
So vergleichen Sie Binärdateien unter Linux
Veröffentlicht: 2022-08-20
Wie können Sie überprüfen, ob zwei Linux-Binärdateien gleich sind? Wenn es sich um ausführbare Dateien handelt, können Unterschiede auf unerwünschtes oder böswilliges Verhalten hindeuten. Hier ist der einfachste Weg, um zu überprüfen, ob sie sich unterscheiden.
Vergleich von Binärdateien
Linux ist reich an Möglichkeiten zum Vergleichen und Analysieren von Textdateien. Der Befehl diff vergleicht zwei Dateien für Sie und hebt die Unterschiede hervor. Es kann sogar einige Zeilen auf beiden Seiten der Änderungen enthalten, um einen Kontext um die geänderten Zeilen herum bereitzustellen. Und der Befehl colordiff fügt Farbe hinzu, um die visuelle Analyse der Unterschiede noch einfacher zu machen.
Entwickler und Autoren verwenden diff , um die Unterschiede zwischen verschiedenen Versionen von Programmquellcodedateien oder Textentwürfen hervorzuheben. Es ist schnell und einfach, und Sie benötigen keine technischen Kenntnisse, um die Unterschiede zwischen Textzeichenfolgen zu erkennen.
In der Welt der Binärdateien sind die Dinge nicht so einfach. Binärdateien bestehen nicht aus Klartext. Sie bestehen aus vielen Bytes, die numerische Werte enthalten. Wenn es sich um eine komprimierte Datei wie ein TAR-Archiv oder eine ZIP-Datei handelt, stellen diese Werte die komprimierten Dateien dar, die in der Archivdatei gespeichert sind, zusammen mit den Symboltabellen, die für die Dekomprimierung und Extraktion der Dateien erforderlich sind.

Wenn die Binärdatei eine ausführbare Datei ist, werden die numerischen Werte der Bytes der Datei als solche Dinge wie Maschinencode-Anweisungen für die CPU, Metadaten, Labels oder codierte Daten interpretiert. Änderungen an einer Binärdatei oder einer Bibliotheksdatei führen wahrscheinlich zu unterschiedlichem Verhalten, wenn die Binärdatei ausgeführt oder von einer anderen Anwendung verwendet wird.
Es ist einfach, das Erstellungs- oder Änderungsdatum und die Uhrzeit einer Datei zu fälschen. Das bedeutet, dass es zwei Versionen einer Datei geben kann, die denselben Namen, dieselbe Dateigröße – wenn die Änderungen den vorhandenen Inhalt Byte für Byte ersetzen – und Datumsstempel haben. Und doch könnte eine der Dateien verändert worden sein.
Sichere Hash-Algorithmen
Ein sicherer Hash-Algorithmus ist ein mathematikbasierter Algorithmus. Es erstellt einen 64-Bit-Wert, indem es alle Bytes in einer Datei scannt und eine mathematische Transformation auf sie anwendet, um den Hash-Wert zu generieren. An jedem Tag wird dieselbe Datei immer denselben Hash erzeugen. Selbst ein Unterschied von einem Byte führt zu einem radikal anderen Hash.
Oft wird der Hash einer Datei auf der Download-Seite angezeigt. Sie sollten einen Hash für die Datei generieren, sobald Sie sie heruntergeladen haben. Wenn es sich von dem auf der Webseite angezeigten Hash unterscheidet, wissen Sie, dass die Datei kompromittiert ist. Sie wurde entweder manipuliert und durch die Originaldatei ersetzt – um Leute dazu zu bringen, die verfälschte Datei herunterzuladen – oder sie wurde während der Übertragung beschädigt.
Auf unserem Testcomputer haben wir zwei Kopien derselben Datei, eine gemeinsam genutzte Bibliothek. Die Dateien wurden umbenannt, sodass sie sich im selben Verzeichnis befinden können. Theoretisch sollten diese Dateien gleich sein. Schließlich sollen sie dieselbe Version der gemeinsam genutzten Bibliothek sein.
ls -l *.so

Die Dateien haben die gleiche Größe, die gleichen Datumsstempel und die gleichen Zeitstempel. Für den zufälligen Beobachter werden sie gleich aussehen. Lassen Sie uns den Befehl sha256sum verwenden und einen Hash für jede Datei generieren.
sha256sum binäre_Datei1.so
sha256sum binäre_Datei2.so
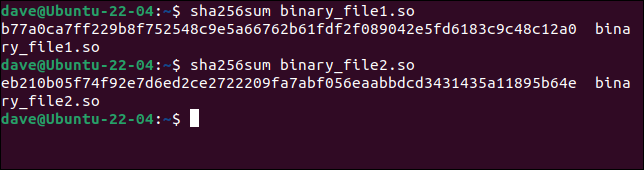
Die Hashes sind völlig unterschiedlich, was deutlich darauf hinweist, dass es Unterschiede zwischen den beiden Dateien gibt. Wenn die Website den Hash der Originaldatei anzeigt, können Sie die nicht übereinstimmende Datei verwerfen.
Die Unterschiede finden
Wenn Sie sich die Änderungen ansehen möchten, gibt es auch dafür Möglichkeiten. Sie müssen nicht in der Lage sein, die Datei zu dekompilieren oder Assembler- oder Maschinencode zu verstehen, nur um die Änderungen zu sehen. Um zu verstehen, was diese Änderungen bedeuten und was ihr Zweck ist, wären natürlich tiefere technische Kenntnisse erforderlich. Aber einfach zu wissen, wie umfangreich die Änderungen sind, kann Aufschluss darüber geben, was mit der Datei passiert ist.
Wenn wir diff auf die beiden Binärdateien anwenden, erhalten wir eine etwas enttäuschende Antwort.
diff binäre_datei1.so binäre_datei2.so

Wir wussten bereits, dass die Dateien unterschiedlich waren. Versuchen wir es mit cmp .
cmp binäre_datei1.so binäre_datei2.so

Das sagt uns ein bisschen mehr. Das erste Byte, das sich zwischen den beiden Dateien unterscheidet, ist Byte Nummer 13451. Das heißt, gezählt vom Anfang der Binärdatei, ist Byte 13451 in den beiden Binärdateien unterschiedlich. 13451 ist also der Offset der ersten Differenz vom Anfang der Datei.
Rein zufällig gibt es in der gesamten Datei Bytes, die den Hexadezimalwert 0x10 enthalten. Dies ist der Wert, den Linux in Textdateien als Zeilenendezeichen verwendet. Der cmp Befehl hat 131 Bytes mit diesem Wert zwischen dem Start der Binärdatei und der Position des ersten Unterschieds gefunden. Es denkt also, es ist auf Zeile 132. Es hat in diesem Zusammenhang wirklich nichts zu bedeuten.
Wenn wir die Option -l (verbose) hinzufügen, erhalten wir nützliche Informationen.

cmp -l Binärdatei1.so Binärdatei2.so
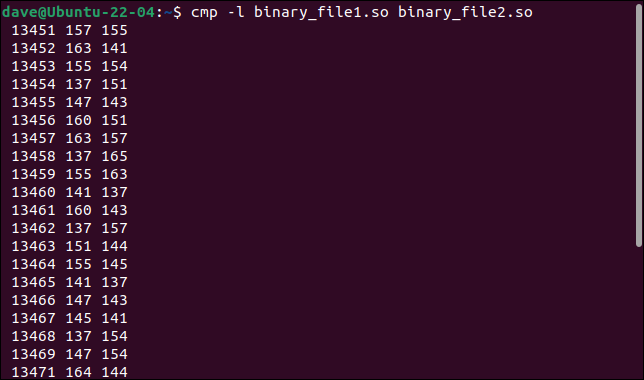
Alle abweichenden Bytes werden aufgelistet. Die Bytenummer oder der Offset, der Wert aus der ersten Datei und der Wert aus der zweiten Datei werden mit einem Byte pro Ausgabezeile angezeigt.
Die Bytewerte werden im Oktalformat angezeigt, anstatt im üblichen Hexadezimalformat, das bei Binärdateien verwendet wird. Trotzdem haben wir etwas anderes gelernt. Alle geänderten Bytes befinden sich in einer fortlaufenden Sequenz. Ihre Offsets werden für jedes Byte um eins erhöht.
Das hexdump -Tool gibt eine Binärdatei im Terminalfenster aus. Wenn wir die Option -C (kanonisch) verwenden, listet die Ausgabe in jeder Zeile den Offset, die Werte von 16 Bytes an diesem Offset und – falls vorhanden – die ASCII-Darstellung der Bytewerte auf.
hexdump -C binäre_Datei1.so
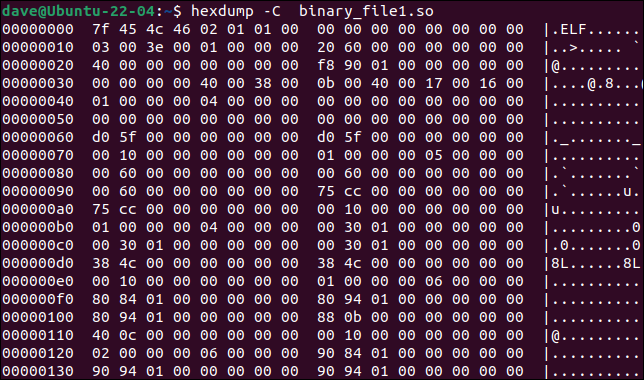
Wir können die Ausgabe von hexdump als Eingabe für diff verwenden und diff so arbeiten lassen, als würde es zwei Textdateien lesen.
diff <(hexdump binäre_datei1.so) <(hexdump binäre_datei2.so)
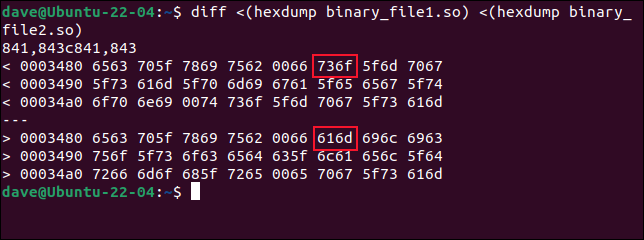
diff findet die unterschiedlichen Zeilen und zeigt die hexadezimalen Bytewerte aus der ersten Datei über den Werten aus der zweiten Datei. Der Offset der ersten Zeile ist 0x3480 oder 13440 dezimal. Zuvor teilte uns cmp mit, dass die erste Änderung bei Byte 13451 aufgetreten ist, das 0x348B ist. Das entspricht eigentlich dem, was wir hier sehen.
Die Ausgabe von diff erfolgt in Zwei-Byte-Blöcken. Das erste Bytepaar sind die Bytes 0 und 1 ab dem Offset von 0x3480, der zweite Block enthält die Bytes 2 und 3 ab dem Offset. Block 6 enthält die Bytes 0xA und 0xB oder 10 und 11 in Dezimalschreibweise. Das sind die Bytes 13450 und 13451. Und wir können sehen, dass dies die ersten Bytes sind, die sich unterscheiden. Die ersten fünf Bytepaare sind in beiden Dateien gleich.
Da diff jedoch von der Basis Null aus zählt, ist das, was cmp aufruft, Byte 13540 bis diff . Und um die Sache noch verwirrender zu machen, wird die Byte-Reihenfolge in jedem Zwei-Byte-Block durch diff umgekehrt. Die Bytes sind tatsächlich in dieser Reihenfolge aufgelistet: 1 und 0, 3 und 2, 5 und 4, 7 und 6 und so weiter.
Der Befehl ist auch rechenintensiv – zwei hexdumps und ein diff auf einmal – besonders, wenn die verglichenen Dateien groß sind.
Aber wenn hexdump -C eine ASCII-Version der Binärdatei an das Terminalfenster senden kann, warum leiten wir die Ausgabe nicht in Textdateien um und vergleichen dann diese beiden Textdateien mit diff ?
hexdump -C Binäre_Datei1.so > Binäre1.txt
hexdump -C Binäre_Datei2.so > Binäre2.txt
diff binär1.txt binär2.txt
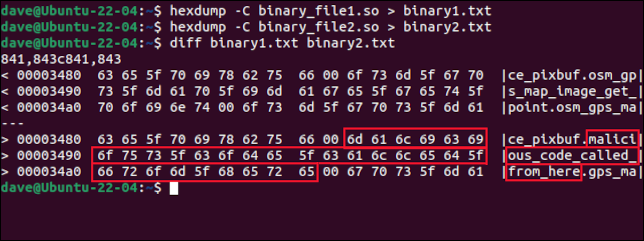
Der Unterschied zwischen den beiden Dateien wird in zwei kurzen Ausschnitten dargestellt. Daneben befindet sich eine ASCII-Darstellung. Es wird ein Paar Auszüge für jeden Unterschied zwischen den Dateien geben. In diesem Beispiel gibt es nur einen Unterschied.
Das ist alles sehr schön, aber wäre es nicht großartig, wenn es etwas gäbe, das all das für Sie tun würde?
VBinDiff
Das Programm VBinDiff kann aus den üblichen Repositories für alle wichtigen Distributionen installiert werden. Verwenden Sie diesen Befehl, um es unter Ubuntu zu installieren:
sudo apt installiere vbindiff

Auf Fedora müssen Sie Folgendes eingeben:
sudo dnf installiere vbindiff

Manjaro-Benutzer müssen pacman verwenden.
sudo pacman -Sy vbindiff

Um das Programm zu verwenden, übergeben Sie den Namen der beiden Binärdateien in der Befehlszeile.
vbindiff binäre_datei1.so binäre_datei2.so

Die terminalbasierte Anwendung wird geöffnet und zeigt beide Dateien in einer Bildlaufansicht.
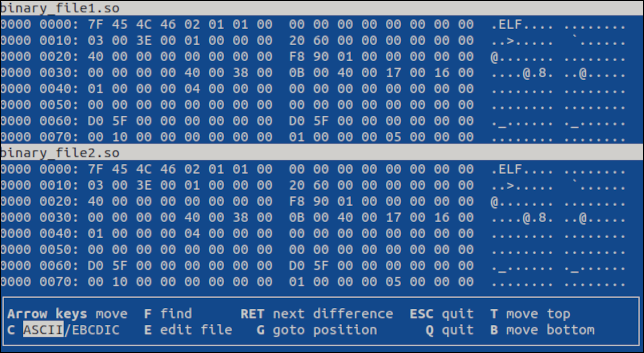
Sie können das Scrollrad der Maus oder die Tasten „Pfeil nach oben“, „Pfeil nach unten“, „Pos1“, „Ende“, „Bild auf“ und „Bild ab“ verwenden, um sich durch die Dateien zu bewegen. Beide Dateien scrollen.
Drücken Sie die „Enter“-Taste, um zum ersten Unterschied zu springen. Der Unterschied wird in beiden Dateien hervorgehoben.
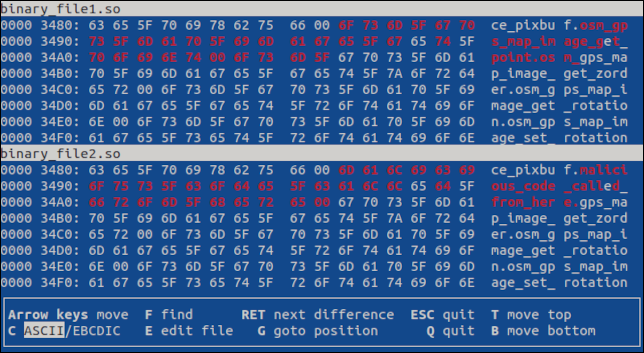
Wenn es mehr Unterschiede gäbe, würde das Drücken von „Enter“ den nächsten Unterschied anzeigen. Durch Drücken von „q“ oder „Esc“ wird das Programm beendet.
Was ist der Unterschied?
Wenn Sie an einem Computer arbeiten, der jemand anderem gehört, und Sie keine Pakete installieren dürfen, können Sie cmp , diff und hexdump verwenden. Wenn Sie die Ausgabe zur weiteren Verarbeitung erfassen müssen, sind dies auch die Tools, die Sie verwenden sollten.
Aber wenn Sie Pakete installieren dürfen, macht VBinDiff Ihren Arbeitsablauf einfacher und schneller. Und tatsächlich ist die Verwendung von VBinDiff mit einer einzelnen Binärdatei eine einfache und bequeme Möglichkeit, Binärdateien zu durchsuchen, was ein netter Bonus ist.
VERWANDT: So können Sie von der Linux-Befehlszeile aus in Binärdateien blicken