
كيفية القيام بالتعرّف البصري على الأحرف (OCR) من سطر أوامر Linux باستخدام Tesseract
نشرت: 2022-01-29
يمكنك استخراج نص من الصور على سطر أوامر Linux باستخدام محرك Tesseract OCR. إنه سريع ودقيق ويعمل في حوالي 100 لغة. إليك كيفية استخدامه.
التعرف الضوئي على الحروف
التعرف البصري على الأحرف (OCR) هو القدرة على النظر إلى الكلمات والعثور عليها في صورة ما ، ثم استخراجها كنص قابل للتحرير. هذه المهمة البسيطة للبشر من الصعب جدًا على أجهزة الكمبيوتر القيام بها. كانت الجهود المبكرة ثقيلة ، على أقل تقدير. غالبًا ما يتم الخلط بين أجهزة الكمبيوتر إذا كان المحرف أو الحجم لا يرضي برنامج OCR.
ومع ذلك ، لا يزال الرواد في هذا المجال يحظى بتقدير كبير. إذا فقدت النسخة الإلكترونية من المستند ، ولكن لا تزال لديك نسخة مطبوعة ، فيمكن لـ OCR إعادة إنشاء نسخة إلكترونية قابلة للتحرير. حتى لو لم تكن النتائج دقيقة بنسبة 100٪ ، فإن هذا لا يزال يوفر الكثير من الوقت.
مع بعض التنظيم اليدوي ، يمكنك استعادة المستند الخاص بك. كان الناس يتسامحون مع الأخطاء التي ارتكبها لأنهم فهموا مدى تعقيد المهمة التي تواجه حزمة التعرف الضوئي على الحروف. بالإضافة إلى ذلك ، كان أفضل من إعادة كتابة المستند بأكمله.
تحسنت الأمور بشكل ملحوظ منذ ذلك الحين. بدأ تطبيق Tesseract OCR ، الذي كتبته شركة Hewlett Packard ، في الثمانينيات كتطبيق تجاري. كان مفتوح المصدر في عام 2005 ، وهو الآن مدعوم من قبل Google. يتمتع بقدرات متعددة اللغات ، ويعتبر أحد أكثر أنظمة OCR المتوفرة دقة ، ويمكنك استخدامه مجانًا.
تثبيت Tesseract OCR
لتثبيت Tesseract OCR على Ubuntu ، استخدم هذا الأمر:
sudo apt-get install tesseract-ocr

في Fedora ، يكون الأمر:
sudo dnf تثبيت tesseract

في Manjaro ، تحتاج إلى كتابة:
sudo pacman -Syu tesseract

باستخدام Tesseract OCR
سنقوم بفرض مجموعة من التحديات على Tesseract OCR. صورتنا الأولى التي تحتوي على نص هي مقتطف من Recital 63 من اللوائح العامة لحماية البيانات. دعونا نرى ما إذا كان بإمكان OCR قراءة هذا (والبقاء مستيقظًا).

إنها صورة صعبة لأن كل جملة تبدأ برقم مرتفع خافت ، وهو أمر معتاد في الوثائق التشريعية.
نحتاج إلى إعطاء الأمر tesseract بعض المعلومات ، بما في ذلك:
- اسم ملف الصورة الذي نريده أن يعالج.
- اسم الملف النصي الذي سينشئه ليحتوي على النص المستخرج. لا يتعين علينا توفير امتداد الملف (سيكون دائمًا .txt). إذا كان هناك ملف موجود بالفعل بنفس الاسم ، فسيتم استبداله.
- يمكننا استخدام الخيار
--dpitesseractفي البوصة (dpi) للصورة. إذا لم نقدم قيمة نقطة في البوصة ،tesseract.
تم تسمية ملف صورتنا "recital-63.png" ، ودقتها 150 نقطة في البوصة. سننشئ ملفًا نصيًا منه يسمى "recital.txt".
يبدو أمرنا كما يلي:
tesseract recital-63.png ريسيتال - DPI 150

النتائج جيدة جدا. المشكلة الوحيدة هي الأحرف المرتفعة - كانت باهتة جدًا بحيث لا يمكن قراءتها بشكل صحيح. الصورة الجيدة هي أمر حيوي للحصول على نتائج جيدة.

فسرت tesseract الأرقام المرتفعة على أنها علامات اقتباس (") ورموز درجة (°) ، ولكن تم استخراج النص الفعلي تمامًا (يجب قطع الجانب الأيمن من الصورة ليلائم هنا).
الحرف الأخير عبارة عن بايت بقيمة سداسية عشرية تبلغ 0x0C ، وهي عبارة عن حرف إرجاع.
يوجد أدناه صورة أخرى بنص بأحجام مختلفة ، وكلاهما غامق ومائل.

اسم هذا الملف هو "bold-italic.png." نريد إنشاء ملف نصي يسمى “bold.txt” ، لذا فإن أمرنا هو:
tesseract bold-italic.png غامق - DPI 150

هذا لم يطرح أي مشاكل ، وتم استخراج النص بشكل مثالي.

استخدام لغات مختلفة
يدعم Tesseract OCR حوالي 100 لغة. لاستخدام لغة ، يجب عليك أولاً تثبيتها. عندما تجد اللغة التي تريد استخدامها في القائمة ، لاحظ اختصارها. سنقوم بتثبيت الدعم للويلزية. اختصارها هو "cym" وهي اختصار لـ "Cymru" والتي تعني الويلزية.
تسمى حزمة التثبيت "tesseract-ocr-" مع تمييز اختصار اللغة في النهاية. لتثبيت ملف اللغة الويلزية في أوبونتو ، سنستخدم:
سودو apt-get install tesseract-ocr-cym


الصورة مع النص أدناه. إنها أول بيت من النشيد الوطني الويلزي.

دعونا نرى ما إذا كان Tesseract OCR على مستوى التحدي. سنستخدم الخيار -l (اللغة) للسماح لـ tesseract بمعرفة اللغة التي نريد العمل بها:
tesseract hen-wlad-fy-nhadau.png anthem -l cym --dpi 150

تتكيف tesseract تمامًا ، كما هو موضح في النص المستخرج أدناه. Da iawn ، Tesseract OCR.

إذا كان المستند يحتوي على لغتين أو أكثر (مثل القاموس الويلزي إلى الإنجليزية ، على سبيل المثال) ، فيمكنك استخدام علامة الجمع ( + ) لإخبار tesseract بإضافة لغة أخرى ، مثل:
tesseract image.png textfile -l eng + cym + fra
استخدام Tesseract OCR مع ملفات PDF
تم تصميم الأمر tesseract للعمل مع ملفات الصور ، لكنه غير قادر على قراءة ملفات PDF. ومع ذلك ، إذا كنت بحاجة إلى استخراج نص من ملف PDF ، فيمكنك استخدام أداة مساعدة أخرى أولاً لإنشاء مجموعة من الصور. ستمثل صورة واحدة صفحة واحدة من ملف PDF.
يجب أن تكون الأداة المساعدة pdftppm التي تحتاجها مثبتة بالفعل على كمبيوتر Linux الخاص بك. ملف PDF الذي سنستخدمه كمثال لدينا هو نسخة من ورقة ألان تورينج الأساسية حول الذكاء الاصطناعي ، "ماكينات الحوسبة والذكاء".

نستخدم الخيار -png لتحديد رغبتنا في إنشاء ملفات PNG. اسم ملف PDF الخاص بنا هو "turing.pdf". سنطلق على ملفات الصور الخاصة بنا "turing-01.png" و "turing-02.png" وما إلى ذلك:
pdftoppm -png turing.pdf turing

لتشغيل tesseract على كل ملف صورة باستخدام أمر واحد ، نحتاج إلى استخدام حلقة for. لكل ملف من ملفاتنا "turing- nn .png" ، نقوم بتشغيل tesseract ، وننشئ ملفًا نصيًا يسمى "text-" بالإضافة إلى "turing- nn " كجزء من اسم ملف الصورة:
لأني في تورينج - ؟؟. png ؛ عمل نص tesseract "$ i" "- $ i "-l eng؛ فعله؛

لدمج جميع الملفات النصية في ملف واحد ، يمكننا استخدام cat :
cat text-turing *> complete.txt

فكيف فعلت ذلك؟ جيد جدا ، كما ترون أدناه. بالرغم من ذلك ، تبدو الصفحة الأولى صعبة للغاية. لها أنماط وأحجام نصية مختلفة ، وزخرفة. توجد أيضًا "علامة مائية" عمودية على الحافة اليمنى من الصفحة.
ومع ذلك ، فإن الإخراج قريب من الأصل. من الواضح أن التنسيق قد فقد ، لكن النص صحيح.
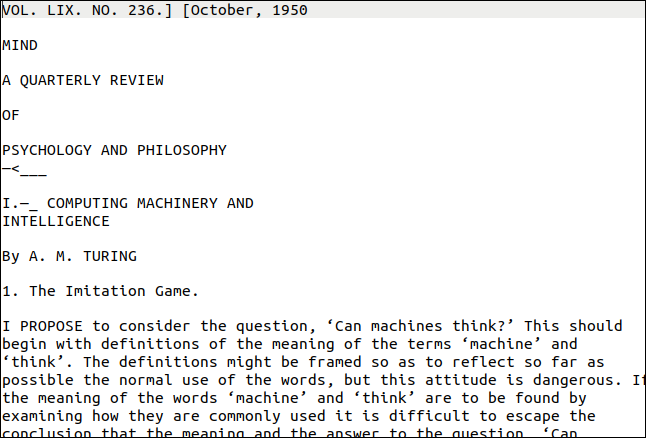
تم نسخ العلامة المائية العمودية على أنها سطر من رطانة في أسفل الصفحة. كان النص صغيرًا جدًا بحيث لا يمكن قراءته بدقة بواسطة tesseract ، ولكن سيكون من السهل العثور عليه وحذفه. كانت النتيجة الأسوأ هي الأحرف الضالة في نهاية كل سطر.
من الغريب أنه تم تجاهل الأحرف المفردة في بداية قائمة الأسئلة والأجوبة في الصفحة الثانية. يظهر المقطع من ملف PDF أدناه.

كما ترى أدناه ، تظل الأسئلة قائمة ، ولكن تم فقد "Q" و "A" في بداية كل سطر.

كما لن يتم نسخ المخططات بشكل صحيح. لنلقِ نظرة على ما يحدث عندما نحاول استخراج ما هو موضح أدناه من Turing PDF.

كما ترى في النتيجة أدناه ، تمت قراءة الأحرف ، لكن تنسيق الرسم التخطيطي فقد.

مرة أخرى ، كافحت tesseract مع الحجم الصغير للمخطوطات ، وتم تقديمها بشكل غير صحيح.
لكن في الإنصاف ، كانت لا تزال نتيجة جيدة. لم نتمكن من استخراج نص مباشر ، ولكن بعد ذلك ، تم اختيار هذا المثال عن عمد لأنه يمثل تحديًا.
حل جيد عندما تحتاجه
OCR ليس شيئًا ستحتاج إلى استخدامه يوميًا. ومع ذلك ، عند الحاجة ، من الجيد أن تعرف أن لديك أحد أفضل محركات التعرف الضوئي على الحروف تحت تصرفك.