
كيفية تحليل النص
نشرت: 2022-10-15
إذا كنت قد تعلمت بعض لغات برمجة الكمبيوتر ، فربما تكون قد سمعت مصطلح تحليل النص. يستخدم هذا لتبسيط قيم البيانات المعقدة للملف. تساعدك المقالة في معرفة كيفية تحليل النص باستخدام اللغة. بالإضافة إلى ذلك ، إذا واجهت خطأ في تحليل النص x ، فستعرف كيفية إصلاح خطأ التحليل في المقالة.
محتويات
- كيفية تحليل النص
- ما هو اعراب النص؟
- البرمجة اللغوية العصبية أو معالجة اللغة الطبيعية
- ما هو اعراب النص؟
- ما هي أسباب تحليل النص؟
- الطريقة 1: من خلال فئة DataFrame
- الطريقة الثانية: من خلال كلمة رمزية
- الطريقة الثالثة: من خلال فئة DocParser
- الطريقة الرابعة: من خلال أداة تحليل النص
- الطريقة الخامسة: من خلال TextFieldParser (Visual Basic)
- نصيحة للمحترفين: كيفية تحليل النص من خلال MS Excel
- كيفية إصلاح خطأ التحليل
كيفية تحليل النص
لقد أظهرنا في هذه المقالة دليلاً كاملاً لتحليل النص من خلال طرق مختلفة وقدمنا أيضًا مقدمة موجزة عن تحليل النص.
ما هو اعراب النص؟
قبل الخوض في معرفة مفاهيم تحليل النص باستخدام أي كود. من المهم معرفة أساسيات اللغة والترميز.
البرمجة اللغوية العصبية أو معالجة اللغة الطبيعية
لتحليل النص ، يتم استخدام معالجة اللغة الطبيعية أو البرمجة اللغوية العصبية ، وهو مجال فرعي من مجال الذكاء الاصطناعي. تُستخدم لغة Python ، وهي إحدى اللغات التي تنتمي إلى الفئة ، لتحليل النص.
تُمكِّن رموز البرمجة اللغوية العصبية أجهزة الكمبيوتر من فهم ومعالجة اللغات البشرية لجعلها مناسبة للتطبيقات المختلفة. لتطبيق تقنيات ML أو Machine Learning على اللغة ، يجب تحويل بيانات النص غير المهيكلة إلى بيانات جدولية منظمة. لاستكمال نشاط التحليل ، يتم استخدام لغة Python لتغيير أكواد البرنامج.
ما هو اعراب النص؟
يعني تحليل النص ببساطة تحويل البيانات من تنسيق إلى تنسيق آخر. يجب تحليل التنسيق الذي يتم حفظ الملف به أو تحويله إلى ملف بتنسيق مختلف لتمكين المستخدم من استخدامه في تطبيقات مختلفة.
- بمعنى آخر ، تعني العملية تحليل السلسلة أو النص والتحويل إلى مكونات منطقية عن طريق تغيير تنسيق الملف.
- يتم استخدام بعض قواعد لغة Python لإكمال مهمة البرمجة الشائعة هذه. أثناء تحليل النص ، يتم تقسيم سلسلة النص المحددة إلى مكونات أصغر.
ما هي أسباب تحليل النص؟
يتم تقديم الأسباب التي من أجلها يجب تحليل النص في هذا القسم وهي معرفة مطلوبة مسبقًا قبل معرفة كيفية تحليل النص.
- لن تكون جميع البيانات المحوسبة بنفس التنسيق وقد تختلف وفقًا للتطبيقات المختلفة.
- تختلف تنسيقات البيانات لتطبيقات مختلفة وقد يؤدي وجود رمز غير متوافق إلى هذا الخطأ.
- لا يوجد برنامج كمبيوتر عالمي فردي لاختيار بيانات جميع تنسيقات البيانات.
الطريقة 1: من خلال فئة DataFrame
تحتوي فئة DataFrame للغة Python على جميع الوظائف المطلوبة لتحليل النص. تضم هذه المكتبة المدمجة الرموز اللازمة لتحليل البيانات من أي تنسيق إلى تنسيق آخر.
مقدمة موجزة لفئة DataFrame
فئة DataFrame هي بنية بيانات غنية بالميزات ، تُستخدم كأداة لتحليل البيانات. هذه أداة قوية لتحليل البيانات يمكن استخدامها لتحليل البيانات بأقل جهد.
- تتم قراءة الكود في pandas DataFrame لإجراء التحليل بلغة Python.
- يأتي الفصل مزودًا بالعديد من الحزم التي تقدمها حيوانات الباندا والتي يستخدمها محللو بيانات Python.
- ميزة هذه الفئة هي تجريد ، رمز يتم فيه إخفاء الوظيفة الداخلية للوظيفة عن المستخدمين ، في مكتبة NumPy. مكتبة NumPy هي مكتبة بيثون تضم أوامر ووظائف للعمل مع المصفوفات.
- يمكن استخدام فئة DataFrame لتقديم مصفوفة ثنائية الأبعاد مع فهارس صفوف وأعمدة متعددة. تساعد هذه المؤشرات في تخزين البيانات متعددة الأبعاد ، وبالتالي يطلق عليها MultiIndex. يجب تغيير هذه لمعرفة كيفية إصلاح خطأ التحليل.
تساعد الباندا الخاصة بلغة Python في إجراء عمليات على غرار SQL أو قاعدة البيانات بأقصى قدر من الكمال لتجنب الخطأ في تحليل النص x. يحتوي أيضًا على بعض أدوات الإدخال والإخراج التي تساعد في تحليل ملفات CSV و MS Excel و JSON و HDF5 وتنسيقات البيانات الأخرى.
اقرأ أيضًا: حدث خطأ في الإصلاح أثناء محاولة طلب الوكيل
عملية تحليل النص باستخدام فئة DataFrame
لمعرفة كيفية تحليل النص ، يمكنك استخدام العملية القياسية باستخدام فئة DataFrame الواردة في هذا القسم.
- فك تنسيق البيانات لبيانات الإدخال.
- حدد بيانات إخراج البيانات مثل CSV أو قيمة مفصولة بفاصلة .
- اكتب على الكود نوع بيانات بدائي مثل قائمة أو ديكت.
ملاحظة: كتابة الكود على DataFrame فارغ يمكن أن تكون مملة ومعقدة. تسمح الباندا بإنشاء البيانات في فئة DataFrame من أنواع البيانات هذه. وبالتالي ، يمكن بسهولة تحليل البيانات الموجودة في نوع البيانات الأولية إلى تنسيق البيانات المطلوب.
- تحليل البيانات باستخدام أداة تحليل البيانات ، pandas DataFrame ، وطباعة النتيجة.
الخيار الأول: تنسيق قياسي
يتم شرح الطريقة القياسية لتنسيق أي ملف بتنسيق بيانات معين مثل CSV هنا.
- احفظ الملف بقيم البيانات محليًا على جهاز الكمبيوتر الخاص بك. على سبيل المثال ، يمكنك تسمية الملف data.txt .
- استيراد الملف في الباندا باسم محدد واستيراد البيانات إلى متغير آخر. على سبيل المثال ، يتم استيراد حيوانات الباندا للغة إلى الاسم pd في الكود المحدد.
- يجب أن يحتوي الاستيراد على رمز كامل مع تفاصيل اسم ملف الإدخال والوظيفة وتنسيق ملف الإدخال.
ملاحظة: هنا ، يتم استخدام المتغير المسمى res لأداء وظيفة قراءة البيانات في ملف data.txt باستخدام الباندا المستوردة في pd . يتم تحديد تنسيق البيانات لنص الإدخال بتنسيق CSV .
- اتصل بنوع الملف المسمى وتحليل النص الذي تم تحليله في النتيجة المطبوعة. على سبيل المثال ، سيساعد الأمر res بعد تنفيذ سطر الأوامر في طباعة النص الذي تم تحليله.
يرد أدناه مثال على رمز للعملية الموضحة أعلاه وسيساعد في فهم كيفية تحليل النص.
استيراد الباندا كما pd
الدقة = pd.read_csv ('data.txt')
الدقةفي هذه الحالة ، إذا أدخلت قيم البيانات في ملف data.txt مثل [1،2،3] ، فسيتم تحليلها وعرضها على شكل 1 2 3 .
الخيار الثاني: أسلوب السلسلة
إذا كان النص المعطى للكود يحتوي فقط على سلاسل أو أحرف ألفا ، فيمكن استخدام الأحرف الخاصة في السلسلة مثل الفواصل ، والمسافة ، وما إلى ذلك ، لفصل النص وتحليله. تشبه هذه العملية عمليات السلسلة الداخلية الشائعة. للعثور على كيفية إصلاح خطأ التحليل ، يجب عليك اتباع عملية تحليل النص باستخدام هذا الخيار الموضحة أدناه.
- يتم استخراج البيانات من السلسلة ويتم تدوين جميع الأحرف الخاصة التي تفصل النص.
على سبيل المثال ، في الشفرة الواردة أدناه ، يتم تحديد الأحرف الخاصة في السلسلة my_string ، وهي " و " و " : ". يجب أن تتم هذه العملية بعناية لتجنب الخطأ في تحليل النص x.
- يتم تقسيم النص في السلسلة بشكل فردي بناءً على القيم وموضع الأحرف الخاصة.
على سبيل المثال ، يتم تقسيم السلسلة إلى قيم بيانات نصية بناءً على الأحرف الخاصة المحددة باستخدام أمر الانقسام.
- تتم طباعة قيم بيانات السلسلة بمفردها كنص محلل. هنا ، يتم استخدام بيان الطباعة لطباعة قيمة البيانات المحللة للنص.
فيما يلي نموذج التعليمات البرمجية للعملية الموضحة أعلاه.
my_string = "الأسماء: التقنية ، الكمبيوتر"
sfinal = [name.strip () للاسم في my_string.split (':') [1] .split ('،')]
print ("الأسماء: {}". تنسيق (sfinal))في هذه الحالة ، سيتم عرض نتيجة السلسلة التي تم تحليلها كما هو موضح أدناه.
الأسماء: ['Tech'، 'computer']
للحصول على وضوح أفضل ومعرفة كيفية تحليل النص أثناء استخدام نص السلسلة ، يتم استخدام حلقة for ويتم تعديل الكود على النحو التالي.
my_string = "الأسماء: التقنية ، الكمبيوتر"
s1 = my_string.split (':')
s2 = s1 [1]
s3 = s2.split ('،')
s4 = [name.strip () للاسم في s3]
بالنسبة لمعرف الهوية ، العنصر في التعداد ([s1، s2، s3، s4]):
print ("الخطوة {}: {}". تنسيق (idx ، item)) 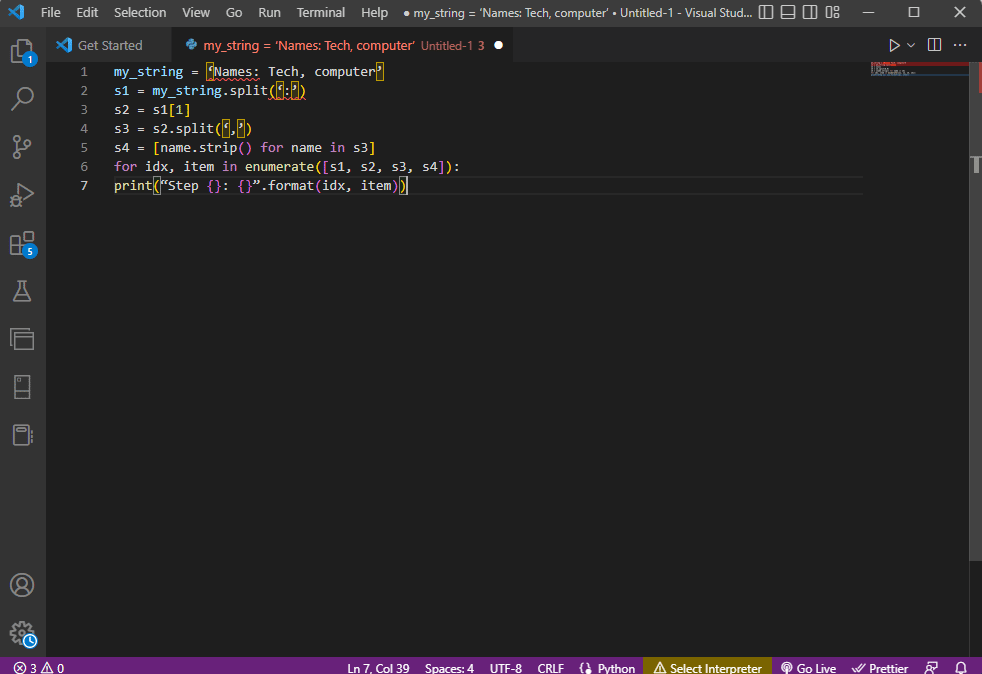
يتم عرض نتيجة النص الذي تم تحليله لكل خطوة من هذه الخطوات كما هو موضح أدناه. يمكنك ملاحظة أنه في الخطوة 0 ، يتم فصل السلسلة بناءً على الحرف الخاص : ويتم فصل قيم البيانات النصية بناءً على الحرف في خطوات أخرى.
الخطوة 0: ["الأسماء" ، "التكنولوجيا ، الكمبيوتر"] الخطوة 1: التكنولوجيا ، الكمبيوتر الخطوة الثانية: ["Tech"، "computer"] الخطوة الثالثة: ["Tech"، "computer"]
الخيار الثالث: تحليل ملف معقد
في معظم الحالات ، تحتوي بيانات الملف التي يجب تحليلها على أنواع بيانات وقيم بيانات مختلفة. في هذه الحالة ، قد يكون من الصعب تحليل الملف باستخدام الطرق الموضحة سابقًا.
تتمثل ميزات تحليل البيانات المعقدة في الملف في عرض قيم البيانات بتنسيق جدولي.
- تتم طباعة العنوان أو البيانات الوصفية للقيم في أعلى الملف ،
- تتم طباعة المتغيرات والحقول في الإخراج في شكل جدولي ، و
- تشكل قيم البيانات مفتاحا مركبا.
قبل الخوض في تعلم كيفية تحليل النص بهذه الطريقة ، من الضروري تعلم بعض المفاهيم الأساسية. يتم تحليل قيم البيانات بناءً على التعبيرات العادية أو Regex.
أنماط Regex
لمعرفة كيفية إصلاح خطأ التحليل ، عليك التأكد من أن أنماط regex في التعبيرات صحيحة. قد تتضمن التعليمات البرمجية لتحليل قيم البيانات للسلاسل أنماط Regex الشائعة المدرجة أدناه في هذا القسم.
- "\ d" : يطابق الرقم العشري في السلسلة ،
- "\ s" : يطابق حرف المسافة البيضاء ،
- "w" : يتطابق مع الحرف الأبجدي الرقمي ،
- "+" أو "*" : يؤدي مطابقة جشع من خلال مطابقة حرف واحد أو أكثر في السلاسل ،
- 'a-z' : تطابق المجموعات الصغيرة في قيم البيانات النصية ،
- "A-Z" أو "a-z": تطابق مجموعتي الأحرف الكبيرة والصغيرة من السلسلة ، و
- "0-9": يطابق القيم العددية.
التعبيرات العادية
تعد وحدات التعبير العادي جزءًا رئيسيًا من حزمة الباندا في لغة Python ويمكن أن تؤدي إعادة الخطأ إلى خطأ في تحليل النص x. إنها لغة صغيرة مضمنة داخل بايثون للعثور على نمط السلسلة في التعبير. التعبيرات العادية أو Regex هي سلاسل ذات بناء جملة خاص. يسمح للمستخدم بمطابقة الأنماط في سلاسل أخرى بناءً على القيم الموجودة في السلاسل.
يتم إنشاء Regex بناءً على نوع البيانات ومتطلبات التعبير في السلسلة ، مثل 'String = (. *) \ n . يتم استخدام regex قبل النمط في كل تعبير. الرموز المستخدمة في التعبيرات النمطية مذكورة أدناه وستساعد في معرفة كيفية تحليل النص.
- . : لاسترداد أي حرف من البيانات ،
- * : استخدم صفرًا أو أكثر من البيانات من التعبير السابق ،
- (. *) : لتجميع جزء من التعبير النمطي داخل الأقواس ،
- \ n : إنشاء حرف سطر جديد في نهاية السطر في التعليمات البرمجية ،
- \ d : إنشاء قيمة متكاملة قصيرة في النطاق من 0 إلى 9 ،
- + : استخدم بيانات واحدة أو أكثر من التعبير السابق ، و
- | : إنشاء بيان منطقي ؛ تستخدم للتعبيرات أو .
RegexObjects
RegexObject هو قيمة إرجاع لوظيفة الترجمة ويتم استخدامه لإرجاع كائن MatchObject إذا كان التعبير يطابق قيمة المطابقة.
1. MatchObject
نظرًا لأن القيمة المنطقية لـ MatchObject هي دائمًا True ، يمكنك استخدام عبارة if لتحديد التطابقات الإيجابية في الكائن. في حالة استخدام عبارة if ، يتم استخدام المجموعة المشار إليها بواسطة الفهرس لمعرفة تطابق الكائن في التعبير.
- تعيد المجموعة () مجموعة فرعية واحدة أو أكثر من المطابقة ،
- تعيد المجموعة (0) المباراة بأكملها ،
- تُرجع المجموعة (1) المجموعة الفرعية الأولى بين قوسين ، و
- أثناء الإشارة إلى مجموعات متعددة ، يجب أن نستخدم امتدادًا محددًا للبيثون. يستخدم هذا الامتداد لتحديد اسم المجموعة التي يجب العثور على التطابق فيها. يتم توفير الامتداد المحدد داخل المجموعة بين قوسين. على سبيل المثال ، قد يشير التعبير (؟ P <group1> regex1) إلى المجموعة المحددة بالاسم group1 والتحقق من المطابقة في التعبير العادي ، regex1 . لمعرفة كيفية إصلاح خطأ التحليل ، يجب عليك التحقق مما إذا كانت المجموعة موجهة بشكل صحيح.
2. طرق MatchObject
أثناء العثور على كيفية تحليل النص ، من المهم معرفة أن MatchObject له طريقتان أساسيتان كما هو موضح أدناه. إذا تم العثور على كائن MatchObject في التعبير المحدد ، فسيعيد مثيله ، وإلا فإنه سيعيد بلا.
- يتم استخدام طريقة match (سلسلة نصية) للعثور على تطابقات السلسلة في بداية التعبير النمطي ، و
- تُستخدم طريقة البحث (السلسلة) لمسح السلسلة للعثور على موقع تطابق في التعبير العادي.
وظائف التعبير العادي
وظائف Regex هي خطوط رمز يتم استخدامها لأداء وظيفة معينة كما هو محدد من قبل المستخدم من مجموعة قيم البيانات التي تم الحصول عليها.
ملاحظة: لكتابة الوظائف ، يتم استخدام السلاسل الأولية للتعبيرات العادية لتجنب الخطأ في تحليل النص x. يتم ذلك عن طريق إضافة الرمز r قبل كل نمط في التعبير.
يتم شرح الوظائف الشائعة المستخدمة في التعبيرات أدناه.
1. re.findall ()
تقوم هذه الوظيفة بإرجاع جميع الأنماط الموجودة في السلسلة إذا تم العثور على تطابق وإرجاع قائمة فارغة إذا لم يتم العثور على تطابق. على سبيل المثال ، يتم استخدام الوظيفة ، string = re.findall ('[aeiou]' ، regex_filename) للعثور على تواجد حرف العلة في اسم الملف.
2. re.split ()
تُستخدم هذه الوظيفة لتقسيم السلسلة في حالة وجود تطابق مع حرف محدد مثل وجود مسافة. في حالة عدم العثور على تطابق ، تقوم بإرجاع سلسلة فارغة.
3. re.sub ()
تستبدل الوظيفة النص المطابق بمحتويات متغير الاستبدال المحدد. على عكس الوظائف الأخرى ، إذا لم يتم العثور على نمط ، يتم إرجاع السلسلة الأصلية.

4. re.search ()
إحدى الوظائف الأساسية للمساعدة في تعلم كيفية تحليل النص هي وظيفة البحث. يساعد في البحث عن النمط في السلسلة وإرجاع كائن المطابقة. إذا فشل البحث في تحديد المطابقة ، فلن يتم إرجاع أي قيمة.
5. re.compile (نمط)
تُستخدم هذه الوظيفة لتجميع أنماط التعبير العادي في RegexObject ، والتي تمت مناقشتها سابقًا.
متطلبات اخرى
المتطلبات المذكورة هي ميزة إضافية يستخدمها المبرمجون المتقدمون في تحليل البيانات.
- لتصور التعبير العادي ، يتم استخدام regexper و
- لاختبار التعبير النمطي ، يتم استخدام regex101 .
اقرأ أيضًا: كيفية تثبيت NumPy على نظام التشغيل Windows 10
عملية الاعراب النص
يتم وصف طريقة تحليل النص في هذا الخيار المعقد كما هو موضح أدناه.
- الخطوة الأولى هي فهم تنسيق الإدخال من خلال قراءة محتوى الملف. على سبيل المثال ، يتم استخدام الدالتين with open and read () لفتح محتوى الملف المسمى sample وقراءته. يحتوي ملف العينة على محتويات من ملف file.txt ؛ لمعرفة كيفية إصلاح خطأ التحليل ، يجب قراءة الملف بالكامل.
- تتم طباعة محتويات الملف لتحليل البيانات يدويًا لمعرفة البيانات الأولية للقيم. هنا ، تُستخدم وظيفة print () لطباعة محتويات ملف العينة .
- يتم استيراد حزم البيانات المطلوبة لتحليل النص إلى الكود ويتم إعطاء اسم للفئة لمزيد من الترميز. هنا ، يتم استيراد التعبيرات العادية والباندا .
- يتم تعريف التعبيرات العادية المطلوبة للكود في الملف من خلال تضمين نمط regex ووظيفة regex. هذا يسمح لكائن النص أو المجموعة بأخذ الكود لتحليل البيانات.
- لمعرفة كيفية تحليل النص ، يمكنك الرجوع إلى رمز المثال الوارد هنا. يتم استخدام الدالة compile () لترجمة السلسلة من المجموعة stringname1 لاسم الملف . يتم استخدام وظيفة التحقق من التطابقات في regex بواسطة الأمر ief_parse_line (سطر) ،
- تتم كتابة المحلل اللغوي للسطر للرمز باستخدام def_parse_file (filepath) ، حيث تتحقق الوظيفة المحددة من جميع تطابقات regex في الوظيفة المحددة. هنا ، تبحث طريقة regex search () عن المفتاح rx في اسم الملف وتعيد المفتاح والمطابقة لأول regex مطابق. أي مشكلة في الخطوة يمكن أن تؤدي إلى خطأ في تحليل النص x.
- الخطوة التالية هي كتابة محلل ملف باستخدام وظيفة محلل الملف ، وهي def_parse_file (مسار الملف) . يتم إنشاء قائمة فارغة لجمع بيانات الكود ، مثل البيانات = [] ، ويتم التحقق من التطابق في كل سطر عن طريق المطابقة = _parse_line (سطر) ، ويتم إرجاع بيانات القيمة الدقيقة بناءً على نوع البيانات.
- لاستخراج رقم الجدول وقيمته ، يتم استخدام سطر الأوامر .strip (). split ('،') . يتم استخدام الأمر row {} لإنشاء قاموس بصف البيانات. يتم استخدام الأمر data.append (row) لفهم البيانات وتحليلها إلى تنسيق جدولي.
يتم استخدام الأمر data = pd.DataFrame (data) لإنشاء pandas DataFrame من قيم الدكت. بدلاً من ذلك ، يمكنك استخدام الأوامر التالية للغرض المعني كما هو مذكور أدناه.
- data.set_index (['string'، 'integer']، inplace = True) لتعيين فهرس الجدول.
- data = data.groupby (level = data.index.names) .first () لتوحيد وإزالة nans.
- data = data.apply (pd.to_numeric، errors = "ignore") لترقية الدرجة من عدد صحيح إلى عدد صحيح.
الخطوة الأخيرة لمعرفة كيفية تحليل النص هي اختبار المحلل اللغوي باستخدام عبارة if عن طريق تعيين القيم إلى بيانات متغيرة وطباعتها باستخدام الأمر print (data) .
يتم تقديم رمز المثال للتفسير أعلاه هنا.
مع فتح ("file.txt") كنموذج:
sample_contents = sample.read ()
طباعة (عينة_محتويات)
إعادة الاستيراد
استيراد الباندا كما pd
rx_filename = {
'string1': re.compile (r 'string = (؟ <P <stringname1>، *) \ n')،
}
ief_parse_line (سطر):
للمفتاح ، rx في rx_filename.items ():
مباراة = rx.search (سطر)
إذا تطابق:
مفتاح العودة ، المباراة
العودة لا شيء ، لا شيء
def parse_file (filepath):
البيانات = []
مع open (filepath، 'r') كـ file_object:
line = file_object.readline ()
بينما الخط:
مفتاح ، تطابق = _parse_line (خط)
إذا كان المفتاح == 'string1':
string = match.group ('string1')
عدد صحيح = int (سلسلة 1)
value_type = match.group ('string1')
line = file_object.readline ()
بينما line.strip ():
number، value = line.strip (). split ('،')
القيمة = value.strip ()
صف = {
"البيانات 1": سلسلة 1 ،
"البيانات 2": رقم ،
value_type: القيمة
}
data.append (صف)
line = file_object.readline ()
line = file_object.readline ()
data = pd.DataFrame (بيانات)
إعادة البيانات
إذا _ _name_ _ = = '_ _main_ _':
filepath = 'sample.txt'
البيانات = تحليل (مسار الملف)
طباعة (بيانات) 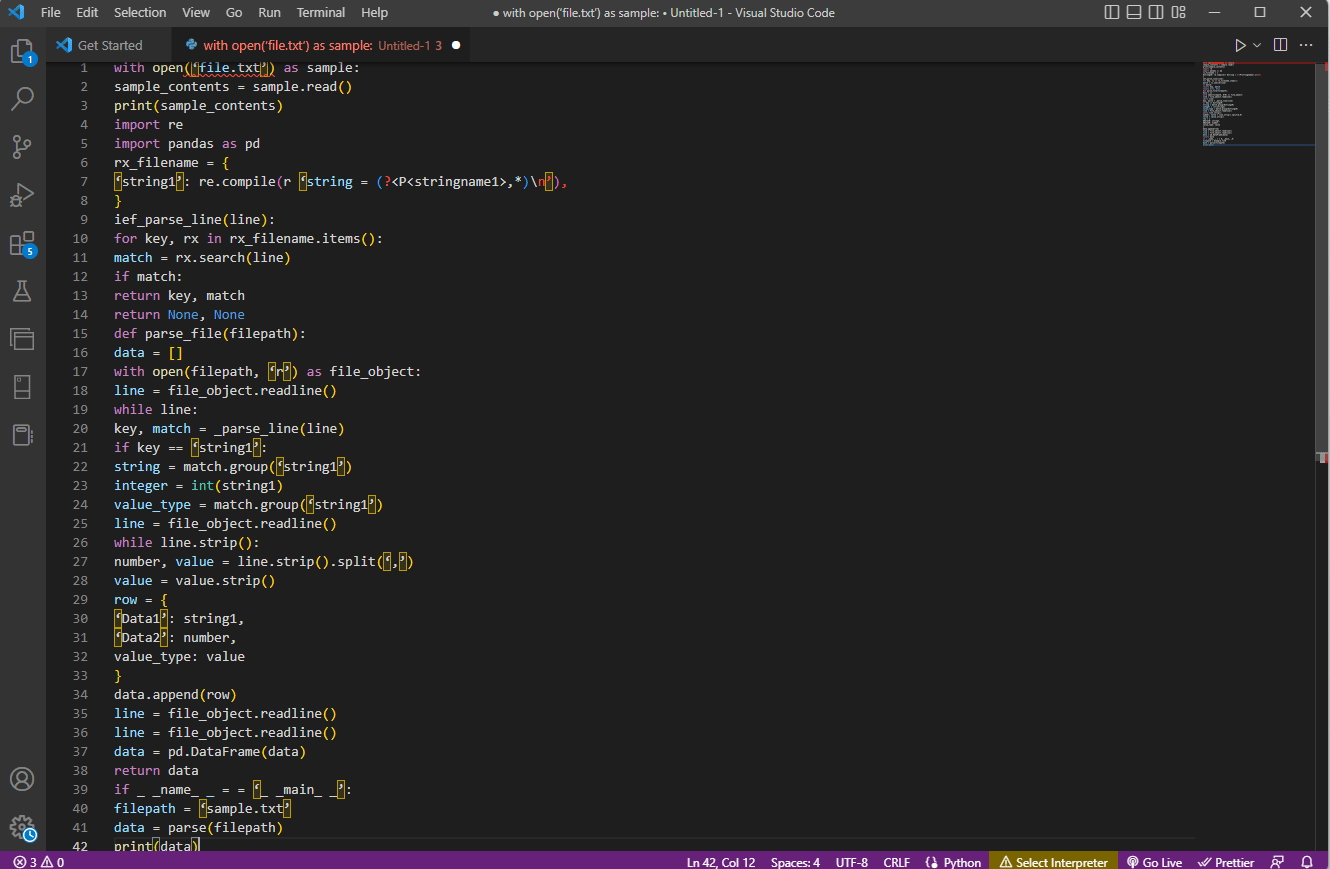
الطريقة الثانية: من خلال كلمة رمزية
تسمى عملية تحويل نص أو مجموعة إلى رموز أو أجزاء أصغر بناءً على قواعد معينة عملية التحويل إلى الرموز. لمعرفة كيفية إصلاح خطأ التحليل ، من المهم تحليل أوامر الرموز المميزة للكلمة في الكود. على غرار regex ، يمكن إنشاء القواعد الخاصة بهذه الطريقة وتساعد في مهام المعالجة المسبقة للنص مثل تعيين أجزاء من الكلام. أيضًا ، يتم تنفيذ أنشطة مثل البحث عن الكلمات الشائعة ومطابقتها وتنظيف النص وتجهيز البيانات لتقنيات تحليل النص المتقدمة مثل تحليل المشاعر في هذه الطريقة. إذا كان الرمز المميز غير صحيح ، فقد يحدث خطأ في تحليل النص x.
مكتبة نتلك
تستفيد العملية من مكتبة مجموعة أدوات اللغة الشهيرة المسماة nltk ، والتي تحتوي على مجموعة غنية من الوظائف لأداء العديد من وظائف البرمجة اللغوية العصبية. يمكن تنزيلها من خلال حزم تثبيت Pip أو Pip. لمعرفة كيفية تحليل النص ، يمكنك استخدام الحزمة الأساسية لتوزيع Anaconda والتي تتضمن المكتبة بشكل افتراضي.
أشكال الترميز
الأشكال الشائعة لهذه الطريقة هي ترميز الكلمات وترميز الجملة. بسبب الرمز المميز على مستوى الكلمة ، يطبع الأول كلمة واحدة مرة واحدة فقط ، بينما يطبع الأخير الكلمة على مستوى الجملة.
عملية الاعراب النص
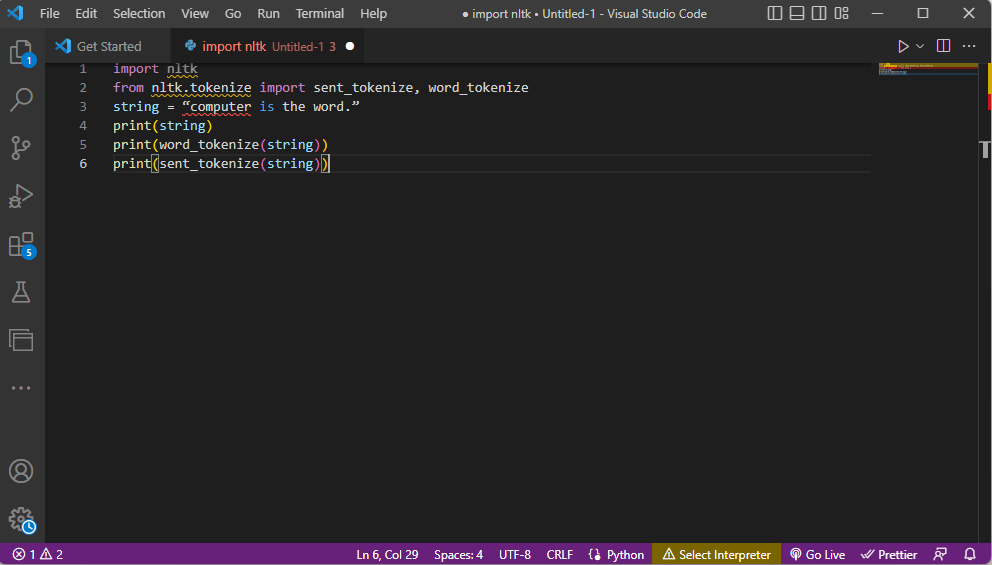
- يتم استيراد مكتبة مجموعة أدوات ntlk ويتم استيراد نماذج الرموز المميزة من المكتبة.
- يتم إعطاء سلسلة وأوامر تنفيذ الرمز المميز.
- أثناء طباعة السلسلة ، سيكون الناتج الكمبيوتر هو الكلمة.
- في حالة ترميز الكلمة أو word_tokenize () ، تتم طباعة كل كلمة في الجملة بشكل فردي داخل "" ويتم الفصل بينها بفاصلة . سيكون إخراج الأمر هو "الكمبيوتر" ، "هو" ، "الكلمة" ، "."
- في حالة ترميز الجملة أو sent_tokenize () ، يتم وضع الجمل الفردية داخل "" ويسمح بتكرار الكلمة. سيكون ناتج الأمر "الكمبيوتر هو الكلمة".
الكود الذي يشرح خطوات الترميز أعلاه مُعطى هنا.
استيراد nltk من nltk.tokenize استيراد sent_tokenize ، word_tokenize string = "الكمبيوتر هو الكلمة." طباعة (سلسلة) طباعة (word_tokenize (سلسلة نصية)) طباعة (sent_tokenize (سلسلة))
اقرأ أيضًا: كيفية إصلاح جافا سكريبت: باطل (0) خطأ
الطريقة الثالثة: من خلال فئة DocParser
على غرار فئة DataFrame ، يمكن استخدام Class DocParser لتحليل النص في الكود. يسمح لك الفصل باستدعاء وظيفة التحليل باستخدام مسار الملف.
عملية الاعراب النص
لمعرفة كيفية تحليل النص باستخدام فئة DocParser ، اتبع الإرشادات الواردة أدناه.
- تُستخدم وظيفة get_format (اسم الملف) لاستخراج امتداد الملف ، وإعادته إلى متغير معين للوظيفة ، وتمريره إلى الوظيفة التالية. على سبيل المثال ، p1 = get_format (اسم الملف) سيستخرج امتداد الملف الخاص باسم الملف ، ويضبطه على المتغير p1 ، ويمرره إلى الوظيفة التالية.
- يتم إنشاء بنية منطقية مع وظائف أخرى باستخدام عبارات ووظائف if-elif-else .
- إذا كان امتداد الملف صالحًا وكانت البنية منطقية ، يتم استخدام دالة get_parser لتحليل البيانات في مسار الملف وإرجاع كائن السلسلة إلى المستخدم.
ملاحظة: لمعرفة كيفية إصلاح خطأ التحليل ، يجب تنفيذ هذه الوظيفة بشكل صحيح.
- يتم تحليل قيم البيانات بامتداد الملف الخاص بالملف. يتم استخدام التنفيذ الملموس للفئة ، والتي هي parse_txt أو parse_docx ، لتوليد كائنات سلسلة من أجزاء من نوع الملف المحدد.
- يمكن إجراء التحليل للملفات ذات الامتدادات الأخرى القابلة للقراءة مثل parse_pdf و parse_html و parse_pptx .
- يمكن استيراد قيم البيانات والواجهة إلى التطبيقات باستخدام عبارات الاستيراد وإنشاء كائن DocParser. يمكن القيام بذلك عن طريق تحليل الملفات بلغة Python ، مثل parse_file.py . يجب إجراء هذه العملية بعناية لتجنب الخطأ في تحليل النص x.
الطريقة الرابعة: من خلال أداة تحليل النص
تُستخدم أداة تحليل النص لاستخراج بيانات محددة من المتغيرات وتعيينها إلى متغيرات أخرى. هذا مستقل عن أي أدوات أخرى مستخدمة في مهمة ما ويتم استخدام أداة BPA Platform لاستهلاك المتغيرات وإخراجها. استخدم الرابط الموضح هنا للوصول إلى أداة تحليل النص عبر الإنترنت واستخدم الإجابات المقدمة مسبقًا حول كيفية تحليل النص.
الطريقة الخامسة: من خلال TextFieldParser (Visual Basic)
استخدم TextFieldParser الكائنات لتحليل ومعالجة الملفات الكبيرة جدًا التي تم هيكلتها ومحددة. يمكن استخدام عرض وعمود النص مثل ملفات السجل أو معلومات قاعدة البيانات القديمة في هذه الطريقة. تشبه طريقة التحليل تكرار الكود فوق ملف نصي وتستخدم بشكل أساسي لاستخراج حقول نصية مشابهة لطرق معالجة السلاسل. يتم إجراء ذلك لترميز السلاسل والحقول المحددة ذات العروض المختلفة باستخدام المحدد المحدد مثل الفاصلة أو مسافة الجدولة.
وظائف تحليل النص
يمكن استخدام الوظائف التالية لتحليل النص في هذه الطريقة.
- لتحديد محدد ، يتم استخدام SetDelimiters . على سبيل المثال ، يتم استخدام الأمر testReader.SetDelimiters (vbTab) لتعيين مسافة الجدولة كمحدد.
- لتعيين عرض حقل إلى قيمة عدد صحيح موجب إلى عرض حقل ثابت للملفات النصية ، يمكنك استخدام الأمر testReader.SetFieldWidths (عدد صحيح) .
- لاختبار نوع حقل النص ، يمكنك استخدام الأمر التالي testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth .
طرق البحث عن MatchObject
هناك طريقتان أساسيتان للعثور على كائن MatchObject في الكود أو النص الذي تم تحليله.
- الطريقة الأولى هي تحديد التنسيق والتكرار خلال الملف باستخدام طريقة ReadFields . ستساعد هذه الطريقة في معالجة كل سطر من الكود.
- يتم استخدام طريقة PeekChars للتحقق من كل حقل على حدة قبل قراءته ، وتحديد تنسيقات متعددة ، والتفاعل.
في كلتا الحالتين ، إذا كان الحقل لا يتطابق مع التنسيق المحدد أثناء إجراء التحليل أو البحث عن كيفية تحليل النص ، يتم إرجاع استثناء MalformedLineException .
نصيحة للمحترفين: كيفية تحليل النص من خلال MS Excel
كطريقة نهائية وبسيطة لتحليل النص ، يمكنك استخدام تطبيق MS Excel كمحلل لإنشاء ملفات محددة بعلامات جدولة وفاصلة. سيساعد هذا في التحقق من النتيجة التي تم تحليلها ويساعد في العثور على كيفية إصلاح خطأ التحليل.
1. حدد قيم البيانات في الملف المصدر واضغط على مفتاحي Ctrl + C معًا لنسخ الملف.
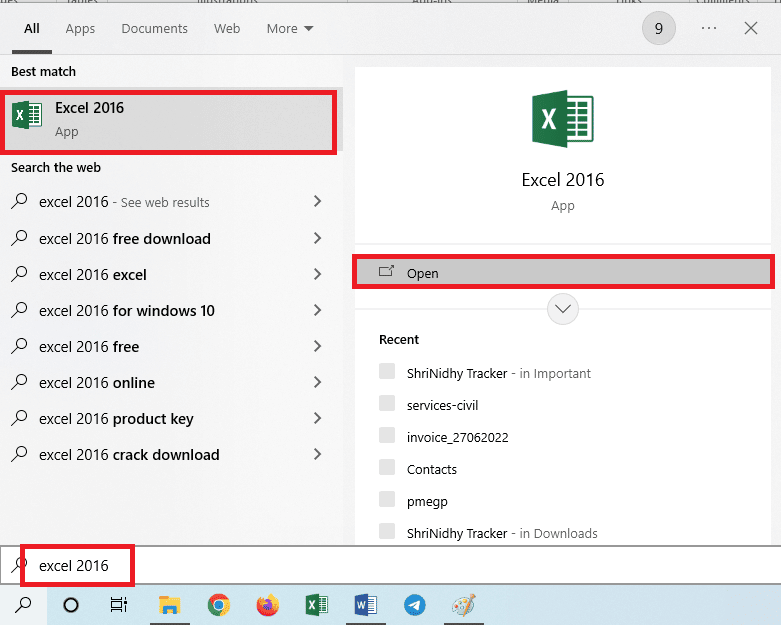
2. افتح تطبيق Excel باستخدام شريط بحث windows.
3. انقر فوق الخلية A1 واضغط على مفتاحي Ctrl + V في نفس الوقت للصق النص المنسوخ.
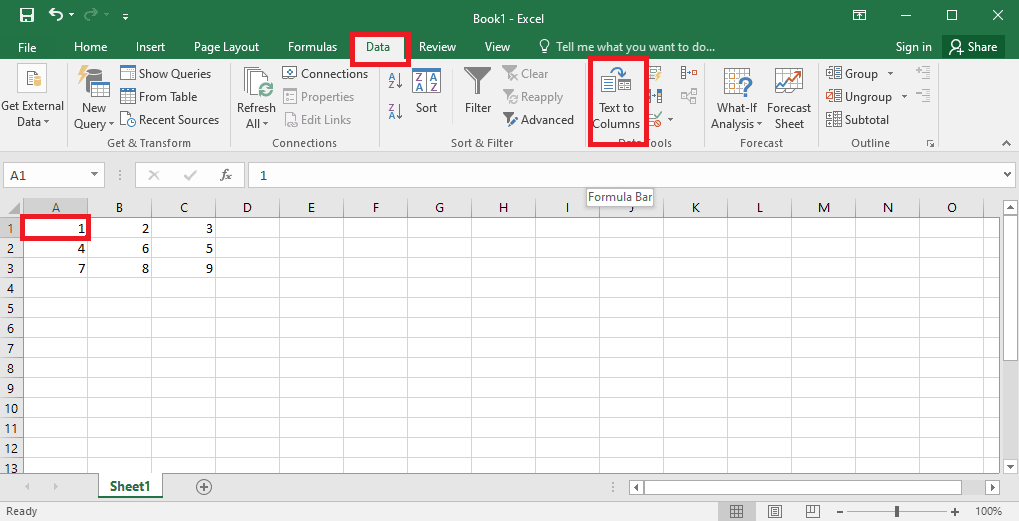
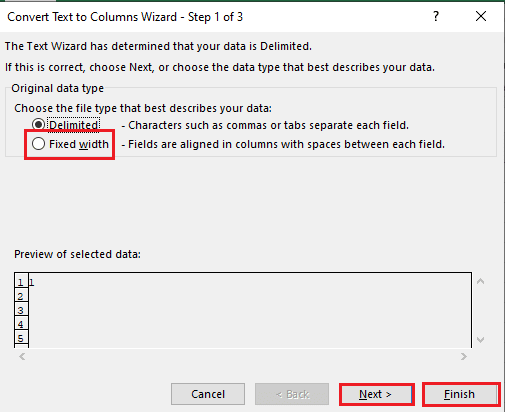
4. حدد الخلية A1 ، وانتقل إلى علامة التبويب البيانات ، وانقر على خيار تحويل النص إلى أعمدة في قسم أدوات البيانات .
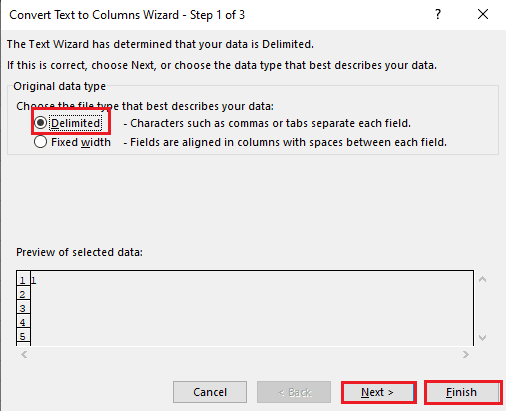
5 أ. حدد الخيار المحدد إذا تم استخدام فاصلة أو مسافة علامة التبويب كفاصل ، وانقر فوق الزرين التالي والإنهاء .
5 ب. حدد خيار العرض الثابت ، وقم بتعيين قيمة للفاصل ، وانقر فوق الزرين التالي والانتهاء .
اقرأ أيضًا: كيفية إصلاح خطأ نقل عمود Excel
كيفية إصلاح خطأ التحليل
قد يحدث خطأ في تحليل النص x على أجهزة Android مثل ، خطأ في التحليل: حدثت مشكلة في تحليل الحزمة. يحدث هذا عادةً عندما يفشل التطبيق في التثبيت من متجر Google Play أو أثناء تشغيل تطبيق تابع لجهة خارجية.
قد يحدث نص الخطأ x إذا تم تكرار قائمة متجهات الأحرف وتشكل الوظائف الأخرى نموذجًا خطيًا لحساب قيم البيانات. رسالة الخطأ هي خطأ في التحليل (النص = x ، keep.source = FALSE): <text>: 2.0: نهاية غير متوقعة للإدخال 1: OffenceAgainst ~ ^.
يمكنك قراءة المقالة حول كيفية إصلاح خطأ التحليل على Android لمعرفة أسباب وطرق إصلاح الخطأ.
بصرف النظر عن الحلول الواردة في الدليل ، يمكنك تجربة الإصلاحات التالية.
- إعادة تنزيل ملف apk. أو استعادة اسم الملف.
- استعادة التغييرات في ملف Androidmanifest.xml ، إذا كانت لديك مهارات برمجة على مستوى الخبراء.
مُستَحسَن:
- كيفية حذف حساب Facebook لشخص آخر
- أهم 10 مهارات مطلوبة لتصبح هاكرًا أخلاقيًا
- 21 من أفضل بدائل Pastebin لمشاركة الرمز والنص
- إصلاح فشل الأمر مع رمز الخطأ 1 Python Egg Info
تساعد المقالة في تعليم كيفية تحليل النص وتعلم كيفية إصلاح خطأ التحليل. دعنا نعرف الطريقة التي ساعدت في إصلاح الخطأ في تحليل النص x وأي طريقة مفضلة للتحليل. يرجى مشاركة اقتراحاتك واستفساراتك في قسم التعليقات أدناه.