
كيفية تحليل بيانات CSV في Bash
نشرت: 2022-09-16
تعد ملفات القيم المفصولة بفواصل (CSV) واحدة من أكثر التنسيقات شيوعًا للبيانات المصدرة. في نظام Linux ، يمكننا قراءة ملفات CSV باستخدام أوامر Bash. لكن يمكن أن يصبح الأمر معقدًا للغاية وبسرعة كبيرة. سوف نقدم يد المساعدة.
ما هو ملف CSV؟
ملف القيم المفصولة بفواصل هو ملف نصي يحتفظ ببيانات مجدولة. CSV هو نوع من البيانات المحددة. كما يوحي الاسم ، تُستخدم الفاصلة " , " لفصل كل حقل من حقول البيانات - أو القيمة - عن جيرانها.
CSV في كل مكان. إذا كان التطبيق يحتوي على وظائف الاستيراد والتصدير ، فسيدعم دائمًا تنسيق CSV. ملفات CSV قابلة للقراءة من قبل الإنسان. يمكنك النظر بداخلها بأقل قدر ، وفتحها في أي محرر نصوص ، ونقلها من برنامج إلى آخر. على سبيل المثال ، يمكنك تصدير البيانات من قاعدة بيانات SQLite وفتحها في LibreOffice Calc.
ومع ذلك ، يمكن أن يصبح حتى CSV معقدًا. تريد أن يكون لديك فاصلة في حقل البيانات؟ يحتاج هذا الحقل إلى التفاف حوله علامات اقتباس " " . لتضمين علامات اقتباس في حقل ، يجب إدخال كل علامة اقتباس مرتين.
بالطبع ، إذا كنت تعمل باستخدام ملف CSV تم إنشاؤه بواسطة برنامج أو برنامج نصي قمت بكتابته ، فمن المحتمل أن يكون تنسيق CSV بسيطًا ومباشرًا. إذا كنت مضطرًا للعمل مع تنسيقات CSV أكثر تعقيدًا ، حيث أن Linux هو Linux ، فهناك حلول يمكننا استخدامها لذلك أيضًا.
بعض عينات البيانات
يمكنك بسهولة إنشاء بعض عينات بيانات CSV ، باستخدام مواقع مثل Online Data Generator. يمكنك تحديد الحقول التي تريدها واختيار عدد صفوف البيانات التي تريدها. يتم إنشاء بياناتك باستخدام قيم وهمية واقعية ويتم تنزيلها على جهاز الكمبيوتر الخاص بك.
أنشأنا ملفًا يحتوي على 50 صفًا من معلومات الموظف الوهمية:
- المعرّف : قيمة عدد صحيح فريد بسيط.
- الاسم الأول: الاسم الأول للشخص.
- Lastname : الاسم الأخير للشخص.
- المسمى الوظيفي : المسمى الوظيفي للشخص.
- عنوان البريد الإلكتروني: عنوان البريد الإلكتروني للشخص.
- الفرع : فرع الشركة الذي يعملون فيه.
- الولاية : الولاية التي يقع فيها الفرع.
تحتوي بعض ملفات CSV على سطر رأس يسرد أسماء الحقول. ملف العينة لدينا يحتوي على واحد. هذا هو الجزء العلوي من ملفنا:
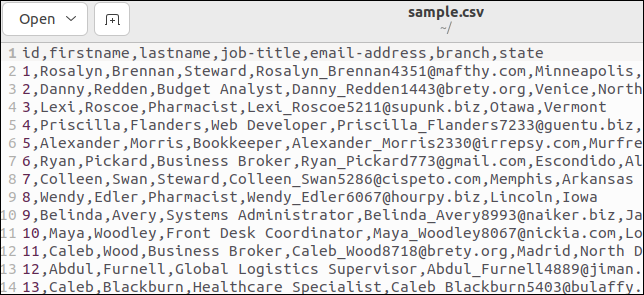
يحمل السطر الأول أسماء الحقول كقيم مفصولة بفواصل.
تحليل البيانات من ملف CSV
لنكتب نصًا يقرأ ملف CSV ويستخرج الحقول من كل سجل. انسخ هذا النص في محرر ، واحفظه في ملف يسمى "field.sh."
#! / بن / باش while IFS = "،" قراءة -r id الاسم الأخير اسم الوظيفة عنوان البريد الإلكتروني حالة الفرع فعل صدى "معرف السجل: $ id" صدى "الاسم الأول: $ الاسم الأول" صدى "Lastname: $ lastname" صدى "Job Title: $ jobtitle" صدى "Email add: $ email" صدى "الفرع: $ الفرع" صدى "State: $ state" صدى صوت "" تم <<(tail -n +2 sample.csv)
هناك الكثير من الأشياء المعبأة في نصنا الصغير. دعونا نكسرها.

نحن نستخدم حلقة while loop. طالما تحل شرط حلقة while إلى true ، فسيتم تنفيذ جسم حلقة while . جسم الحلقة بسيط للغاية. يتم استخدام مجموعة من عبارات echo لطباعة قيم بعض المتغيرات إلى النافذة الطرفية.
حالة حلقة while هي أكثر إثارة للاهتمام من جسم الحلقة. نحدد أنه يجب استخدام الفاصلة كفاصل داخلي للحقل ، مع عبارة IFS="," . IFS هو متغير البيئة. يشير الأمر read إلى قيمته عند تحليل تسلسل النص.
نحن نستخدم خيار الأمر read 's -r (الاحتفاظ بالشرط المائلة العكسية) لتجاهل أي خطوط مائلة عكسية قد تكون موجودة في البيانات. سيتم التعامل معهم كشخصيات عادية.
يتم تخزين النص الذي يوزع أمر read في مجموعة من المتغيرات المسماة باسم حقول CSV. كان من الممكن بسهولة تسميتها حقل 1 ، field1, field2, ... field7 ، لكن الأسماء ذات المعنى تجعل الحياة أسهل.
يتم الحصول على البيانات كناتج من أمر tail . نحن نستخدم tail لأنه يعطينا طريقة بسيطة لتخطي سطر رأس ملف CSV. يخبر الخيار -n +2 (رقم السطر) tail ببدء القراءة عند السطر الثاني.
بناء <(...) يسمى استبدال العملية. يتسبب في قبول Bash لمخرجات العملية كما لو كانت قادمة من واصف ملف. ثم يتم إعادة توجيه هذا إلى حلقة while ، مما يوفر النص الذي سيحلله أمر read .
اجعل البرنامج النصي قابلاً للتنفيذ باستخدام الأمر chmod . ستحتاج إلى القيام بذلك في كل مرة تقوم فيها بنسخ برنامج نصي من هذه المقالة. استبدل اسم البرنامج النصي المناسب في كل حالة.
chmod + x field.sh

عندما نقوم بتشغيل البرنامج النصي ، يتم تقسيم السجلات بشكل صحيح إلى الحقول المكونة لها ، مع تخزين كل حقل في متغير مختلف.
./field.sh
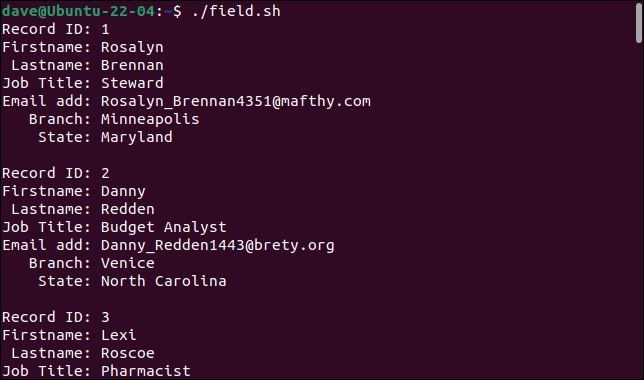
تتم طباعة كل سجل كمجموعة من الحقول.
اختيار الحقول
ربما لا نريد أو نحتاج إلى استرداد كل حقل. يمكننا الحصول على مجموعة مختارة من الحقول من خلال دمج أمر cut .
يسمى هذا البرنامج النصي "select.sh".
#! / بن / باش بينما IFS = "،" حالة فرع عنوان الوظيفة قراءة -r فعل صدى "معرف السجل: $ id" صدى "Job Title: $ jobtitle" صدى "الفرع: $ الفرع" صدى "State: $ state" صدى صوت "" تم <<(قص -d "،" -f1،4،6،7 sample.csv | tail -n +2)
لقد أضفنا الأمر cut إلى عبارة استبدال العملية. نحن نستخدم الخيار -d (المحدد) لإخبار cut باستخدام الفاصلات " , " كمحدد. يخبر الخيار -f (الحقل) cut أننا نريد الحقول واحد وأربعة وستة وسبعة. تتم قراءة هذه الحقول الأربعة في أربعة متغيرات ، والتي تتم طباعتها في جسم الحلقة while .
هذا ما نحصل عليه عندما نقوم بتشغيل البرنامج النصي.
./select.sh
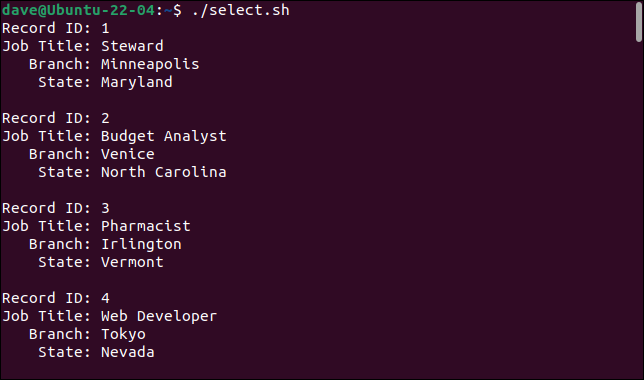
بإضافة الأمر cut ، يمكننا تحديد الحقول التي نريدها وتجاهل الحقول التي لا نريدها.
حتى الان جيدة جدا. ولكن…
إذا كان ملف CSV الذي تتعامل معه غير معقد بدون فواصل أو علامات اقتباس في بيانات الحقل ، فمن المحتمل أن يلبي ما قمنا بتغطيته احتياجات تحليل CSV الخاصة بك. لإظهار المشاكل التي يمكن أن نواجهها ، قمنا بتعديل عينة صغيرة من البيانات لتبدو هكذا.
المعرف ، الاسم الأول ، الاسم الأخير ، المسمى الوظيفي ، عنوان البريد الإلكتروني ، الفرع ، الولاية 1 ، روزالين ، برينان ، "ستيوارد ، كبير" ، Rosalyn_Brennan4351 @ mafthy.com ، مينيابوليس ، ميريلاند 2، Danny، Redden، "Analyst" "Budget" ""، Danny_Redden1443 @ brety.org، Venice، North Carolina 3 ، ليكسي ، روسكو ، صيدلي ، ، إيرلينجتون ، فيرمونت
- يحتوي السجل الأول على فاصلة في حقل
job-title، لذلك يجب التفاف الحقل بين علامتي اقتباس. - يحتوي السجل الثاني على كلمة ملفوفة في مجموعتين من علامات الاقتباس في حقل
jobs-titleالوظيفة. - السجل الثالث لا يحتوي على بيانات في حقل
email-address.
تم حفظ هذه البيانات باسم "sample2.csv." قم بتعديل البرنامج النصي "field.sh" لاستدعاء "sample2.csv" ، واحفظه باسم "field2.sh".
#! / بن / باش while IFS = "،" قراءة -r id الاسم الأخير اسم الوظيفة عنوان البريد الإلكتروني حالة الفرع فعل صدى "معرف السجل: $ id" صدى "الاسم الأول: $ الاسم الأول" صدى "Lastname: $ lastname" صدى "Job Title: $ jobtitle" صدى "Email add: $ email" صدى "الفرع: $ الفرع" صدى "State: $ state" صدى صوت "" تم <<(tail -n +2 sample2.csv)
عندما نقوم بتشغيل هذا البرنامج النصي ، يمكننا أن نرى تشققات تظهر في محللات CSV البسيطة.

./field2.sh

يقسم السجل الأول حقل المسمى الوظيفي إلى حقلين ، ويتعامل مع الجزء الثاني على أنه عنوان البريد الإلكتروني. يتم نقل كل حقل بعد ذلك مكانًا واحدًا إلى اليمين. يحتوي الحقل الأخير على قيم branch state .
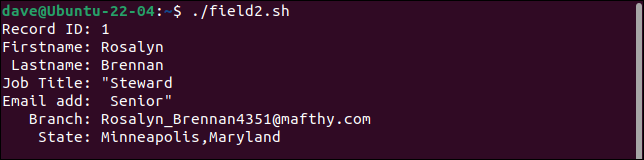
يحتفظ السجل الثاني بكافة علامات الاقتباس. يجب أن تحتوي على زوج واحد فقط من علامات الاقتباس حول كلمة "الميزانية".
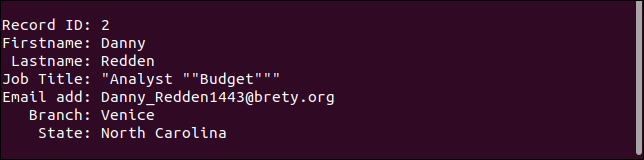
السجل الثالث يعالج الحقل المفقود كما ينبغي. عنوان البريد الإلكتروني مفقود ، ولكن كل شيء آخر كما ينبغي أن يكون.

بشكل غير متوقع ، بالنسبة لتنسيق البيانات البسيط ، من الصعب جدًا كتابة محلل CSV قوي للحالة العامة. ستتيح لك أدوات مثل awk الاقتراب ، ولكن هناك دائمًا حالات حافة واستثناءات تنزلق من خلالها.

ربما لا تكون محاولة كتابة محلل CSV معصوم أفضل طريقة للمضي قدمًا. نهج بديل - خاصة إذا كنت تعمل على موعد نهائي من نوع ما - يستخدم استراتيجيتين مختلفتين.
الأول هو استخدام أداة مصممة لغرض معالجة واستخراج البيانات الخاصة بك. والثاني هو تعقيم البيانات الخاصة بك واستبدال سيناريوهات المشكلة مثل الفواصل المضمنة وعلامات الاقتباس. يمكن لمحللي Bash البسطاء بعد ذلك التعامل مع ملف CSV المناسب لـ Bash.
مجموعة أدوات csvkit
مجموعة أدوات CSV csvkit عبارة عن مجموعة من الأدوات المساعدة التي تم إنشاؤها صراحةً للمساعدة في العمل مع ملفات CSV. ستحتاج إلى تثبيته على جهاز الكمبيوتر الخاص بك.
لتثبيته على Ubuntu ، استخدم هذا الأمر:
sudo apt تثبيت csvkit

لتثبيته على Fedora ، تحتاج إلى كتابة:
sudo dnf تثبيت python3-csvkit

في Manjaro ، يكون الأمر:
sudo pacman -S csvkit

إذا مررنا اسم ملف CSV إليه ، فستعرض الأداة المساعدة csvlook جدولًا يوضح محتويات كل حقل. يتم عرض محتوى الحقل لإظهار ما تمثله محتويات الحقل ، وليس كما هي مخزنة في ملف CSV.
لنجرب csvlook مع ملف "sample2.csv" الإشكالي.
ملف csvlook sample2.csv
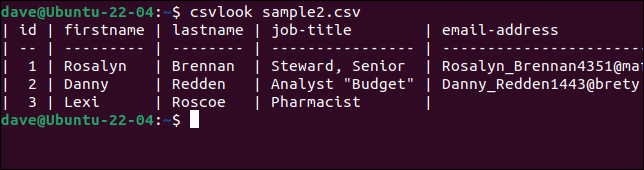
يتم عرض جميع الحقول بشكل صحيح. هذا يثبت أن المشكلة ليست في ملف CSV. المشكلة هي أن نصوصنا مبسطة للغاية بحيث لا يمكن تفسير ملف CSV بشكل صحيح.
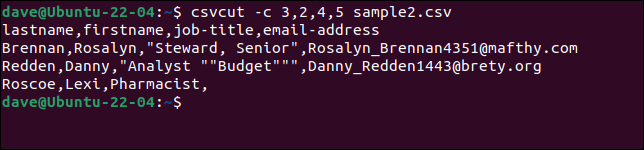
لتحديد أعمدة معينة ، استخدم الأمر csvcut . يمكن استخدام الخيار -c (عمود) مع أسماء الحقول أو أرقام الأعمدة ، أو مزيج من الاثنين معًا.
لنفترض أننا بحاجة إلى استخراج الاسمين الأول والأخير ، والمسميات الوظيفية ، وعناوين البريد الإلكتروني من كل سجل ، لكننا نريد الحصول على ترتيب الاسم كـ "اسم العائلة ، الاسم الأول". كل ما نحتاجه هو وضع أسماء الحقول أو الأرقام بالترتيب الذي نريده.
هذه الأوامر الثلاثة كلها متكافئة.
csvcut -c اسم العائلة ، الاسم الأول ، المسمى الوظيفي ، عنوان البريد الإلكتروني sample2.csv
csvcut -c اسم العائلة ، الاسم الأول ، 4،5 sample2.csv
csvcut -c 3،2،4،5 sample2.csv
يمكننا إضافة الأمر csvsort لفرز الإخراج حسب الحقل. نحن نستخدم الخيار -c (عمود) لتحديد العمود الذي سيتم الفرز وفقًا له ، وخيار -r (عكسي) للفرز بترتيب تنازلي.
csvcut -c 3،2،4،5 sample2.csv | csvsort -c 1 -r
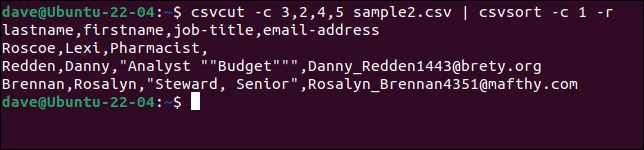
لجعل الإخراج أجمل يمكننا إطعامه من خلال csvlook .
csvcut -c 3،2،4،5 sample2.csv | csvsort -c 1 -r | csvlook
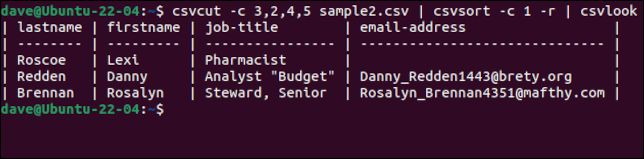
اللمسة الرائعة هي أنه على الرغم من فرز السجلات ، يتم الاحتفاظ بسطر العنوان بأسماء الحقول كسطر أول. بمجرد أن نكون سعداء بالحصول على البيانات بالطريقة التي نريدها ، يمكننا إزالة ملف csvlook من سلسلة الأوامر ، وإنشاء ملف CSV جديد عن طريق إعادة توجيه الإخراج إلى ملف.
أضفنا المزيد من البيانات إلى "sample2.file" ، وأزلنا الأمر csvsort ، وأنشأنا ملفًا جديدًا يسمى "sample3.csv".
csvcut -c 3،2،4،5 sample2.csv> sample3.csv

طريقة آمنة لتعقيم بيانات CSV
إذا فتحت ملف CSV في LibreOffice Calc ، فسيتم وضع كل حقل في خلية. يمكنك استخدام وظيفة البحث والاستبدال للبحث عن الفواصل. يمكنك استبدالها بـ "لا شيء" حتى تختفي ، أو بحرف لن يؤثر على تحليل CSV ، مثل الفاصلة المنقوطة " ; " فمثلا.
لن ترى علامات الاقتباس حول الحقول المقتبسة. علامات الاقتباس الوحيدة التي ستراها هي علامات الاقتباس المضمنة داخل بيانات الحقل. يتم عرض هذه كعلامات اقتباس مفردة. سيؤدي البحث عن هذه العلامات واستبدالها بعلامة اقتباس أحادية واحدة ' " إلى استبدال علامات الاقتباس المزدوجة في ملف CSV.
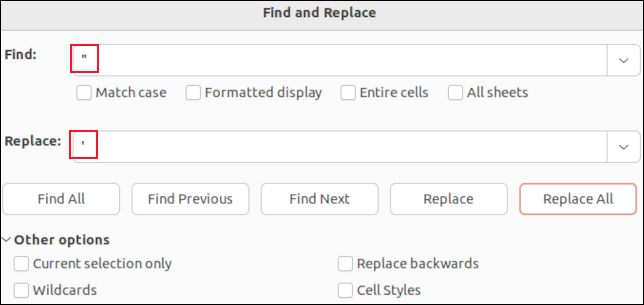
يعني إجراء البحث والاستبدال في تطبيق مثل LibreOffice Calc أنه لا يمكنك حذف أي من فواصل فواصل الحقول بطريق الخطأ ، أو حذف علامات الاقتباس حول الحقول بين علامات الاقتباس. ستقوم فقط بتغيير قيم بيانات الحقول.
قمنا بتغيير جميع الفواصل في الحقول التي تحتوي على فواصل منقوطة وجميع علامات الاقتباس المضمنة بفواصل عليا وحفظنا التغييرات التي أجريناها.
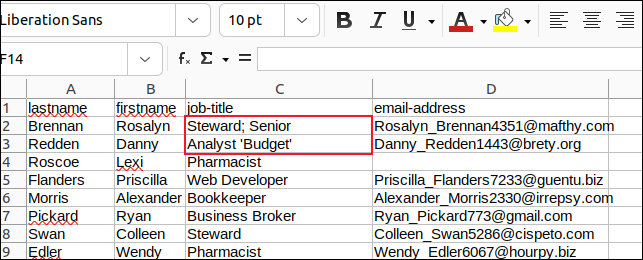
ثم أنشأنا نصًا برمجيًا يسمى "field3.sh" لتحليل "sample3.csv."
#! / بن / باش بينما IFS = "،" قراءة -r البريد الإلكتروني لوظيفة الاسم الأخير للاسم الأخير فعل صدى "Lastname: $ lastname" صدى "الاسم الأول: $ الاسم الأول" صدى "Job Title: $ jobtitle" صدى "Email add: $ email" صدى صوت "" تم <<(tail -n +2 sample3.csv)
دعونا نرى ما نحصل عليه عندما نقوم بتشغيله.
./field3.sh
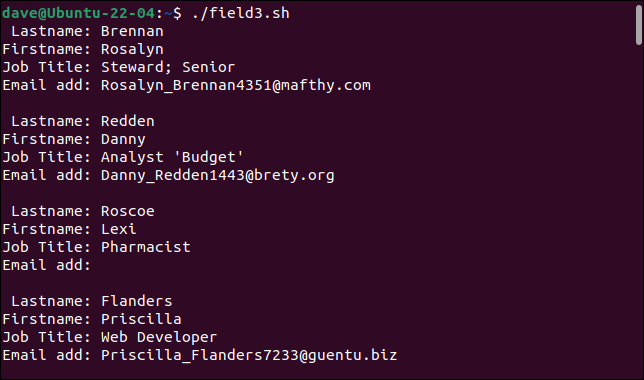
يمكن للمحلل اللغوي البسيط لدينا الآن التعامل مع سجلاتنا المسببة للمشاكل سابقًا.
سترى الكثير من CSV
يمكن القول إن CSV هو أقرب شيء إلى لغة مشتركة لبيانات التطبيق. تدعم معظم التطبيقات التي تتعامل مع بعض أشكال البيانات استيراد وتصدير CSV. إن معرفة كيفية التعامل مع ملف CSV - بطريقة واقعية وعملية - سوف يجعلك في وضع جيد.
ذات صلة: 9 أمثلة على Bash Script لتبدأ على Linux