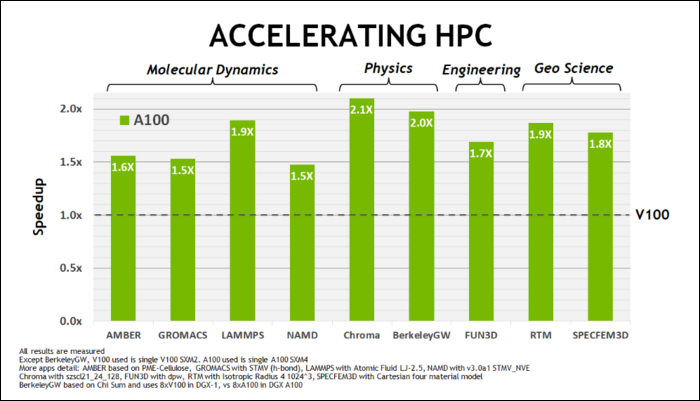
今年5月の初め、NVIDIAはAIを実行するために設計されたデータセンターGPUであるAmpere A100GPUをリリースしました。 それを使って、彼らはAmpereを非常に高速にする多くのことを詳しく説明しました。 データセンターおよび高性能コンピューティングワークロードの場合、Ampereは一般にTuringよりも約1.7倍高速です。 AIトレーニングの場合、最大6倍高速です。
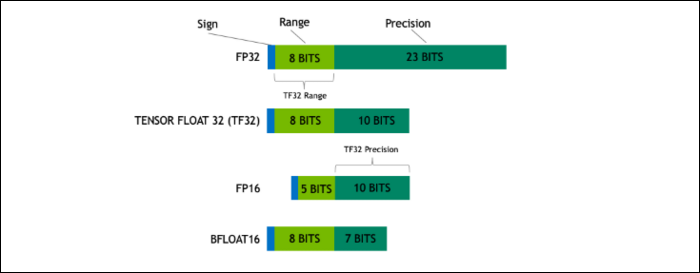
Ampereでは、NVIDIAは、一部のワークロードで業界標準の「浮動小数点32」(FP32)を置き換えるように設計された新しい数値形式を使用しています。 内部的には、コンピュータが処理するすべての数値は、8ビット、16ビット、32、64、またはそれ以上であるかどうかにかかわらず、メモリ内の事前定義されたビット数を使用します。 大きい数値は処理が難しいため、小さいサイズを使用できる場合は、クランチする必要が少なくなります。
FP32は32ビットの10進数を格納し、数値の範囲(大きさまたは小ささ)に8ビットを使用し、精度に23ビットを使用します。 NVIDIAの主張は、これらの23の高精度ビットは多くのAIワークロードに完全に必要なわけではなく、そのうちの10個から同様の結果とはるかに優れたパフォーマンスを得ることができるというものです。 サイズを32ビットではなく19ビットに減らすと、多くの計算で大きな違いが生じます。
この新しいフォーマットはTensorFloat 32と呼ばれ、A100のTensorコアは奇妙なサイズのフォーマットを処理するように最適化されています。 これは、ダイの縮小とコア数の増加に加えて、AIトレーニングで6倍の大幅なスピードアップを実現している方法です。
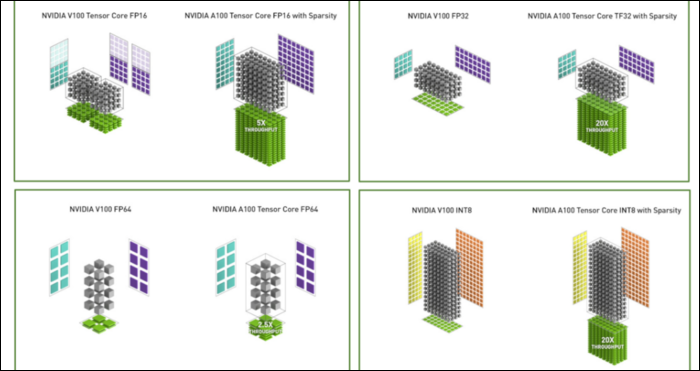
新しい数値形式に加えて、Ampereは、FP32やFP64などの特定の計算でパフォーマンスが大幅に向上しています。 これらは、素人にとってより多くのFPSに直接変換されるわけではありませんが、Tensor操作で全体的にほぼ3倍高速になる理由の一部です。
次に、計算をさらに高速化するために、非常に単純な概念を表す非常に派手な言葉である、きめの細かい構造化されたスパース性の概念を導入しました。 ニューラルネットワークは、重みと呼ばれる多数の数値のリストで機能し、最終的な出力に影響を与えます。 クランチする数が多いほど、遅くなります。
ただし、これらの数値のすべてが実際に役立つわけではありません。 それらのいくつかは文字通りゼロであり、基本的には捨てることができます。これにより、同時により多くの数値を処理できる場合、大幅なスピードアップにつながります。 Sparsityは基本的に数値を圧縮するため、計算にかかる労力が少なくて済みます。 新しい「スパーステンソルコア」は、圧縮データを操作するために構築されています。
変更にもかかわらず、NVIDIAは、これがトレーニング済みモデルの精度に目立った影響を与えるべきではないと述べています。
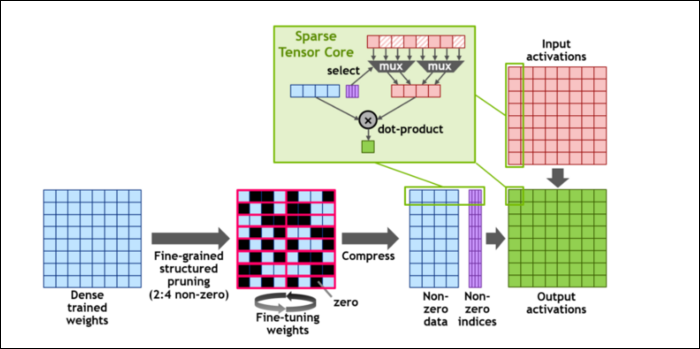
最小の数値形式の1つであるスパースINT8計算の場合、単一のA100GPUのピークパフォーマンスは1.25PetaFLOPsを超え、驚くほど高い数値です。 もちろん、それは特定の種類の数を処理するときだけですが、それでも印象的です。