
Wie die Suchmaschine funktioniert und Ihr Leben einfacher macht
Veröffentlicht: 2015-11-06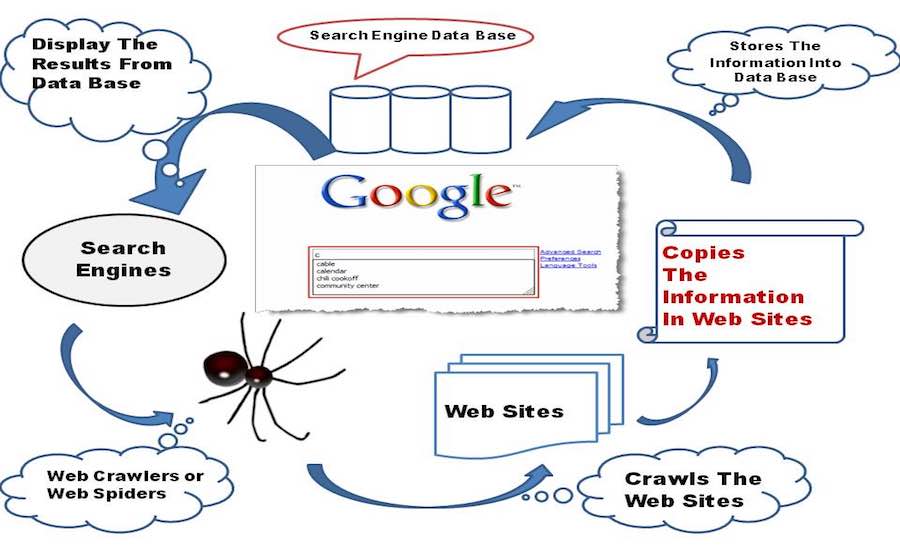 Short Bytes: Search Engine ist eine Software, die die Anzeige relevanter Webseitenergebnisse basierend auf der Suchanfrageneingabe durch die Verwendung von Web Crawling und Web Indexing, einigen dicken Formeln und intelligenten Algorithmen ermöglicht, um die entsprechenden Daten zu sammeln.
Short Bytes: Search Engine ist eine Software, die die Anzeige relevanter Webseitenergebnisse basierend auf der Suchanfrageneingabe durch die Verwendung von Web Crawling und Web Indexing, einigen dicken Formeln und intelligenten Algorithmen ermöglicht, um die entsprechenden Daten zu sammeln.
Wie Google Ihnen im Handumdrehen die besten Ergebnisse liefert? Eigentlich ist es egal, bis Google, Bing da sind. Das Szenario wäre ganz anders gewesen, wenn es kein Google, Bing oder Yahoo gegeben hätte. Lassen Sie uns in die Welt der Suchmaschinen eintauchen und sehen, wie eine Suchmaschine funktioniert.
Ein Blick in die Geschichte
Das Suchmaschinenmärchen begann in den 1990er Jahren, als Tim Berners-Lee jeden neuen Webserver, der online ging, in die vom CERN-Webserver geführte Liste eintrug. Bis September 93 gab es im Internet keine Suchmaschinen, sondern nur wenige Tools, die in der Lage waren, eine Datenbank mit Dateinamen zu pflegen. Archie, Veronica, Jughead waren die allerersten Teilnehmer in dieser Kategorie.
Oscar Nierstrasz von der Universität Genf ist für die allererste Suchmaschine namens W3Catalog akkreditiert. Er arbeitete ernsthaft an Perl-Skripten und brachte schließlich am 3. September 1993 die erste Suchmaschine der Welt heraus. Darüber hinaus sah das Jahr 1993 das Aufkommen vieler anderer Suchmaschinen. JumpStation von Jonathon Fletcher, AliWeb, WWW Worm usw. Yahoo! wurde 1995 als Web-Verzeichnis eingeführt, begann jedoch ab 2000 mit der Suchmaschine von Inktomi und wechselte dann 2009 zu Microsofts Bing.
Nun, über den Namen zu sprechen, der das Hauptsynonym für den Begriff Suchmaschine ist, Google Search, war ein Forschungsprojekt für zwei Stanford-Absolventen, Larry Page und Sergy Brin, das im März 1995 seine ersten Spuren hinterließ. Die Arbeit von Google war ursprünglich inspiriert by Pages Backlinking-Methode, die Berechnungen anstellte, basierend darauf, wie viele Backlinks von einer Webseite stammen, um die Bedeutung dieser Seite im World Wide Web zu messen. „Der beste Rat, den ich je bekommen habe“, sagte Page, während er sich erinnerte, wie sein Vorgesetzter Terry Winograd seine Idee unterstützte. Und seitdem hat Google nie zurückgeschaut.
Alles beginnt mit einem Kriechen
Eine Baby-Suchmaschine im Anfangsstadium beginnt das World Wide Web zu erkunden, mit ihren kleinen Händen und Knien erforscht sie jeden anderen Link, den sie auf einer Webseite findet, und speichert sie in ihrer Datenbank.
Konzentrieren wir uns nun auf einige technische Gedanken hinter den Kulissen. Eine Suchmaschine enthält eine Webcrawler-Software, die im Grunde ein Internet-Bot ist, der die Aufgabe hat, alle auf einer Webseite vorhandenen Hyperlinks zu öffnen und aus allen Links eine Datenbank mit Text und Metadaten zu erstellen . Es beginnt mit einer ersten Reihe von Links, die Sie besuchen können, genannt Seeds. Sobald es mit dem Besuch dieser Links fortfährt, fügt es der bestehenden Liste der zu besuchenden URLs neue Links hinzu, die als Crawl Frontier bekannt sind.
Während der Crawler die Links durchquert, lädt er die Informationen von diesen Webseiten herunter, um sie später in Form von Schnappschüssen anzuzeigen, da das Herunterladen der gesamten Webseite eine ganze Menge Daten erfordern würde, und es kostet mindestens eine Tasche Ländern wie Indien. Und ich kann wetten, wenn Google in Indien gegründet würde, würde all ihr Geld verwendet werden, um die Internetrechnungen zu bezahlen. Hoffentlich ist das jetzt kein Thema zur Besorgnis.
Der Web-Crawler untersucht die Webseiten basierend auf einigen Richtlinien:
Auswahlrichtlinie: Der Crawler entscheidet, welche Seiten er herunterladen soll und welche nicht. Die Auswahlpolitik konzentriert sich auf das Herunterladen der relevantesten Inhalte einer Webseite und nicht auf einige unwichtige Daten.
Re-Visit Policy: Crawler plant den Zeitpunkt, zu dem er die Webseiten erneut öffnen und die Änderungen in seiner Datenbank bearbeiten sollte, dank der dynamischen Natur des Internets, die es für die Crawler sehr schwierig macht, mit den neuesten Versionen von aktualisiert zu bleiben die Webseiten.
Parallelisierungsrichtlinie: Crawler verwenden mehrere Prozesse gleichzeitig, um die als verteiltes Crawling bekannten Links zu erkunden, aber manchmal besteht die Möglichkeit, dass verschiedene Prozesse dieselbe Webseite herunterladen, sodass der Crawler eine Koordination zwischen allen Prozessen aufrechterhält, um alle Chancen zu eliminieren Duplizität.
Höflichkeitsrichtlinie: Wenn ein Crawler eine Website durchquert, lädt er gleichzeitig Webseiten von ihr herunter und erhöht so die Last auf dem Webserver, der die Website hostet. Daher wird ein Begriff „Crawl-Delay“ eingeführt, bei dem der Crawler einige Sekunden warten muss, nachdem er einige Daten von einem Webserver heruntergeladen hat, und der Politeness Policy unterliegt.
Lesen Sie auch: So erstellen Sie einen einfachen Webcrawler in Python
High-Level-Architektur eines Standard-Web-Crawlers:
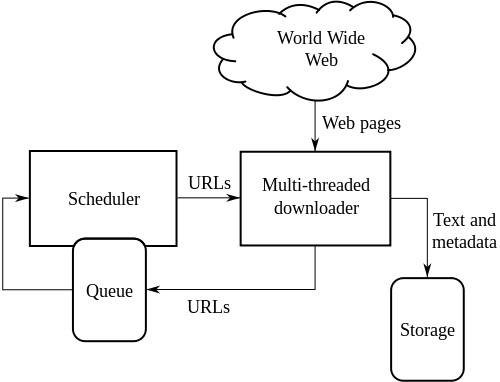
Die obige Abbildung zeigt, wie ein Webcrawler funktioniert. Es öffnet die anfängliche Liste von Links und dann Links innerhalb dieser Links und so weiter.
Wikipedia schreibt, die Informatikforscher Vladislav Shkapenyuk und Torsten Suel stellten fest, dass:
Während es ziemlich einfach ist, einen langsamen Crawler zu bauen, der für kurze Zeit einige Seiten pro Sekunde herunterlädt, stellt der Aufbau eines Hochleistungssystems, das Hunderte Millionen Seiten über mehrere Wochen herunterladen kann, eine Reihe von Herausforderungen im Systemdesign dar. E/A- und Netzwerkeffizienz sowie Robustheit und Verwaltbarkeit.
Indizierung der Crawls
Nachdem die Baby-Suchmaschine das gesamte Internet durchsucht hat, erstellt sie einen Index aller Webseiten, die sie auf ihrem Weg findet. Einen Index zu haben ist viel besser, als Zeit damit zu verschwenden, die Suchanfrage aus einem Haufen großer Dokumente zu finden, es spart sowohl Zeit als auch Ressourcen.
Es gibt viele Faktoren, die dazu beitragen, ein effizientes Indizierungssystem für eine Suchmaschine zu erstellen. Von den Indexierern verwendete Speichertechniken, die Größe des Indexes, die Fähigkeit, die Dokumente mit den gesuchten Schlüsselwörtern schnell zu finden usw., sind die Faktoren, die für die Effizienz und Zuverlässigkeit eines Indexes verantwortlich sind.
Eines der größten Hindernisse auf dem Weg zur Erstellung erfolgreicher Web-Indizes ist die Kollision zwischen zwei Prozessen. Angenommen, ein Prozess möchte ein Dokument durchsuchen und gleichzeitig möchte ein anderer Prozess ein Dokument zum Index hinzufügen, was zu Konflikten zwischen den beiden Prozessen führt. Das Problem wird noch verschlimmert durch die Implementierung von verteiltem Rechnen durch die Suchmaschinen, um mehr Daten zu handhaben.
Indexarten
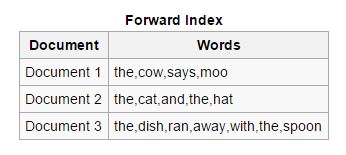
Weiterleiten: Bei dieser Art von Indizes werden alle in einem Dokument vorhandenen Schlüsselwörter in einer Liste gespeichert. Der Forward-Index lässt sich in der Anfangsphase der Indizierung einfach erstellen, da er es asynchronen Indexierern ermöglicht, miteinander zusammenzuarbeiten.
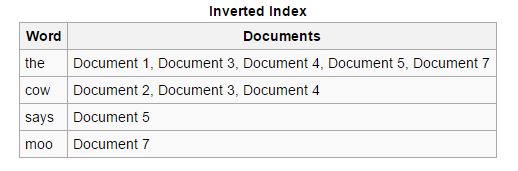
Rückwärts: Die Vorwärtsindizes werden sortiert und in Rückwärtsindizes umgewandelt, in denen jedes Dokument, das ein bestimmtes Schlüsselwort enthält, mit anderen Dokumenten zusammengefügt wird, die dieses Schlüsselwort enthalten. Rückwärtsindizes erleichtern das Auffinden relevanter Dokumente für eine bestimmte Suchanfrage, was bei Vorwärtsindizes nicht der Fall ist.

Lesen Sie auch: Was ist DNS (Domain Name System) und wie funktioniert es?
Parsing von Dokumenten
Auch als Tokenisierung bezeichnet, bezieht sich auf die Aufschlüsselung von Komponenten eines Dokuments wie Schlüsselwörter (als Token bezeichnet), Bilder und andere Medien, damit sie später in Indizes eingefügt werden können. Die Methode konzentriert sich im Wesentlichen darauf, die Muttersprache zu verstehen und die Schlüsselwörter vorherzusagen, nach denen ein Benutzer suchen könnte, was als Grundlage für die Erstellung eines effektiven Web-Indexierungssystems dient.
Zu den größten Herausforderungen gehört das Finden der Wortgrenzen von zu extrahierenden Schlüsselwörtern, da wir sehen können, dass Sprachen wie Chinesisch und Japanisch im Allgemeinen keine Leerzeichen in ihren Sprachskripten haben. Das Verständnis der Mehrdeutigkeit einer Sprache ist ebenfalls ein Problem, da sich einige Sprachen bei geografischen Veränderungen geringfügig oder sogar erheblich unterscheiden. Auch die Ineffizienz mancher Webseiten, da die verwendete Sprache nicht eindeutig erwähnt wird, gibt Anlass zur Sorge und erhöht die Arbeitsbelastung der Indexierer.
Suchmaschinen sind in der Lage, verschiedene Dateiformate zu erkennen und daraus erfolgreich Daten zu extrahieren, und in diesen Fällen ist äußerste Sorgfalt geboten.
Meta-Tags sind auch sehr nützlich, um die Indizes sehr schnell zu erstellen, sie reduzieren den Aufwand des Webindexers und erleichtern die Notwendigkeit, das gesamte Dokument vollständig zu analysieren. Am Ende dieses Artikels finden Sie Meta-Tags.
Durchsuchen des Index
Jetzt ist die Baby-Suchmaschine kein Baby mehr, er hat gelernt, wie man krabbelt und schnell und effizient nach Dingen greift und seine Sachen systematisch ordnet. Angenommen, sein Freund bittet ihn, etwas aus seinem Arrangement zu finden, was wird er tun? Es gibt vier Arten von Suchabfragen, die verwendet werden, obwohl sie nicht formal abgeleitet sind, aber sie haben sich im Laufe der Zeit entwickelt und haben sich in Bezug auf die von Benutzern im wirklichen Leben gestellten Abfragen als gültig erwiesen.
Navigational: Dieser Begriff wird für solche Abfragen verwendet, bei denen der Benutzer zu einer bestimmten Webseite oder Website gehen möchte, die im Internet vorhanden ist. Wenn Sie beispielsweise bei Google nach fossBytes suchen, starten Sie eine Navigationsabfrage.
Informativ: Diese Art von Abfragen hat Tausende von Ergebnissen und deckt allgemeine Themen ab, die das Wissen des Benutzers erweitern. Wenn Sie beispielsweise nach Steve Jobs suchen, werden Ihnen alle für Steve Jobs relevanten Links angezeigt.
Transaktional: Abfragen, die sich auf die Absicht des Benutzers konzentrieren, eine bestimmte Aktion auszuführen, können einen vordefinierten Satz von Anweisungen umfassen. Zum Beispiel, Wie finde ich meinen verlorenen/gestohlenen Laptop?
Konnektivität: Diese Art von Abfragen wird nicht häufig verwendet, sie konzentrieren sich darauf, wie verbunden der von einer Website erstellte Index ist. Wenn Sie beispielsweise suchen: Wie viele Seiten gibt es auf Wikipedia?
Google und Bing haben einige seriöse Algorithmen entwickelt, die in der Lage sind, die relevantesten Ergebnisse für Ihre Suchanfrage zu ermitteln. Google behauptet, Ihre Suchergebnisse auf der Grundlage von über 200 Faktoren wie Qualität des Inhalts, neu oder alt, Sicherheit der Webseite und vielem mehr zu berechnen. Sie haben die größten Köpfe der Welt in ihren Suchlabors ernannt, die harte Berechnungen anstellen und sich mit überwältigenden Formeln auseinandersetzen, nur um die Suche für Sie einfacher und schneller zu machen.
Andere bemerkenswerte Merkmale*
Bildsuche: Sie werden überrascht sein, die Inspiration von Google hinter ihrem berühmten Bildsuchtool zu erfahren. J.Lo, ja, Sie haben richtig gehört, J.Lo und ihr grünes Kleid von Versace (vers-sah-chay) bei den Grammy Awards 2000 waren der wahre Grund, warum Google mit seiner Bildersuche herauskam, da die Leute damit beschäftigt waren, zu googeln ihr.
Sagte Eric Schmidt in seinem Schreiben mit dem Titel „The Tinkerer's Apprentice“, veröffentlicht am 19. Januar 2015.
Sprachsuche: Google hat nach langer harter Arbeit als erster die Sprachsuche in seiner Suchmaschine eingeführt, und in der Folge haben auch andere Suchmaschinen sie implementiert.
Spam-Bekämpfung: Suchmaschinen setzen einige ernsthafte Algorithmen ein, damit sie Sie vor Spam-Angriffen schützen können . Ein Spam ist im Grunde eine Nachricht oder eine Datei, die im Internet verbreitet wird, vielleicht für Werbung oder zur Übertragung von Viren. Auch in dieser Angelegenheit informieren die Google-Jungs manuell die Website, die ihrer Meinung nach für die Verbreitung von Spam-Nachrichten im Internet verantwortlich ist.
Standortoptimierung: Die Suchmaschinen sind jetzt in der Lage, Ergebnisse basierend auf dem Standort des Benutzers anzuzeigen. Wenn Sie suchen, wie ist das Wetter in Bengaluru, dann beziehen sich die Wetterstatistiken auf Bengaluru.
Versteht Sie besser: Moderne Suchmaschinen sind in der Lage, die Bedeutung der Benutzeranfrage zu verstehen, anstatt die vom Benutzer eingegebenen Schlüsselwörter zu finden.
Automatische Vervollständigung : Die Fähigkeit, Ihre Suchanfrage während der Eingabe basierend auf Ihren vorherigen Suchen und Suchen anderer Benutzer vorherzusagen.
Knowledge Graph: Diese Funktion, die von der Google-Suche bereitgestellt wird, demonstriert ihre Fähigkeit, Suchergebnisse basierend auf realen Personen, Orten und Ereignissen bereitzustellen.
Kindersicherung: Suchmaschinen ermöglichen es Eltern kleiner Art, zu kontrollieren, was ihr Kind im Internet macht.
* Es ist schwer, die riesige Liste der Funktionen abzudecken, die diese mächtigen Suchmaschinen bieten.
Auflösung
Suchmaschinen haben dazu beigetragen, unser Leben einfacher zu machen, und die harte Arbeit, die sie leisten, um alle Informationen im Internet nutzbar zu machen, ist unbezahlbar. Aber diese Erforschung hat zur Ausstellung unseres persönlichen Raums auf einer öffentlichen Plattform geführt, und ich muss sagen, es ist höchste Zeit, dass wir uns über den Weg, den wir so lange gegangen sind, aufregen, es sei denn, es ist zu spät für uns, unsere Handlungen zurückzublicken und unser Leben nur eine Biennale der Peinlichkeiten sein. Wir können die Tatsache nicht leugnen, dass Suchmaschinen jetzt ein wesentlicher Bestandteil unserer digitalen gespaltenen Persönlichkeit sind. Wir müssen nur die Technologie nutzen, die uns gegeben wurde, und nicht zulassen, dass sie uns in den Ketten unserer eigenen Missetaten versklavt.
Okay, keine emotionalen Gespräche mehr, bewundere einfach die Niedlichkeit und die Talente dieser Baby-Suchmaschine, die jetzt ein Teenager geworden ist und dich viel besser versteht. Google war da, um alles für uns zu durchsuchen, es ist für viele von uns das Internet, und wir müssen die guten Erfahrungen schätzen, die wir bei der Verwendung der Google-Suche gesammelt haben. Oh! Ich habe vergessen, Bing zu erwähnen, du bist auch großartig. Bleiben Sie wachsam, bleiben Sie sicher und googeln Sie es.
Sehen Sie sich dieses Video an und erfahren Sie mehr über Suchmaschinen:
Haben Sie jemals in der Google-Suche auf die Schaltfläche „Ich fühle mich glücklich “ geklickt? Öffnen Sie es und teilen Sie uns im Kommentarbereich unten mit, welches Doodle Ihnen am besten gefallen hat.