
Linuxで文字列コマンドを使用する方法
公開: 2022-01-29
バイナリまたはデータファイル内のテキストを見たいですか? Linuxのstringsコマンドは、「文字列」と呼ばれるテキストのビットを引き出します。
Linuxには、問題を探すための解決策のように見えるコマンドがたくさんあります。 stringsコマンドは間違いなくその陣営に分類されます。 その目的は何ですか? バイナリファイル内から印刷可能な文字列を一覧表示するコマンドへのポイントはありますか?
一歩後退しましょう。 プログラムファイルなどのバイナリファイルには、人間が読める形式のテキストの文字列が含まれている場合があります。 しかし、どうやってそれらを見ることができますか? cat lessを使用すると、ターミナルウィンドウがハングする可能性があります。 テキストファイルで動作するように設計されたプログラムは、印刷できない文字がそれらを介して供給された場合、うまく機能しません。
バイナリファイル内のほとんどのバイトは人間が読める形式ではなく、意味のある方法でターミナルウィンドウに出力することはできません。 英数字、句読点、または空白に対応しない2進値を表す文字または標準記号はありません。 総称して、これらは「印刷可能な」文字として知られています。 残りは「印刷不可能」な文字です。
したがって、バイナリファイルまたはデータファイルでテキスト文字列を表示または検索しようとすると問題が発生します。 そこでstringsが登場します。ファイルから印刷可能な文字の文字列を抽出して、他のコマンドが印刷不可能な文字と競合することなく文字列を使用できるようにします。
文字列コマンドの使用
stringsコマンドについて複雑なことは何もありません、そしてその基本的な使用法は非常に簡単です。 コマンドラインでstringsで検索するファイルの名前を指定します。
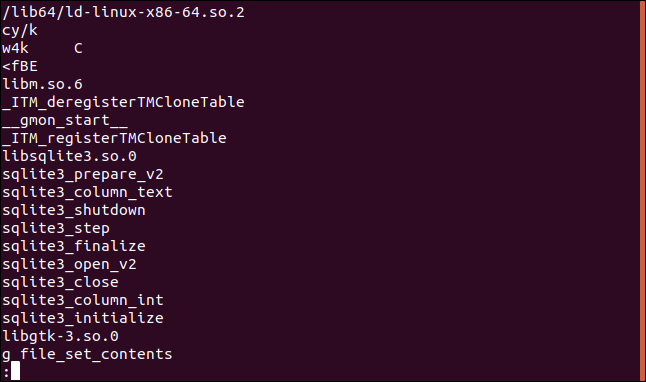
ここでは、「jibber」と呼ばれるバイナリファイル(実行可能ファイル)で文字列を使用します。 strings 、スペース、「jibber」を入力して、Enterキーを押します。
ストリングスジバー

文字列はファイルから抽出され、ターミナルウィンドウに一覧表示されます。
最小文字列長の設定
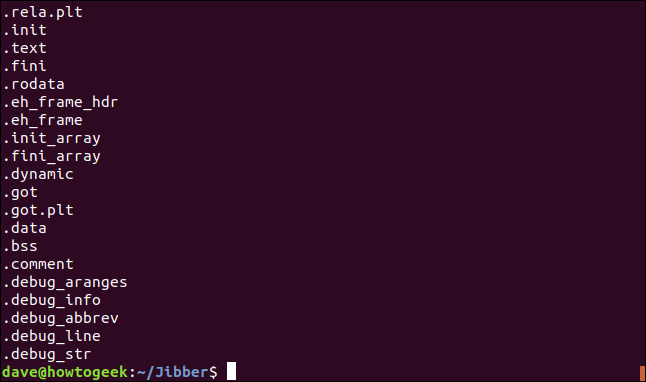
デフォルトでは、stringsは4文字以上の文字列を検索します。 より長いまたはより短い最小長を設定するには、 -n (最小長)オプションを使用します。
最小の長さが短いほど、より多くのがらくたが表示される可能性が高くなることに注意してください。
一部の2進値は、印刷可能な文字を表す値と同じ数値を持っています。 これらの数値の2つがファイル内でたまたま並んでいて、最小長を2に指定した場合、それらのバイトは文字列であるかのように報告されます。
stringsに最小長として2を使用するように要求するには、次のコマンドを使用します。
文字列-n2 jibber

結果に2文字の文字列が含まれるようになりました。 スペースは印刷可能な文字としてカウントされることに注意してください。
少ないスルーでストリングを配管する
stringsからの出力の長さのため、パイプを使用する回数をlessます。 次に、ファイルをスクロールして目的のテキストを探します。
ストリングスジバー| 以下

リストは現在、 lessで表示され、リストの上部が最初に表示されます。
オブジェクトファイルでの文字列の使用
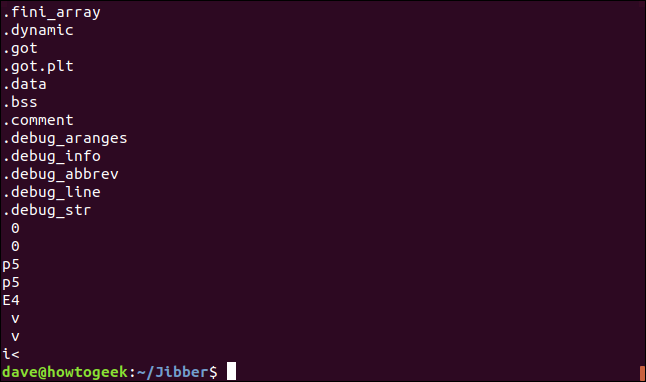
通常、プログラムのソースコードファイルはオブジェクトファイルにコンパイルされます。 これらはライブラリファイルとリンクされて、バイナリ実行可能ファイルを作成します。 手元にあるjibberオブジェクトファイルがあるので、そのファイルの内部を見てみましょう。 「.o」ファイル拡張子に注意してください。
jibber.o | 以下

文字列の最初のセットは、8文字より長い場合、すべて8列目でラップされます。 それらがラップされている場合、「H」文字は9列目にあります。 これらの文字列はSQLステートメントとして認識できます。

出力をスクロールすると、このフォーマットがファイル全体で使用されていないことがわかります。
オブジェクトファイルと完成した実行可能ファイルのテキスト文字列の違いを見るのは興味深いことです。
ファイル内の特定の領域を検索する
コンパイルされたプログラムには、テキストを格納するために使用されるさまざまな領域があります。 デフォルトでは、 stringsはファイル全体を検索してテキストを探します。 これは、 -a (すべて)オプションを使用した場合と同じです。 ファイル内の初期化されてロードされたデータセクションでのみ文字列を検索するには、 -d (データ)オプションを使用します。
文字列-djibber | 以下

正当な理由がない限り、デフォルト設定を使用してファイル全体を検索することもできます。
文字列オフセットの印刷
各文字列が配置されているファイルの先頭からのオフセットをstringsに出力させることができます。 これを行うには、 -o (オフセット)オプションを使用します。
文字列-oparse_phrases | 以下

オフセットは8進数で示されます。
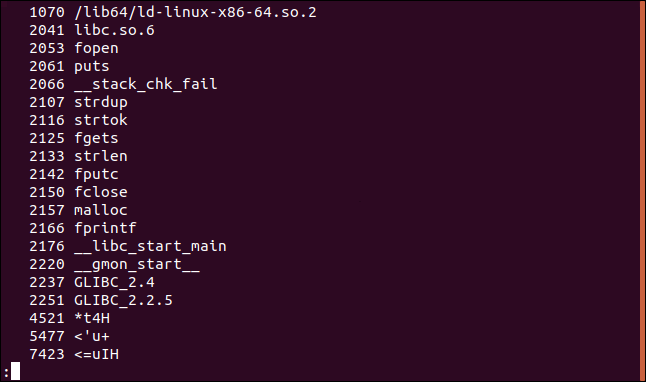
オフセットを10進数や16進数などの別の数値ベースで表示するには、 -t (基数)オプションを使用します。 基数オプションの後には、 d (10進数)、 x (16進数)、またはo (8進数)を続ける必要があります。 -to使用することは、 -oを使用することと同じです。
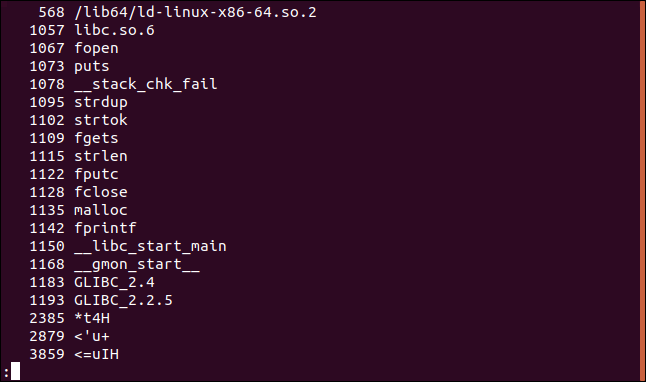
文字列-tdparse_phrases | 以下

オフセットが10進数で印刷されるようになりました。
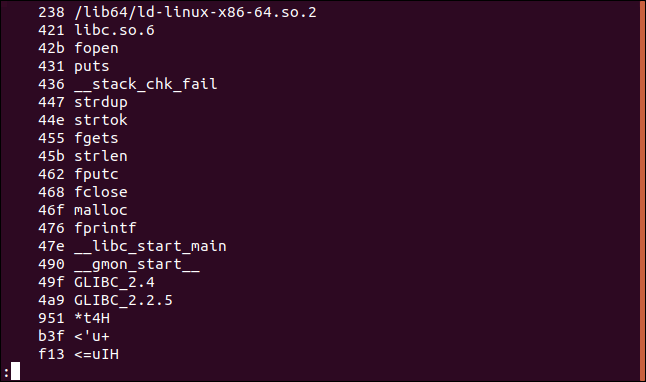
文字列-txparse_phrases | 以下


オフセットが16進数で印刷されるようになりました。
空白を含む
stringsは、タブ文字とスペース文字を、検出した文字列の一部と見なします。 改行やキャリッジリターンなどの他の空白文字は、文字列の一部であるかのように扱われません。 -w (空白)オプションを使用すると、文字列はすべての空白文字を文字列の一部であるかのように扱います。
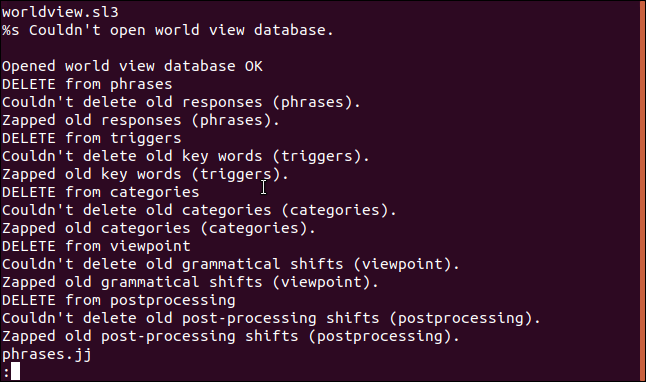
文字列-wadd_data | 以下

出力に空白行が表示されます。これは、(非表示の)キャリッジリターンと2行目の終わりの改行文字の結果です。
ファイルに限定されません
stringsは、バイトのストリームである、または生成できるものなら何でも使用できます。
このコマンドを使用すると、コンピューターのランダムアクセスメモリ(RAM)を調べることができます。
/ dev / memにアクセスしているため、 sudoを使用する必要があります。 コンピュータのメインメモリの画像を保持する文字デバイスファイルです。
sudo文字列/ dev / mem | 以下

リストはRAMの内容全体ではありません。 そこから抽出できるのは文字列だけです。
関連: Linuxで「すべてがファイルである」とはどういう意味ですか?
一度に多くのファイルを検索する
ワイルドカードを使用して、検索するファイルのグループを選択できます。 *文字は複数の文字を表し、 ? 文字は任意の1文字を表します。 コマンドラインで多くのファイル名を指定することもできます。
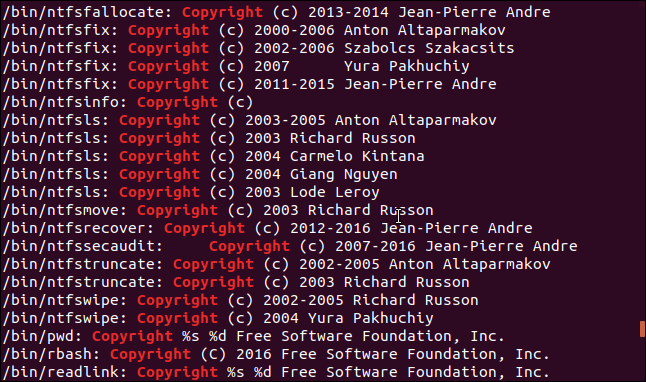
ワイルドカードを使用して、/ binディレクトリ内のすべての実行可能ファイルを検索します。 リストには多くのファイルの結果が含まれるため、 -f (ファイル名)オプションを使用します。 これにより、各行の先頭にファイル名が出力されます。 次に、各文字列がで見つかったファイルを確認できます。
結果をgrepにパイプし、「Copyright」という単語を含む文字列を探しています。
文字列-f / bin / * | grep著作権

/ binディレクトリ内の各ファイルの著作権表示のきちんとしたリストを取得し、各行の先頭にファイルの名前を付けます。
ひもが解ける
文字列に謎はありません。 これは典型的なLinuxコマンドです。 それは非常に具体的なことをし、それを非常にうまく行います。
これはLinuxのもう1つの歯車であり、他のコマンドを操作しているときに実際に機能します。 バイナリファイルとgrepのような他のツールの間にどのように配置できるかを見ると、この少しあいまいなコマンドの機能を理解し始めます。
| Linuxコマンド | ||
| ファイル | tar・pv・cat・tac・chmod・grep・diff・sed・ar・man・pushd・popd・fsck・testdisk・seq・fd・pandoc・cd・$ PATH・awk・join・jq・fold・uniq・journalctl・tail・stat・ls・fstab・echo・less・chgrp・chown・rev・look・strings・type・rename・zip・unzip・mount・umount・install・fdisk・mkfs・rm・rmdir・rsync・df・gpg・vi・nano・mkdir・du・ln・patch・convert・rclone・shred・srm | |
| プロセス | エイリアス・screen・top・nice・renice・progress・strace・systemd・tmux・chsh・history・at・batch・free・which・dmesg・chfn・usermod・ps・chroot・xargs・tty・pinky・lsof・vmstat・タイムアウト・wall・yes・kill・sleep・sudo・su・time・groupadd・usermod・groups・lshw・shutdown・reboot・halt・poweroff・passwd・lscpu・crontab・date・bg・fg | |
| ネットワーキング | netstat・ping・traceroute・ip・ss・whois・fail2ban・bmon・dig・finger・nmap・ftp・curl・wget・who・whoami・w・iptables・ssh-keygen・ufw |
関連:開発者と愛好家のための最高のLinuxラップトップ