
So analysieren Sie CSV-Daten in Bash
Veröffentlicht: 2022-09-16
Comma Separated Values (CSV)-Dateien sind eines der gängigsten Formate für exportierte Daten. Unter Linux können wir CSV-Dateien mit Bash-Befehlen lesen. Aber es kann sehr schnell sehr kompliziert werden. Wir helfen mit.
Was ist eine CSV-Datei?
Eine Datei mit kommagetrennten Werten ist eine Textdatei, die tabellierte Daten enthält. CSV ist eine Art von durch Trennzeichen getrennten Daten. Wie der Name schon sagt, wird ein Komma „ , “ verwendet, um jedes Datenfeld – oder jeden Wert – von seinen Nachbarn zu trennen.
CSV ist überall. Wenn eine Anwendung über Import- und Exportfunktionen verfügt, unterstützt sie fast immer CSV. CSV-Dateien sind menschenlesbar. Sie können mit less hineinschauen, sie in einem beliebigen Texteditor öffnen und von Programm zu Programm verschieben. Beispielsweise können Sie die Daten aus einer SQLite-Datenbank exportieren und in LibreOffice Calc öffnen.
Aber auch CSV kann kompliziert werden. Möchten Sie ein Komma in einem Datenfeld haben? Dieses Feld muss mit Anführungszeichen „ " “ umschlossen sein. Um Anführungszeichen in ein Feld aufzunehmen, muss jedes Anführungszeichen zweimal eingegeben werden.
Wenn Sie mit CSV arbeiten, die von einem von Ihnen geschriebenen Programm oder Skript generiert wurden, ist das CSV-Format wahrscheinlich einfach und unkompliziert. Wenn Sie gezwungen sind, mit komplexeren CSV-Formaten zu arbeiten, da Linux Linux ist, gibt es Lösungen, die wir auch dafür verwenden können.
Einige Beispieldaten
Mit Websites wie dem Online Data Generator können Sie ganz einfach einige CSV-Beispieldaten generieren. Sie können die gewünschten Felder definieren und auswählen, wie viele Datenzeilen Sie möchten. Ihre Daten werden anhand realistischer Dummy-Werte generiert und auf Ihren Computer heruntergeladen.
Wir haben eine Datei erstellt, die 50 Zeilen mit Dummy-Mitarbeiterinformationen enthält:
- id : Ein einfacher eindeutiger ganzzahliger Wert.
- firstname : Der Vorname der Person.
- lastname : Der Nachname der Person.
- job-title : Die Berufsbezeichnung der Person.
- E-Mail-Adresse : Die E-Mail-Adresse der Person.
- branch : Die Unternehmensbranche, in der sie arbeiten.
- state : Das Bundesland, in dem sich die Filiale befindet.
Einige CSV-Dateien haben eine Kopfzeile, die die Feldnamen auflistet. Unsere Beispieldatei hat eine. Hier ist der Anfang unserer Datei:
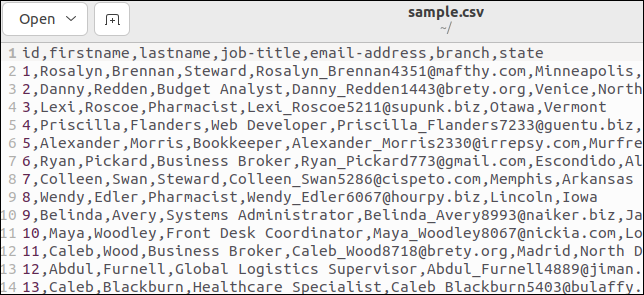
Die erste Zeile enthält die Feldnamen als kommagetrennte Werte.
Analysieren von Daten aus der CSV-Datei
Lassen Sie uns ein Skript schreiben, das die CSV-Datei liest und die Felder aus jedem Datensatz extrahiert. Kopieren Sie dieses Skript in einen Editor und speichern Sie es in einer Datei namens „field.sh“.
#! /bin/bash while IFS="," read -r id Vorname Nachname Jobtitel E-Mail Branche Status tun echo "Datensatz-ID: $id" echo "Vorname: $vorname" echo "Nachname: $lastname" Echo "Jobtitel: $jobtitle" echo "E-Mail hinzufügen: $email" Echo "Zweig: $Zweig" Echo "Zustand: $Zustand" echo "" fertig < <(tail -n +2 sample.csv)
In unser kleines Skript ist einiges gepackt. Lass es uns aufschlüsseln.

Wir verwenden eine while -Schleife. Solange die Bedingung der while -Schleife wahr wird, wird der Rumpf der while -Schleife ausgeführt. Der Körper der Schleife ist ziemlich einfach. Eine Sammlung von echo -Anweisungen wird verwendet, um die Werte einiger Variablen im Terminalfenster auszugeben.
Die Bedingung der while -Schleife ist interessanter als der Rumpf der Schleife. Dass ein Komma als internes Feldtrennzeichen verwendet werden soll, legen wir mit der IFS="," Anweisung fest. Das IFS ist eine Umgebungsvariable. Der read bezieht sich auf seinen Wert, wenn er Textsequenzen analysiert.
Wir verwenden die Option -r (Backslashes beibehalten) des read , um alle Backslashes zu ignorieren, die möglicherweise in den Daten enthalten sind. Sie werden als normale Zeichen behandelt.
Der Text, den der read analysiert, wird in einer Reihe von Variablen gespeichert, die nach den CSV-Feldern benannt sind. Sie hätten genauso gut field1, field2, ... field7 , aber aussagekräftige Namen erleichtern das Leben.
Die Daten werden als Ausgabe des tail Befehls erhalten. Wir verwenden tail , weil es uns eine einfache Möglichkeit gibt, die Kopfzeile der CSV-Datei zu überspringen. Die Option -n +2 (Zeilennummer) weist tail an, bei Zeile zwei mit dem Lesen zu beginnen.
Das Konstrukt <(...) wird Prozesssubstitution genannt. Es bewirkt, dass Bash die Ausgabe eines Prozesses akzeptiert, als käme sie von einem Dateideskriptor. Dieser wird dann in die while -Schleife umgeleitet und liefert den Text, den der read analysiert.
Machen Sie das Skript mit dem Befehl chmod ausführbar. Sie müssen dies jedes Mal tun, wenn Sie ein Skript aus diesem Artikel kopieren. Ersetzen Sie jeweils den Namen des entsprechenden Skripts.
chmod +x field.sh

Wenn wir das Skript ausführen, werden die Datensätze korrekt in ihre einzelnen Felder aufgeteilt, wobei jedes Feld in einer anderen Variablen gespeichert wird.
./field.sh
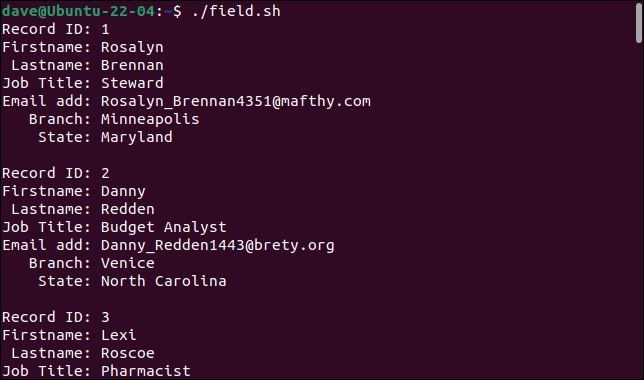
Jeder Datensatz wird als Satz von Feldern gedruckt.
Felder auswählen
Vielleicht wollen oder müssen wir nicht jedes Feld abrufen. Wir können eine Auswahl von Feldern erhalten, indem wir den cut Befehl einbauen.
Dieses Skript heißt „select.sh“.
#!/bin/bash while IFS="," read -r id jobtitle branch state tun echo "Datensatz-ID: $id" Echo "Jobtitel: $jobtitle" Echo "Zweig: $Zweig" Echo "Zustand: $Zustand" echo "" fertig < <(cut -d "," -f1,4,6,7 sample.csv | tail -n +2)
Wir haben den cut Befehl in die Prozesssubstitutionsklausel eingefügt. Wir verwenden die Option -d (Trennzeichen), um cut anzuweisen, Kommas „ , “ als Trennzeichen zu verwenden. Die Option -f (field) teilt cut mit, dass wir die Felder eins, vier, sechs und sieben haben wollen. Diese vier Felder werden in vier Variablen eingelesen, die im Hauptteil der while -Schleife ausgegeben werden.
Das bekommen wir, wenn wir das Skript ausführen.
./select.sh
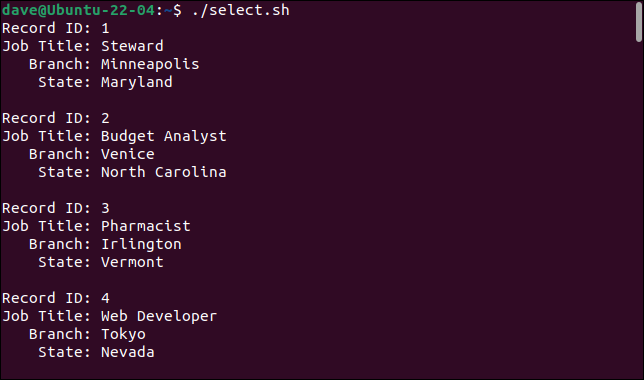
Durch Hinzufügen des cut Befehls können wir die gewünschten Felder auswählen und die nicht gewünschten Felder ignorieren.
So weit, ist es gut. Aber…
Wenn die CSV, mit der Sie es zu tun haben, unkompliziert ist und keine Kommas oder Anführungszeichen in Felddaten enthält, wird das, was wir behandelt haben, wahrscheinlich Ihre CSV-Parsing-Anforderungen erfüllen. Um die Probleme zu zeigen, auf die wir stoßen können, haben wir eine kleine Stichprobe der Daten so modifiziert, dass sie wie folgt aussehen.
ID, Vorname, Nachname, Berufsbezeichnung, E-Mail-Adresse, Branche, Bundesland 1, Rosalyn, Brennan, „Steward, Senior“, [email protected], Minneapolis, Maryland 2, Danny, Redden, „Analyst „Budget““, [email protected], Venedig, North Carolina 3, Lexi, Roscoe, Apotheker,, Irlington, Vermont
- Datensatz eins enthält ein Komma im
job-title, daher muss das Feld in Anführungszeichen gesetzt werden. - Datensatz zwei enthält ein Wort, das in zwei Sätze von Anführungszeichen im
jobs-titleFeld eingeschlossen ist. - Datensatz drei enthält keine Daten im
email-address.
Diese Daten wurden als „sample2.csv“ gespeichert. Ändern Sie Ihr „field.sh“-Skript so, dass es „sample2.csv“ aufruft, und speichern Sie es als „field2.sh“.
#! /bin/bash while IFS="," read -r id Vorname Nachname Jobtitel E-Mail Branche Status tun echo "Datensatz-ID: $id" echo "Vorname: $vorname" echo "Nachname: $lastname" Echo "Jobtitel: $jobtitle" echo "E-Mail hinzufügen: $email" Echo "Zweig: $Zweig" Echo "Zustand: $Zustand" echo "" fertig < <(tail -n +2 sample2.csv)
Wenn wir dieses Skript ausführen, können wir Risse in unseren einfachen CSV-Parsern sehen.

./field2.sh

Der erste Datensatz teilt das Berufsbezeichnungsfeld in zwei Felder auf, wobei der zweite Teil als E-Mail-Adresse behandelt wird. Jedes nachfolgende Feld wird um eine Stelle nach rechts verschoben. Das letzte Feld enthält sowohl die branch als auch die state .
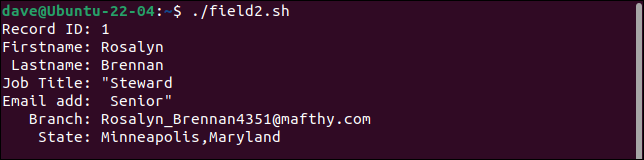
Der zweite Datensatz behält alle Anführungszeichen. Es sollte nur ein einziges Paar Anführungszeichen um das Wort „Budget“ stehen.
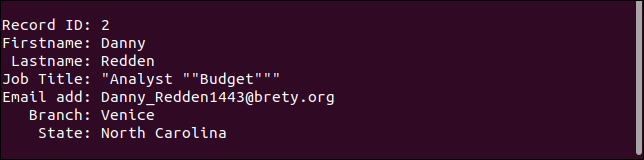
Der dritte Datensatz behandelt das fehlende Feld tatsächlich so, wie es sollte. Die E-Mail-Adresse fehlt, aber alles andere ist so, wie es sein sollte.

Im Gegensatz dazu ist es für ein einfaches Datenformat sehr schwierig, einen robusten CSV-Parser für allgemeine Fälle zu schreiben. Mit Tools wie awk kommen Sie näher heran, aber es gibt immer Grenzfälle und Ausnahmen, die durchschlüpfen.

Der Versuch, einen unfehlbaren CSV-Parser zu schreiben, ist wahrscheinlich nicht der beste Weg nach vorne. Ein alternativer Ansatz – insbesondere, wenn Sie an einer bestimmten Frist arbeiten – verwendet zwei verschiedene Strategien.
Eine besteht darin, ein speziell entwickeltes Tool zu verwenden, um Ihre Daten zu manipulieren und zu extrahieren. Die zweite besteht darin, Ihre Daten zu bereinigen und Problemszenarien wie eingebettete Kommas und Anführungszeichen zu ersetzen. Ihre einfachen Bash-Parser kommen dann mit der Bash-freundlichen CSV-Datei zurecht.
Das csvkit-Toolkit
Das CSV-Toolkit csvkit ist eine Sammlung von Dienstprogrammen, die speziell für die Arbeit mit CSV-Dateien erstellt wurden. Sie müssen es auf Ihrem Computer installieren.
Verwenden Sie diesen Befehl, um es unter Ubuntu zu installieren:
sudo apt installiert csvkit

Um es auf Fedora zu installieren, müssen Sie Folgendes eingeben:
sudo dnf installiere python3-csvkit

Auf Manjaro lautet der Befehl:
sudo pacman -S csvkit

Wenn wir ihm den Namen einer CSV-Datei übergeben, zeigt das Dienstprogramm csvlook eine Tabelle mit den Inhalten der einzelnen Felder an. Der Feldinhalt wird angezeigt, um zu zeigen, was der Feldinhalt darstellt, nicht wie er in der CSV-Datei gespeichert ist.
Lassen Sie uns csvlook mit unserer problematischen Datei „sample2.csv“ ausprobieren.
csvlook Beispiel2.csv
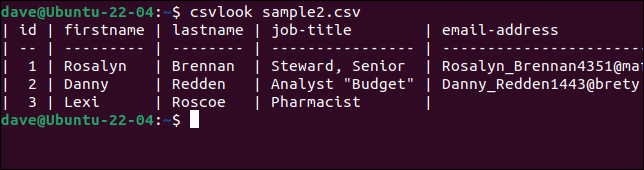
Alle Felder werden korrekt angezeigt. Dies beweist, dass das Problem nicht die CSV ist. Das Problem ist, dass unsere Skripte zu einfach sind, um die CSV-Datei richtig zu interpretieren.
Um bestimmte Spalten auszuwählen, verwenden Sie den Befehl csvcut . Die Option -c (Spalte) kann mit Feldnamen oder Spaltennummern oder einer Mischung aus beidem verwendet werden.
Angenommen, wir müssen die Vor- und Nachnamen, Berufsbezeichnungen und E-Mail-Adressen aus jedem Datensatz extrahieren, aber wir möchten die Namensreihenfolge als „Nachname, Vorname“ haben. Alles, was wir tun müssen, ist, die Feldnamen oder Nummern in der gewünschten Reihenfolge anzugeben.
Diese drei Befehle sind alle gleichwertig.
csvcut -c Nachname, Vorname, Berufsbezeichnung, E-Mail-Adresse sample2.csv
csvcut -c Nachname,Vorname,4,5 Beispiel2.csv
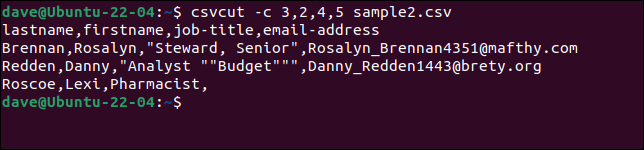
csvcut -c 3,2,4,5 sample2.csv
Wir können den Befehl csvsort hinzufügen, um die Ausgabe nach einem Feld zu sortieren. Wir verwenden die Option -c (Spalte), um die Spalte anzugeben, nach der sortiert werden soll, und die Option -r (umgekehrt), um in absteigender Reihenfolge zu sortieren.
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r
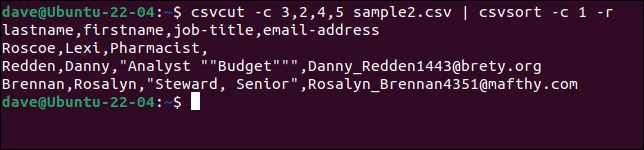
Um die Ausgabe schöner zu machen, können wir sie über csvlook .
csvcut -c 3,2,4,5 sample2.csv | csvsort -c 1 -r | csvlook
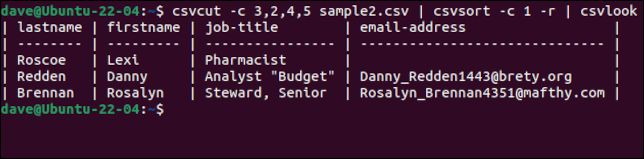
Eine nette Geste ist, dass, obwohl die Datensätze sortiert sind, die Kopfzeile mit den Feldnamen als erste Zeile beibehalten wird. Sobald wir zufrieden sind, dass wir die Daten so haben, wie wir sie haben wollen, können wir den csvlook aus der Befehlskette entfernen und eine neue CSV-Datei erstellen, indem wir die Ausgabe in eine Datei umleiten.
Wir haben der „sample2.file“ weitere Daten hinzugefügt, den csvsort Befehl entfernt und eine neue Datei namens „sample3.csv“ erstellt.
csvcut -c 3,2,4,5 Beispiel2.csv > Beispiel3.csv

Eine sichere Möglichkeit, CSV-Daten zu bereinigen
Wenn Sie eine CSV-Datei in LibreOffice Calc öffnen, wird jedes Feld in einer Zelle platziert. Sie können die Suchen- und Ersetzen-Funktion verwenden, um nach Kommas zu suchen. Sie könnten sie durch „nichts“ ersetzen, damit sie verschwinden, oder durch ein Zeichen, das die CSV-Analyse nicht beeinflusst, wie z. B. ein Semikolon „ ; " zum Beispiel.
Sie werden die Anführungszeichen um Felder in Anführungszeichen nicht sehen. Die einzigen Anführungszeichen, die Sie sehen werden, sind die eingebetteten Anführungszeichen in Felddaten . Diese werden als einfache Anführungszeichen dargestellt. Wenn Sie diese suchen und durch ein einzelnes Apostroph „ ' “ ersetzen, werden die doppelten Anführungszeichen in der CSV-Datei ersetzt.
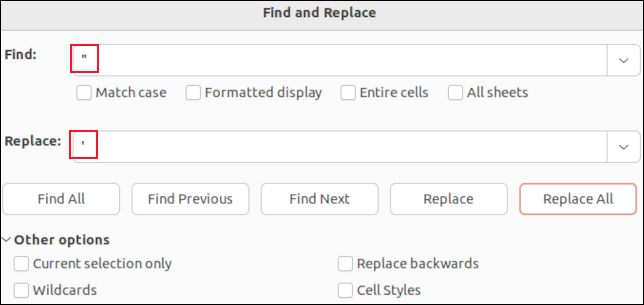
Das Suchen und Ersetzen in einer Anwendung wie LibreOffice Calc bedeutet, dass Sie nicht versehentlich eines der Feldtrennkommas oder die Anführungszeichen um Felder in Anführungszeichen löschen können. Sie ändern nur die Datenwerte von Feldern.
Wir haben alle Kommas in Feldern mit Semikolons und alle eingebetteten Anführungszeichen mit Apostrophen geändert und unsere Änderungen gespeichert.
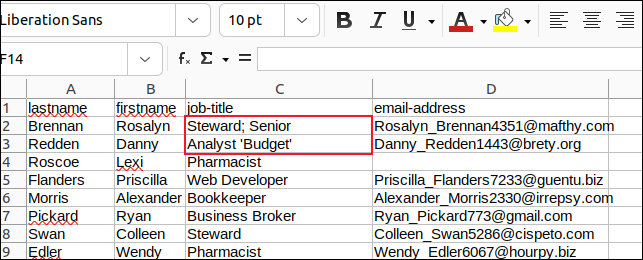
Wir haben dann ein Skript namens „field3.sh“ erstellt, um „sample3.csv“ zu parsen.
#! /bin/bash while IFS="," read -r Nachname Vorname Stellenbezeichnung E-Mail tun echo "Nachname: $lastname" echo "Vorname: $vorname" Echo "Jobtitel: $jobtitle" echo "E-Mail hinzufügen: $email" echo "" fertig < <(tail -n +2 sample3.csv)
Mal sehen, was wir bekommen, wenn wir es ausführen.
./field3.sh
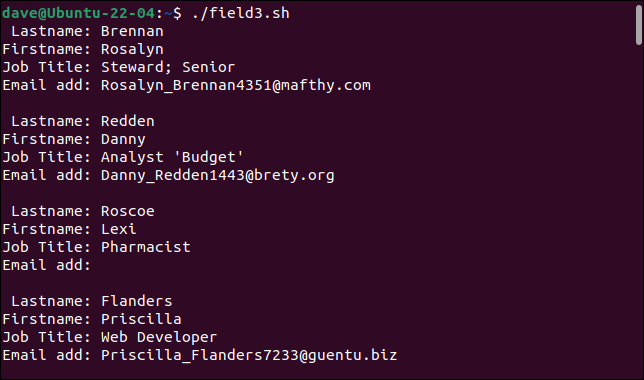
Unser einfacher Parser kann jetzt mit unseren zuvor problematischen Datensätzen umgehen.
Sie werden eine Menge CSV sehen
CSV kommt einer Umgangssprache für Anwendungsdaten wohl am nächsten. Die meisten Anwendungen, die irgendeine Form von Daten verarbeiten, unterstützen den Import und Export von CSV. Zu wissen, wie man CSV auf realistische und praktische Weise handhabt, wird Ihnen zugute kommen.
VERWANDT: 9 Bash-Skriptbeispiele für den Einstieg in Linux