
LinuxでBashで文字列を操作する方法
公開: 2022-07-28
Linuxに十分に装備されているものがあるとすれば、それは文字列を操作するためのユーティリティです。 しかし、Bashシェルにも一連の機能が組み込まれています。 使用方法は次のとおりです。
文字列操作
Linuxエコシステムには、テキストと文字列を操作するための素晴らしいツールが満載です。 これらには、awk、grep、sed、およびcutが含まれます。 重いテキストのラングリングについては、これらがあなたの頼りになる選択であるべきです。
ただし、特に短くて単純なスクリプトを作成する場合は、シェルの組み込み機能を使用すると便利な場合があります。 スクリプトを他の人と共有し、その人のコンピューターで実行する場合、標準のBash機能を使用すると、他のユーティリティの存在やバージョンについて考える必要がなくなります。
専用ユーティリティのパワーが必要な場合は、ぜひご利用ください。 それが彼らの目的です。 しかし、多くの場合、スクリプトとBashは自分で仕事を成し遂げることができます。
これらはBashに組み込まれているため、スクリプトまたはコマンドラインで使用できます。 ターミナルウィンドウでそれらを使用すると、コマンドのプロトタイプを作成して構文を完成させるための高速で便利な方法です。 編集、保存、実行、およびデバッグのサイクルを回避します。
文字列変数の作成と操作
変数を宣言して文字列を割り当てるために必要なのは、変数に名前を付け、等号=を使用して、文字列を指定することだけです。 文字列にスペースがある場合は、一重引用符または二重引用符で囲みます。 等号の両側に空白がないことを確認してください。
my_string = "こんにちは、ハウツーオタクワールド。"
エコー$my_string

変数を作成すると、その変数名がシェルのタブ補完ワードのリストに追加されます。 この例では、「my_」と入力して「Tab」キーを押すと、コマンドラインにフルネームが入力されました。
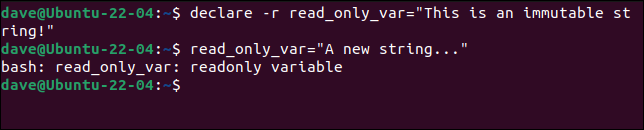
読み取り専用変数
変数の宣言に使用できるdeclareコマンドがあります。 単純なケースでは、実際には必要ありませんが、これを使用すると、コマンドのオプションの一部を使用できます。 おそらく、最もよく使用するのは-r (読み取り専用)オプションです。 これにより、変更できない読み取り専用変数が作成されます。
宣言-rread_only_var= "これは不変の文字列です!"
新しい値を割り当てようとすると失敗します。
read_only_var="新しい文字列..."
ターミナルウィンドウへの書き込み
echoまたはprintfを使用して、ターミナルウィンドウに複数の文字列を書き込み、1つの文字列のように見せることができます。 また、独自の文字列変数に限定されず、環境変数をコマンドに組み込むことができます。
user_account ="ユーザーアカウントは次のとおりです:"
エコー$user_account$ USER

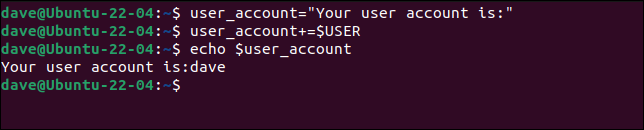
文字列の連結
plus-equals演算子+=を使用すると、2つの文字列を「追加」できます。 それは連結と呼ばれます。
user_account ="ユーザーアカウントは次のとおりです:"
user_account + = $ USER
エコー$user_account
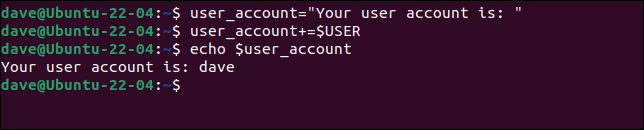
連結された文字列の間にスペースが自動的に追加されないことに注意してください。 スペースが必要な場合は、最初の文字列の最後または2番目の文字列の先頭にスペースを明示的に配置する必要があります。
user_account = "あなたのユーザーアカウントは:"
user_account + = $ USER
エコー$user_account
関連: Linux上のBashで環境変数を設定する方法
ユーザー入力の読み取り
宣言の一部として内容が定義されている文字列変数を作成するだけでなく、ユーザー入力を文字列変数に読み込むことができます。
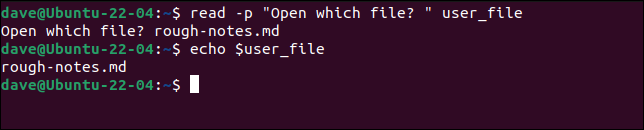
readコマンドは、ユーザー入力を読み取ります。 -p (プロンプト)オプションは、ターミナルウィンドウにプロンプトを書き込みます。 ユーザーの入力は文字列変数に格納されます。 この例では、変数はuser_fileと呼ばれます。
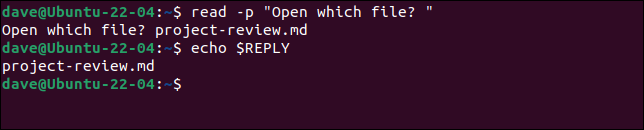
read -p "どのファイルを開きますか?" user_file
エコー$user_file
入力をキャプチャするための文字列変数を指定しない場合でも、機能します。 ユーザー入力は、 REPLYという変数に格納されます。
-p「どのファイルを開きますか?」を読んでください。
エコー$REPLY
通常は、独自の変数を指定して、意味のある名前を付ける方が便利です。
文字列の操作
作成時に定義されているか、ユーザー入力から読み取られているか、文字列を連結して作成されているかに関係なく、文字列ができたので、文字列を使って作業を開始できます。
文字列の長さを見つける
文字列の長さを知ることが重要または有用な場合は、変数名の前にハッシュ「 # 」記号を付けることで取得できます。
my_string="この文字列には39文字あります。"
エコー${#my_string} 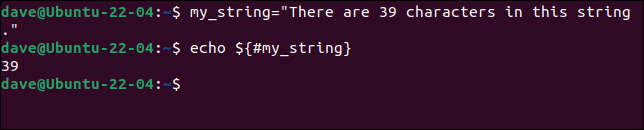

文字オフセットによる部分文字列の抽出
文字列内の開始点とオプションの長さを指定することにより、文字列変数から部分文字列を抽出できます。 長さを指定しない場合、サブストリングには開始点から最後の文字までのすべてが含まれます。
開始点と長さは変数名の後に続き、間にコロン「 : 」があります。 文字列変数の文字には、ゼロから始まる番号が付けられていることに注意してください。
long_string="フランケンシュタインまたは現代のプロメテウス"
substring = $ {long_string:0:12}エコー$substring
エコー${long_string:27} 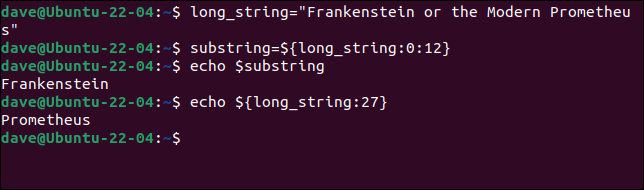
別のバリエーションでは、文字列の末尾からいくつかの文字を破棄できます。 事実上、開始点を設定し、長さとして負の数を使用できます。 サブストリングには、ストリングの開始点から終了までの文字から、負の数で指定した文字数を引いたものが含まれます。
my_string = "alphabetical"
エコー${my_string:5:-4} 
すべての場合において、元の文字列変数は変更されていません。 「抽出された」部分文字列は、実際には変数の内容から削除されません。
区切り文字による部分文字列の抽出
文字オフセットを使用することの欠点は、抽出する部分文字列が文字列内のどこにあるかを事前に知っておく必要があることです。
文字列が繰り返し文字で区切られている場合は、文字列のどこにあるか、またはその長さを知らなくても、部分文字列を抽出できます。
文字列の先頭から検索するには、変数名の後に2つのパーセント記号%% 、区切り文字、およびアスタリスク*を付けます。 この文字列内の単語はスペースで区切られています。
long_string="最初の2番目の3番目の4番目の5番目"
エコー${long_string%%'' *} 
これにより、区切り文字を含まない文字列の先頭から最初の部分文字列が返されます。 これは、短い部分文字列オプションと呼ばれます。
long substringオプションは、最後に区切られたサブストリングまでのストリングの前部を返します。 つまり、最後に区切られた部分文字列が省略されます。 構文的には、唯一の違いは、コマンドで単一のパーセント記号「 % 」を使用することです。
long_string="最初の2番目の3番目の4番目の5番目"
エコー${long_string%'' *} 
ご想像のとおり、文字列の末尾から同じ方法で検索できます。 パーセント記号の代わりに、ハッシュ「 # 」記号を使用し、コマンドのアスタリスク「 * 」の後に続くように区切り文字を移動します。
long_string = "this.long.string.of.words.is.delimited.by.periods"
エコー${long_string##*。} 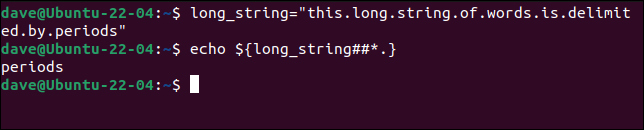
これは短い部分文字列オプションであり、区切り文字を含まない文字列の後ろから最初に見つかった部分文字列を削除します。
long_string = "this.long.string.of.words.is.delimited.by.periods"
エコー${long_string#*。} 
long substringオプションは、文字列の前部から最初の区切り文字までの文字列の後部を返します。 つまり、最初に区切られた部分文字列が省略されます。
部分文字列の置換
サブストリングを他のサブストリングに交換するのは簡単です。 形式は、文字列の名前、置き換えられるサブ文字列、および挿入されるサブ文字列であり、スラッシュ「 / 」文字で区切られます。
string="青いブタの笑い声"
エコー${string/ pig / goat} 
検索を文字列の最後に制限するには、検索文字列の前にパーセント記号「 % 」文字を付けます。
string="青いブタの笑い声"
エコー${文字列/%ギグル/チャックル} 
検索を文字列の先頭に限定するには、検索文字列の前にハッシュ「 # 」文字を付けます。
string="青いブタの笑い声"
エコー${string/#blue / yellow} 
文字列は柔軟なものです
文字列が希望どおりでない場合、または必要な場合は、これらのツールを使用して、ニーズに合うように文字列を再フォーマットできます。 複雑な変換の場合は専用のユーティリティを使用しますが、微調整の場合は組み込みのシェルを使用して、外部ツールのロードと実行のオーバーヘッドを回避します。
関連: Linux上のiノードについて知りたいと思ったことすべて